Пару месяцев назад мне нужно было создать динамический документ Word с несколькими таблицами и абзацами. В прошлом я использовал POI для этого, но мне было трудно это использовать, и он не очень хорошо работает при создании более сложных документов. Так что для этого проекта, после некоторых поисков, я решил использовать docx4j . Docx4j, в соответствии с их сайтом является:
«Docx4j — это библиотека Java для создания и управления файлами Microsoft Open XML (Word docx, Powerpoint pptx и Excel xlsx).
Это похоже на Microsoft OpenXML SDK, но для Java. »
В этой статье я покажу вам пару примеров, которые вы можете использовать для создания контента для текстовых документов. Более конкретно мы рассмотрим следующие два примера:
- Загрузите шаблон документа Word, чтобы добавить содержимое и сохранить как новый документ.
- Добавить абзацы в этот шаблон документа
- Добавить таблицы в этот шаблон документа
Общий подход заключается в том, чтобы сначала создать документ Word, который содержит макет и основные стили вашего окончательного документа. В этом документе вам необходимо добавить заполнители (простые строки), которые мы будем использовать для поиска и замены реальным контентом.
Например, очень простой шаблон выглядит так:
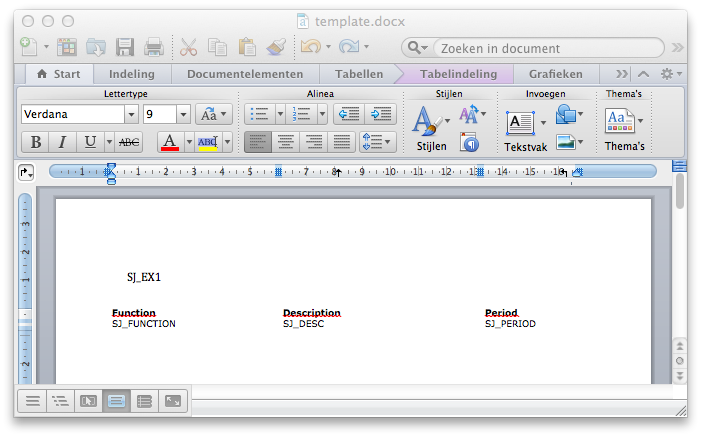
В этой статье мы покажем вам, как вы можете заполнить это, чтобы получить это:
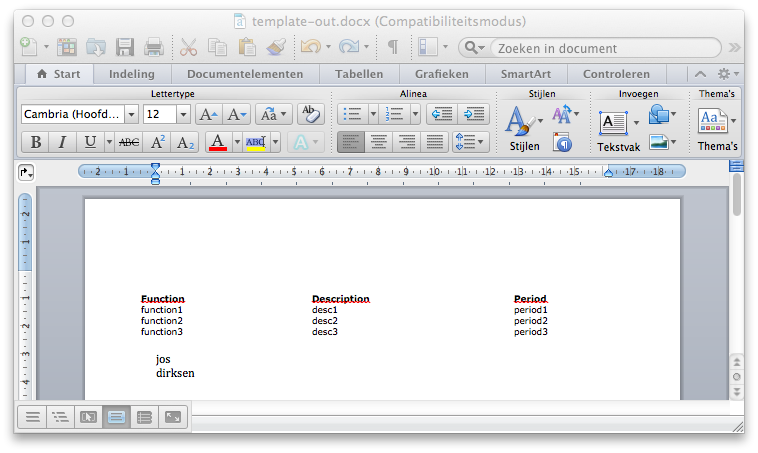
Загрузите шаблон документа Word, чтобы добавить содержимое и сохранить как новый документ.
Обо всем по порядку. Давайте создадим простой текстовый документ, который мы можем использовать в качестве шаблона. Для этого просто откройте Word, создайте новый документ и сохраните его как template.docx. Это слово шаблон, который мы будем использовать для добавления контента. Первое, что нам нужно сделать, это загрузить этот документ с помощью docx4j. Вы можете сделать это с помощью следующего фрагмента кода Java:
|
1
2
3
4
|
private WordprocessingMLPackage getTemplate(String name) throws Docx4JException, FileNotFoundException { WordprocessingMLPackage template = WordprocessingMLPackage.load(new FileInputStream(new File(name))); return template; } |
Это вернет объект Java, представляющий полный (на данный момент) пустой документ. Теперь мы можем использовать API Docx4J для добавления, удаления и изменения содержимого в этом текстовом документе. Docx4J имеет несколько вспомогательных классов, которые вы можете использовать для просмотра этого документа. Я сам написал пару помощников, которые позволяют легко найти конкретные заполнители и заменить их реальным контентом. Давайте посмотрим на одного из них. Эта операция является оберткой вокруг пары операций JAXB, которая позволяет вам искать через определенный элемент и все его дочерние элементы для определенного класса. Например, вы можете использовать это, чтобы получить все таблицы в документе, все строки в таблице и многое другое.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
private static List<Object> getAllElementFromObject(Object obj, Class<?> toSearch) { List<Object> result = new ArrayList<Object>(); if (obj instanceof JAXBElement) obj = ((JAXBElement<?>) obj).getValue(); if (obj.getClass().equals(toSearch)) result.add(obj); else if (obj instanceof ContentAccessor) { List<?> children = ((ContentAccessor) obj).getContent(); for (Object child : children) { result.addAll(getAllElementFromObject(child, toSearch)); } } return result; } |
Ничего сложного, но действительно полезно. Давайте посмотрим, как мы можем использовать эту операцию. В этом примере мы просто заменим простой текстовый заполнитель другим значением. Это, например, то, что вы будете использовать для динамической установки заголовка документа. Сначала добавьте пользовательский заполнитель в созданный вами шаблон слова. Я буду использовать SJ_EX1 для этого. Мы заменим это значение на наше имя. Основные текстовые элементы в docx4j представлены классом org.docx4j.wml.Text. Чтобы заменить этот простой заполнитель, все что нам нужно сделать, это вызвать этот метод:
|
01
02
03
04
05
06
07
08
09
10
|
private void replacePlaceholder(WordprocessingMLPackage template, String name, String placeholder ) { List<Object> texts = getAllElementFromObject(template.getMainDocumentPart(), Text.class); for (Object text : texts) { Text textElement = (Text) text; if (textElement.getValue().equals(placeholder)) { textElement.setValue(name); } } } |
Это будет искать все элементы текста в документе, и те, которые соответствуют, заменяются на значение, которое мы указываем. Теперь все, что нам нужно сделать, это записать документ обратно в файл.
|
1
2
3
4
|
private void writeDocxToStream(WordprocessingMLPackage template, String target) throws IOException, Docx4JException { File f = new File(target); template.save(f);} |
Не так сложно, как вы можете видеть.
С помощью этой настройки мы также можем добавить более сложный контент в наши текстовые документы. Самый простой способ определить, как добавить конкретный контент, — просмотреть исходный код XML документа word. Это скажет вам, какие оболочки нужны и как Word маршаллизирует XML. В следующем примере мы рассмотрим, как добавить полный абзац.
Добавить абзацы в этот шаблон документа
Вы можете спросить, зачем нам нужно добавлять абзацы? Мы уже можем добавить текст, и не является ли абзац просто большим фрагментом текста? Ну да и нет. Абзац действительно выглядит как большой кусок текста, но вам нужно принять во внимание разрывы строк. Если вы добавите элемент «Текст», как мы делали ранее, и добавите в текст разрывы строк, они не будут отображаться. Когда вы хотите разрывы строк, вам нужно создать новый абзац. К счастью, с Docx4j это также очень легко сделать.
Мы сделаем это, выполнив следующие шаги:
- Найти абзац для замены из шаблона
- Разбить входной текст на отдельные строки
- Для каждой строки создайте новый абзац на основе абзаца из шаблона
- Удалить оригинальный абзац
Не должно быть слишком сложно с вспомогательными методами, которые у нас уже есть.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
private void replaceParagraph(String placeholder, String textToAdd, WordprocessingMLPackage template, ContentAccessor addTo) { // 1. get the paragraph List<Object> paragraphs = getAllElementFromObject(template.getMainDocumentPart(), P.class); P toReplace = null; for (Object p : paragraphs) { List<Object> texts = getAllElementFromObject(p, Text.class); for (Object t : texts) { Text content = (Text) t; if (content.getValue().equals(placeholder)) { toReplace = (P) p; break; } } } // we now have the paragraph that contains our placeholder: toReplace // 2. split into seperate lines String as[] = StringUtils.splitPreserveAllTokens(textToAdd, '\n'); for (int i = 0; i < as.length; i++) { String ptext = as[i]; // 3. copy the found paragraph to keep styling correct P copy = (P) XmlUtils.deepCopy(toReplace); // replace the text elements from the copy List texts = getAllElementFromObject(copy, Text.class); if (texts.size() > 0) { Text textToReplace = (Text) texts.get(0); textToReplace.setValue(ptext); } // add the paragraph to the document addTo.getContent().add(copy); } // 4. remove the original one ((ContentAccessor)toReplace.getParent()).getContent().remove(toReplace);} |
В этом методе мы заменяем содержимое абзаца предоставленным текстом, а затем добавляем новые абзацы к аргументу, указанному в addTo.
|
1
2
3
4
|
String placeholder = "SJ_EX1"; String toAdd = "jos\ndirksen"; replaceParagraph(placeholder, toAdd, template, template.getMainDocumentPart()); |
Если вы запустите это с большим количеством контента в вашем шаблоне слов, вы заметите, что абзацы появятся внизу вашего документа. Причина в том, что абзацы добавляются обратно в основной документ. Если вы хотите, чтобы ваши абзацы добавлялись в определенное место в вашем документе (что обычно требуется), вы можете поместить их в таблицу без полей 1 × 1. Эта таблица считается родительской для абзаца, и в нее можно добавить новые абзацы.
Добавить таблицы в этот шаблон документа
Последний пример, который я хотел бы показать, — это как добавить таблицы в шаблон слова. На самом деле, лучшим описанием было бы то, как вы можете заполнить предопределенные таблицы в вашем шаблоне слов. Как и в случае с простым текстом и абзацами, мы заменим заполнители. Для этого примера добавьте простую таблицу в ваш текстовый документ (который вы можете стилизовать по своему усмотрению). К этой таблице добавьте 1 фиктивную строку, которая служит шаблоном для контента. В коде мы будем искать эту строку, копировать ее и заменять содержимое новыми строками из кода Java следующим образом:
- найдите таблицу, которая содержит одно из наших ключевых слов
- скопировать строку, которая служит шаблоном строки
- для каждой строки данных добавьте строку в таблицу на основе шаблона строки
- удалить исходную строку шаблона
Такой же подход, как мы показали и для абзацев. Сначала давайте посмотрим, как мы предоставим данные для замены. Для этого примера я просто предоставляю набор хеш-карт, которые содержат имя замещающего элемента и значение для его замены. Я также предоставляю токены для замены, которые можно найти в строке таблицы.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
Map<String,String> repl1 = new HashMap<String, String>(); repl1.put("SJ_FUNCTION", "function1"); repl1.put("SJ_DESC", "desc1"); repl1.put("SJ_PERIOD", "period1"); Map<String,String> repl2 = new HashMap<String,String>(); repl2.put("SJ_FUNCTION", "function2"); repl2.put("SJ_DESC", "desc2"); repl2.put("SJ_PERIOD", "period2"); Map<String,String> repl3 = new HashMap<String,String>(); repl3.put("SJ_FUNCTION", "function3"); repl3.put("SJ_DESC", "desc3"); repl3.put("SJ_PERIOD", "period3"); replaceTable(new String[]{"SJ_FUNCTION","SJ_DESC","SJ_PERIOD"}, Arrays.asList(repl1,repl2,repl3), template); |
Теперь, как выглядит этот метод replaceTable.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
|
private void replaceTable(String[] placeholders, List<Map<String, String>> textToAdd, WordprocessingMLPackage template) throws Docx4JException, JAXBException { List<Object> tables = getAllElementFromObject(template.getMainDocumentPart(), Tbl.class); // 1. find the table Tbl tempTable = getTemplateTable(tables, placeholders[0]); List<Object> rows = getAllElementFromObject(tempTable, Tr.class); // first row is header, second row is content if (rows.size() == 2) { // this is our template row Tr templateRow = (Tr) rows.get(1); for (Map<String, String> replacements : textToAdd) { // 2 and 3 are done in this method addRowToTable(tempTable, templateRow, replacements); } // 4. remove the template row tempTable.getContent().remove(templateRow); } } |
Этот метод находит таблицу, получает первую строку и для каждой предоставленной карты добавляет новую строку в таблицу. Перед возвратом удаляет строку шаблона. Этот метод использует два помощника: addRowToTable и getTemplateTable. Сначала рассмотрим этот последний:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
private Tbl getTemplateTable(List<Object> tables, String templateKey) throws Docx4JException, JAXBException { for (Iterator<Object> iterator = tables.iterator(); iterator.hasNext();) { Object tbl = iterator.next(); List<?> textElements = getAllElementFromObject(tbl, Text.class); for (Object text : textElements) { Text textElement = (Text) text; if (textElement.getValue() != null && textElement.getValue().equals(templateKey)) return (Tbl) tbl; } } return null; } |
Эта функция просто смотрит, содержит ли таблица один из наших заполнителей. Если так, то эта таблица возвращается. Операция addRowToTable также очень проста.
|
01
02
03
04
05
06
07
08
09
10
11
12
|
private static void addRowToTable(Tbl reviewtable, Tr templateRow, Map<String, String> replacements) { Tr workingRow = (Tr) XmlUtils.deepCopy(templateRow); List textElements = getAllElementFromObject(workingRow, Text.class); for (Object object : textElements) { Text text = (Text) object; String replacementValue = (String) replacements.get(text.getValue()); if (replacementValue != null) text.setValue(replacementValue); } reviewtable.getContent().add(workingRow); } |
Этот метод копирует наш шаблон и заменяет заполнители в этой строке шаблона предоставленными значениями. Эта копия добавлена в таблицу. Вот и все. С помощью этого фрагмента кода мы можем заполнять произвольные таблицы в нашем текстовом документе, сохраняя при этом макет и стиль таблиц.
Вот и все для этой статьи. С помощью абзацев и таблиц вы можете создавать множество различных типов документов, и это точно соответствует типу документов, которые чаще всего генерируются. Этот же подход можно использовать и для добавления контента другого типа в текстовые документы.
Справка: Создавайте сложные документы Word (.docx) программно с помощью docx4j от нашего партнера JCG Йоса Дирксена из блога Smart Java .