Вступление
Как отрасль, мы внедряем более прозрачные и более предсказуемые процессы сборки, чтобы снизить риски при создании программного обеспечения. Одним из основных принципов непрерывной доставки является сбор отзывов с помощью обратной связи. На Dev9 мы приняли принцип « первым узнать », который согласуется с принципом CD, что означает, что мы (команда разработчиков) хотим быть первыми, кто узнает о сбое, снижении производительности или любом результате, не совместимом с бизнес-цели.
Maven и другие инструменты сборки предоставили разработчикам стандартизированный инструмент и экосистему для создания обратной связи и обмена ею. В то время как модульные тесты, функционал, принятие сборки, миграция базы данных, тестирование производительности и инструменты анализа кода стали основой разработки, бенчмаркинг в основном остался вне процесса. Это может быть связано с отсутствием открытых источников, недорогих инструментов или легких библиотек, которые добавляют минимальную сложность.
Существующие инструменты часто усугубляют сложность, требуя интеграции внешнего инструмента с артефактом времени выполнения, и тесты не сохраняются в том же исходном хранилище или даже не сохраняются в исходном хранилище. Локальные разработчики не могут выполнить тесты без усилий, и поэтому тесты быстро теряют свою ценность. В добавление к основным задачам решения, бенчмаркинг обычно не преподается в классах и часто реализуется без необходимой изоляции, необходимой для получения достоверных результатов. Это делает все блоги или сообщения о результатах тестов зрелой целью для троллей.
С учетом всего вышесказанного, все еще очень важно обеспечить некоторый эталонный охват вокруг критических областей вашей кодовой базы. Накапливая исторические знания о критических разделах кода, можно повлиять на усилия по оптимизации, проинформировать команду о техническом долге, предупредить об изменении порога производительности и сравнить предыдущие или новые версии алгоритмов. Теперь должен возникнуть вопрос: как найти и легко добавить бенчмаркинг в мой новый или существующий проект? В этом блоге мы сосредоточимся на проектах Java (1.7+). Пример кода будет использовать Maven, хотя Gradle работает очень похоже. Я делаю несколько рекомендаций по всему блогу, и они основаны на опыте прошлых проектов.
Представляем JHM
Существует множество вариантов выбора для сравнения кода на основе Java, но большинство из них имеют недостатки, которые включают в себя лицензионные платежи, дополнительные инструменты, манипулирование байтовым кодом и / или java-агенты, тесты, описанные с использованием кода не на основе Java, и очень сложные параметры конфигурации. Мне бы хотелось, чтобы тесты были максимально приближены к тестируемому коду, чтобы уменьшить хрупкость, уменьшить сцепление и уменьшить сцепление. Я считаю, что большинство тестовых решений, с которыми я ранее работал, было слишком громоздким для работы, или код для выполнения тестов либо недостаточно изолирован (буквально интегрирован в код), либо содержится во вторичном решении вдали от источника.
Цель этого блога — продемонстрировать, как добавить в свой конвейер сборки инструмент облегченного тестирования, поэтому я не буду вдаваться в подробности о том, как использовать JMH, следующие блоги являются отличными источниками для изучения:
- http://jmhwiki.blogspot.com
- http://java-performance.info/jmh/
- http://hg.openjdk.java.net/code-tools/jmh/file/tip/jmh-samples/src/main/java/org/openjdk/jmh/samples/
Режимы бенчмаркинга
Есть небольшое количество пунктов, на которые я хочу обратить внимание в отношении режимов и оценок, поскольку они играют важную роль в настройке базовой конфигурации. На базовом уровне у JMH есть два основных типа измерения: пропускная способность и основанная на времени.
Измерение пропускной способности
Пропускная способность — это количество операций, которое может быть выполнено за единицу времени. JMH поддерживает набор успешных и неудачных операций, так как среда увеличивает нагрузку на тест. Примечание: убедитесь, что метод или тест хорошо изолированы, и такие зависимости, как создание тестового объекта, выполняются вне метода или предварительного теста в методе настройки. При использовании параметра «Пропускная способность» чем выше значение, тем лучше, поскольку оно указывает на то, что в единицу времени можно выполнять больше операций.
Измерение на основе времени
Измерение, основанное на времени, является контрагентом пропускной способности. Цель измерения на основе времени состоит в том, чтобы определить, сколько времени требуется конкретной операции для выполнения в единицу времени.
Среднее время
Наиболее распространенным измерением, основанным на времени, является «Среднее время», которое вычисляет среднее время операции. JMH также выдаст « Ошибка оценки », чтобы помочь определить достоверность полученной оценки. « Ошибка оценки » обычно составляет половину доверительного интервала и указывает, насколько близки результаты отклоняются от среднего времени. Чем ниже результат, тем лучше, поскольку он показывает меньшее среднее время выполнения операции.
SampleTime
SampleTime похож на AverageTime, но JMH пытается увеличить нагрузку и искать сбои, которые выдают матрицу ошибочных процентов. При использовании AverageTime более низкие значения лучше, а проценты полезны для определения того, где вас устраивают сбои из-за пропускной способности и продолжительности времени.
SingleShotTime
Последний и наименее часто используемый режим — SingleShotTime. Этот режим буквально однократный и может быть полезен для холодного тестирования метода или тестирования ваших тестов. SingleShotTime может быть полезен, если передан в качестве параметра при выполнении тестов бенчмаркинга, но сокращает время, необходимое для выполнения тестов (хотя это уменьшает ценность тестов и может сделать их дедвейтными) Как и в случае других измерений, основанных на времени, чем ниже значение, тем лучше.
Добавление JMH в проект Java
Цель: этот раздел покажет, как создать повторяемый жгут, который позволяет добавлять новые тесты с минимальными издержками или дублированием кода. Обратите внимание, что зависимости находятся в области «теста», чтобы избежать добавления JMH в конечный артефакт. Я создал репозиторий GitHub, который использует JMH, работая над Protobuf, альтернативой REST для микросервисов . Код можно найти здесь: https://github.com/mike-ensor/protobuf-serialization
1) Начните с добавления зависимостей в проект:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
<dependencies><!-- Other libraries left out for brevity --><!-- jmh.version is the lastest version of JMH. Find by visiting <dependency> <groupId>org.openjdk.jmh</groupId> <artifactId>jmh-core</artifactId> <version>${jmh.version}</version> <scope>test</scope> </dependency> <dependency> <groupId>org.openjdk.jmh</groupId> <artifactId>jmh-generator-annprocess</artifactId> <version>${jmh.version}</version> <scope>test</scope> </dependency><!-- Other libraries left out for brevity --></dependencies> |
2) JMH рекомендует, чтобы тесты производительности и артефакт были упакованы в одну и ту же банку Uber . Есть несколько способов реализовать uber jar, явно используя плагин «shade» для maven или неявно используя Spring Boot, Dropwizard или некоторые фреймворки с похожими результатами. В этом сообщении я использовал приложение Spring Boot.
3) Добавьте тестовый комплект с основным классом входа и глобальной конфигурацией. На этом шаге создайте точку входа в тестовой области вашего проекта (обозначен # 1 ). Намерение состоит в том, чтобы избежать того, чтобы контрольный код был упакован с основным артефактом.
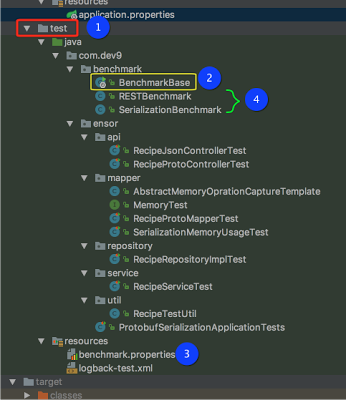
3.1) Добавьте файл BenchmarkBase (указан выше # 2 ). Этот файл будет служить точкой входа для тестов производительности и будет содержать всю глобальную конфигурацию для тестов. Класс, который я написал, ищет файл «benchmark.properties», содержащий свойства конфигурации (указанные выше в # 3 ). У JMH есть опция для вывода результатов файла, и эта конфигурация настроена для JSON. Результаты используются вместе с вашим инструментом непрерывной интеграции и могут (должны) быть сохранены для исторического использования.
Этот сегмент кода является основным жгутом и точкой входа в процесс Benchmark, выполняемый Maven (настройка на шаге 5 ниже). На этом этапе проект должен иметь возможность запустить тест производительности, поэтому давайте добавим тестовый пример.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
@SpringBootApplicationpublic class BenchmarkBase { public static void main(String[] args) throws RunnerException, IOException { Properties properties = PropertiesLoaderUtils.loadAllProperties("benchmark.properties"); int warmup = Integer.parseInt(properties.getProperty("benchmark.warmup.iterations", "5")); int iterations = Integer.parseInt(properties.getProperty("benchmark.test.iterations", "5")); int forks = Integer.parseInt(properties.getProperty("benchmark.test.forks", "1")); int threads = Integer.parseInt(properties.getProperty("benchmark.test.threads", "1")); String testClassRegExPattern = properties.getProperty("benchmark.global.testclassregexpattern", ".*Benchmark.*"); String resultFilePrefix = properties.getProperty("benchmark.global.resultfileprefix", "jmh-"); ResultFormatType resultsFileOutputType = ResultFormatType.JSON; Options opt = new OptionsBuilder() .include(testClassRegExPattern) .warmupIterations(warmup) .measurementIterations(iterations) .forks(forks) .threads(threads) .shouldDoGC(true) .shouldFailOnError(true) .resultFormat(resultsFileOutputType) .result(buildResultsFileName(resultFilePrefix, resultsFileOutputType)) .shouldFailOnError(true) .jvmArgs("-server") .build(); new Runner(opt).run(); } private static String buildResultsFileName(String resultFilePrefix, ResultFormatType resultType) { LocalDateTime date = LocalDateTime.now(); DateTimeFormatter formatter = DateTimeFormatter.ofPattern("mm-dd-yyyy-hh-mm-ss"); String suffix; switch (resultType) { case CSV: suffix = ".csv"; break; case SCSV: // Semi-colon separated values suffix = ".scsv"; break; case LATEX: suffix = ".tex"; break; case JSON: default: suffix = ".json"; break; } return String.format("target/%s%s%s", resultFilePrefix, date.format(formatter), suffix); }} |
4) Создайте класс для тестирования операции. Имейте в виду, что бенчмаркинг-тесты будут выполняться для всего тела метода, в том числе для ведения журнала, чтения файлов, внешних ресурсов и т. Д. Помните о том, что вы хотите тестировать и уменьшать или удалять зависимости, чтобы изолировать ваш основной код для обеспечения более высокая уверенность в результатах. В этом примере настройка конфигурации во время
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
@State(Scope.Benchmark)@BenchmarkMode(Mode.AverageTime)@OutputTimeUnit(TimeUnit.MICROSECONDS)public class SerializationBenchmark { private RecipeService service; private Recipe recipe; private byte[] protoRecipe; private String recipeAsJSON; @Setup(Level.Trial) public void setup() { IngredientUsed jalepenoUsed = new IngredientUsed(new Ingredient("Jalepeno", "Spicy Pepper"), MeasurementType.ITEM, 1); IngredientUsed cheeseUsed = new IngredientUsed(new Ingredient("Cheese", "Creamy Cheese"), MeasurementType.OUNCE, 4); recipe = RecipeTestUtil.createRecipe("My Recipe", "Some spicy recipe using a few items", ImmutableList.of(jalepenoUsed, cheeseUsed)); service = new RecipeService(new ObjectMapper()); protoRecipe = service.recipeAsProto(recipe).toByteArray(); recipeAsJSON = service.recipeAsJSON(recipe); } @Benchmark public Messages.Recipe serialize_recipe_object_to_protobuf() { return service.recipeAsProto(recipe); } @Benchmark public String serialize_recipe_object_to_JSON() { return service.recipeAsJSON(recipe); } @Benchmark public Recipe deserialize_protobuf_to_recipe_object() { return service.getRecipe(protoRecipe); } @Benchmark public Recipe deserialize_json_to_recipe_object() { return service.getRecipe(recipeAsJSON); }} |
Надпись: этот гистограмма — пример тестового примера, извлеченного из Protobuf Serialization.
Все ваши тестовые классы * Benchmark * .java теперь будут запускаться при выполнении jar-теста, но это часто не идеально, поскольку процесс не разделен, и для контроля времени сборки важно иметь некоторый контроль над тем, когда и как выполняются тесты. вниз.
Давайте создадим профиль Maven, чтобы контролировать время выполнения тестов и потенциально запускать приложение. Обратите внимание, чтобы показать, что интеграционные тесты maven запускают / останавливают сервер, я включил это в сообщение в блоге. Я бы предостерег от необходимости запускать или останавливать сервер приложений, поскольку вы можете нести расходы на выборку ресурсов (вызовы REST), которые не будут сильно изолированы.
5) Идея состоит в том, чтобы создать профиль maven для отдельного запуска всех тестов производительности (т. Е. Без модульных или функциональных тестов). Это позволит проводить тесты производительности параллельно с остальным конвейером сборки. Обратите внимание, что код использует плагин «exec» и запускает uber jar, ища полный путь к классам до основного класса. Кроме того, область исполняемого файла ограничена только «тестовыми» источниками, чтобы избежать включения кода теста в конечные артефакты.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
<profile> <id>benchmark</id> <properties> <maven.test.ITests>true</maven.test.ITests> </properties> <build> <plugins> <!-- Start application for benchmarks to test against --> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <executions> <execution> <id>pre-integration-test</id> <goals> <goal>start</goal> </goals> </execution> <execution> <id>post-integration-test</id> <goals> <goal>stop</goal> </goals> </execution> </executions> </plugin> <!-- Turn off unit tests --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-surefire-plugin</artifactId> <configuration> <excludes> <exclude>**/*Tests.java</exclude> <exclude>**/*Test.java</exclude> </excludes> </configuration> </plugin> <plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>exec-maven-plugin</artifactId> <version>1.5.0</version> <executions> <execution> <goals> <goal>exec</goal> </goals> <phase>integration-test</phase> </execution> </executions> <configuration> <executable>java</executable> <classpathScope>test</classpathScope> <arguments> <argument>-classpath</argument> <classpath /> <argument>com.dev9.benchmark.BenchmarkBase</argument> <argument>.*</argument> </arguments> </configuration> </plugin> </plugins> </build></profile> |
В этом фрагменте кода показан пример профиля maven для запуска только тестов Benchmark.
6) Последний, необязательный элемент — создать работоспособный шаг сборки в конвейере сборки Continuous Integration. Чтобы проводить тесты производительности изолированно, вы или ваш CI можете запустить:
|
1
|
mvn clean verify -Pbenchmark |
Вывод
Если вы используете проект на основе Java, JMH относительно легко добавить в ваш проект и конвейер. Преимущества исторической бухгалтерской книги, относящиеся к критическим областям вашего проекта, могут быть очень полезны для поддержания высокого уровня качества. Добавление JMH в ваш конвейер также соответствует принципам непрерывной доставки, включая петли обратной связи, автоматизацию, повторяемость и непрерывное улучшение. Попробуйте добавить жгут проводов JMH и несколько тестов для критических областей вашего решения.
| Ссылка: | Добавление микробенчмаркинга в процесс сборки от нашего партнера по JCG Майка Энсора в блоге сайта Майка . |