Предположим, что наше тестовое приложение имело огромный успех, и постепенно один сервер не способен обрабатывать растущий трафик. Мы сталкиваемся с двумя вариантами: заменить наш сервер на лучший ( масштабирование ) или купить второй и построить кластер ( масштабирование ). Мы решили построить кластер, поскольку в будущем его будет проще масштабировать. Однако мы быстро обнаруживаем, что наше приложение больше не отвечает самым первым требованиям:
- Клиентское приложение должно вызывать URL […] не более чем из одного потока — запрещается одновременно выбирать случайные числа, используя несколько HTTP-соединений.
Очевидно, что каждый узел в кластере является независимым и имеет свой отдельный экземпляр Akka, то есть отдельную копию
RandomOrgClientсубъекта. Для решения этой проблемы у нас есть несколько вариантов:
- наличие глобальной (общекластерной!) блокировки (распределенный монитор, семафор и т. д.) для защиты многопоточного доступа. Обычного
synchronizedмало. - … или создать выделенный узел в кластере для связи
random.org, используемый всеми другими узлами через некоторый API - … или создать только один экземпляр
RandomOrgClientточно на одном узле и предоставить его через некоторый API (RMI, JMS …) удаленным клиентам
Вы помните, сколько времени потратили на описание различий между ActorиActorRef ? Теперь это различие станет очевидным. В свою очередь, наше решение будет основано на последнем предложении, однако нам не нужно беспокоиться об уровне API, сериализации, связи или транспорта. Более того, в Akka нет такого API для работы с удаленными актерами. Достаточно сказать в файле конфигурации: предполагается, что этот конкретный субъект будет создан только на этом узле . Все остальные узлы вместо локального создания того же субъекта будут возвращать специальный прокси-сервер, который снаружи выглядит как обычный субъект, в то время как в действительности он пересылает все сообщения удаленному субъекту на другом узле.
Скажем еще раз: нам не нужно ничего менять в нашем коде, достаточно внести некоторые изменения в файл конфигурации:
akka {
actor {
provider = "akka.remote.RemoteActorRefProvider"
deployment {
/buffer/client {
remote = "akka://RandomOrgSystem@127.0.0.1:2552"
}
}
}
remote {
transport = "akka.remote.netty.NettyRemoteTransport"
log-sent-messages = on
netty {
hostname = "127.0.0.1"
}
}
}
Это оно! Каждый узел в кластере идентифицируется адресом и портом сервера. Ключевой частью конфигурации является объявление, /buffer/clientкоторое предполагается создать только 127.0.0.1:2552. Каждый другой экземпляр (работающий на другом сервере или порту) вместо создания новой копии субъекта создаст специальный прозрачный прокси, вызывающий удаленный сервер.
Если вы не помните архитектуру нашего решения, рисунок ниже демонстрирует поток сообщений. Как вы можете видеть, каждый узел имеет свою собственную копию RandomOrgBuffer(в противном случае каждый доступ к буферу приведет к удаленному вызову, что полностью отрицает назначение буфера). Однако каждый узел (кроме среднего) имеет удаленную ссылку на RandomOrgClientсубъекта (узел посередине обращается к этому субъекту локально):
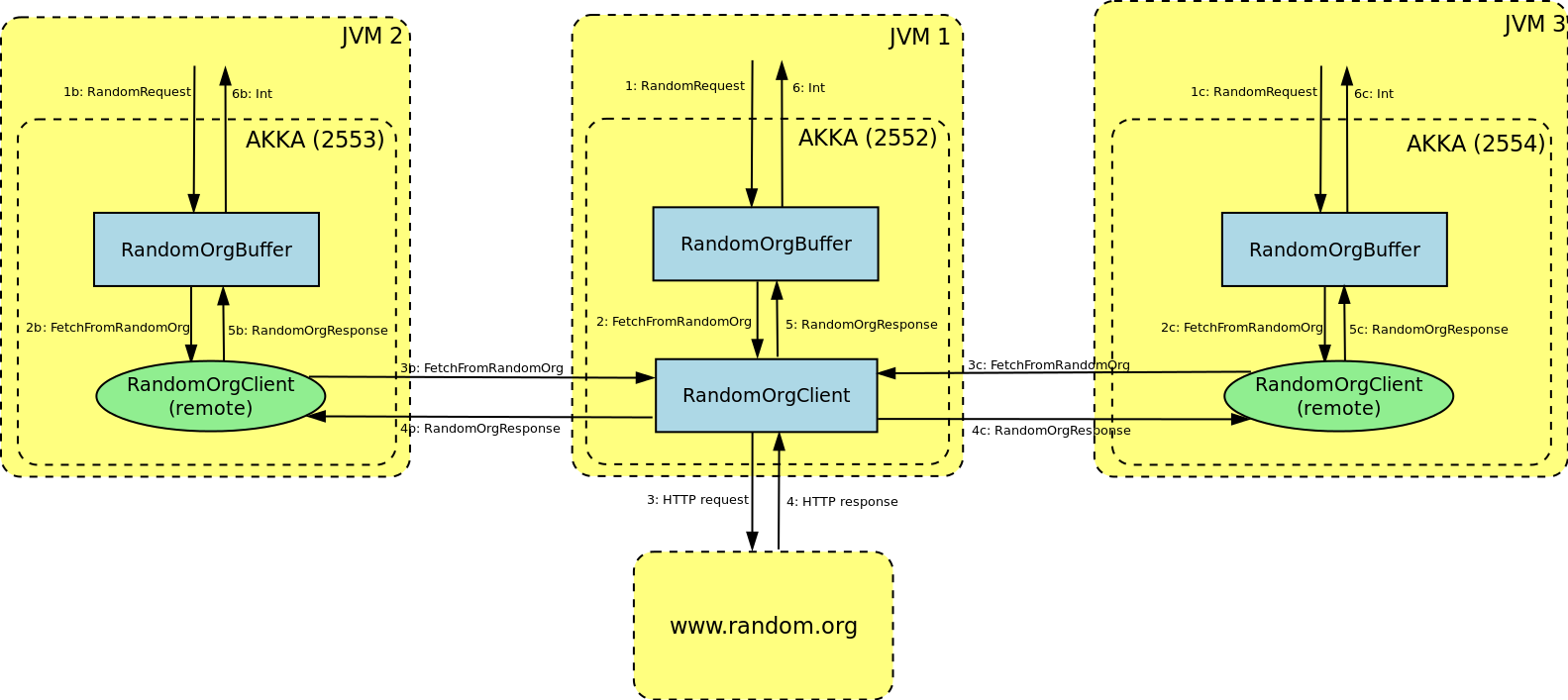
Машина в середине (JVM 1) выполняется через порт 2552, и это единственная машина, с которой обменивается данными
random.org. Все остальные (JVM 2 и 3, работающие на 2553 и 2554 соответственно) обмениваются данными с этим сервером косвенно через JVM 1. Кстати, мы можем изменить порт TCP / IP, используемый каждым узлом, используя файл конфигурации или
-Dakka.remote.netty.port=2553свойство Java.
Прежде чем мы объявим о преждевременном успехе (опять же), мы столкнулись с другой проблемой. Или на самом деле, мы еще не преодолели первоначальное препятствие. Поскольку
RandomOrgClientтеперь доступ к нему осуществляется несколькими
RandomBufferсубъектами (распределенными по кластеру), он все же может инициировать несколько одновременных HTTP-соединений
random.orgот имени каждого узла в кластере. Легко представить ситуацию, когда несколько
RandomOrgBufferэкземпляров отправляют
FetchFromRandomOrgсообщение одновременно, начиная несколько одновременных HTTP-соединений. Чтобы избежать этой ситуации, мы реализуем
уже известную технику организации очередей запросов в акторе, если один запрос еще не завершен
case class FetchFromRandomOrg(batchSize: Int)
case class RandomOrgServerResponse(randomNumbers: List[Int])
class RandomOrgClient extends Actor {
val client = new AsyncHttpClient()
val waitingForReply = new mutable.Queue[(ActorRef, Int)]
override def postStop() {
client.close()
}
def receive = LoggingReceive {
case FetchFromRandomOrg(batchSize) =>
waitingForReply += (sender -> batchSize)
if (waitingForReply.tail.isEmpty) {
sendHttpRequest(batchSize)
}
case response: RandomOrgServerResponse =>
waitingForReply.dequeue()._1 ! response
if (!waitingForReply.isEmpty) {
sendHttpRequest(waitingForReply.front._2)
}
}
private def sendHttpRequest(batchSize: Int) {
val url = "https://www.random.org/integers/?num=" + batchSize + "&min=0&max=65535&col=1&base=10&format=plain&rnd=new"
client.prepareGet(url).execute(new RandomOrgResponseHandler(self))
}
}
private class RandomOrgResponseHandler(notifyActor: ActorRef) extends AsyncCompletionHandler[Unit]() {
def onCompleted(response: Response) {
val numbers = response.getResponseBody.lines.map(_.toInt).toList
notifyActor ! RandomOrgServerResponse(numbers)
}
}
На этот раз обратите внимание на
waitingForReplyочередь. Когда приходит запрос на выборку случайных чисел из удаленного веб-сервиса, либо мы инициируем новое соединение (если в очереди нет никого, кроме нас). Если ожидают другие актеры, мы должны вежливо поставить себя в очередь, помня, кто запрашивал, сколько чисел (
waitingForReply += (sender -> batchSize)). Когда приходит ответ, мы берем самого первого участника из очереди (который ждет самое большое количество времени) и инициируем еще один запрос от его имени.
Неудивительно, что нет многопоточности или кода синхронизации. Однако важно не нарушать инкапсуляцию, получая доступ к ее состоянию вне
receiveметода. Я сделал эту ошибку, прочитав
waitingForReplyочередь внутри
onCompleted()метод. Поскольку этот метод вызывается асинхронно рабочим потоком HTTP-клиента, потенциально мы можем получить доступ к нашему состоянию акторов одновременно из двух потоков (если он обрабатывал какое-то сообщение
receiveодновременно). Вот почему я решил выделить ответный HTTP-ответ в отдельный класс, не имея неявного доступа к субъекту. Это намного безопаснее, поскольку доступ к состоянию актера охраняется самим компилятором.
Это последняя часть нашей
серии Открытия Акка . Помните, что полный исходный код доступен на
GitHub .