На прошлой неделе я написал в блоге о том, почему важно контролировать свой SQL , так как написание хорошего SQL помогает снизить эксплуатационные расходы. Это верно во многих отношениях, и сегодня мы рассмотрим другой способ написания хорошего, высокопроизводительного SQL: использование «метода поиска».
Медленный сдвиг
Чтобы понять метод поиска, давайте сначала разберемся, какую проблему он решает: предложения SQL OFFSET работают медленно . Они медленные по простой причине. Чтобы достичь высокого смещения из набора результатов, все предыдущие записи должны быть пропущены и подсчитаны. Хотя запрос без OFFSETможет быть очень быстрым (с использованием синтаксиса MySQL):
SELECT first_name, last_name, score FROM players WHERE game_id = 42 ORDER BY score DESC LIMIT 10;
Переход на страницу с номером 10’000 будет намного медленнее:
SELECT first_name, last_name, score FROM players WHERE game_id = 42 ORDER BY score DESC LIMIT 10 OFFSET 100000;
Даже если кортеж (game_id, score)будет проиндексирован, нам придется проследить весь индекс, чтобы подсчитать, сколько записей мы уже пропустили. Хотя эта проблема может быть несколько уменьшена путем трюка , связанного playersс производной таблицей, существует альтернативный, гораздо более быстрый подход к решению подкачки: метод поиска.
Метод поиска
Хотя не совсем ясно, кто изначально изобрел метод поиска ( некоторые также называют его «подкачкой ключей» ), очень заметным сторонником этого является Маркус Винанд . Он описывает метод поиска в своем блоге (и в своей книге ):
http://use-the-index-luke.com/sql/partial-results/fetch-next-page
По сути, метод поиска не пропускает записи перед смещением, но пропускает записи до последней выбранной записи. Подумайте о поиске в Google. С точки зрения удобства использования вы вряд ли пропустите ровно 100 000 записей. В основном вы хотите перейти на следующую страницу, а затем снова на следующую страницу, то есть сразу после последней выбранной записи / результата поиска. Возьмите следующие 10 лучших игроков (поддельные имена, созданные с помощью генератора имен ):
first_name | last_name | score ------------------------------ Mary | Paige | 1098 Tracey | Howard | 1087 Jasmine | Butler | 1053 Zoe | Piper | 1002 Leonard | Peters | 983 Jonathan | Hart | 978 Adam | Morrison | 976 Amanda | Gibson | 967 Alison | Wright | 958 Jack | Harris | 949
Выше приведены первые 10 игроков, упорядоченных по счету. Это может быть достигнуто довольно быстро, используя LIMIT 10только. Теперь, когда OFFSET 10вы переходите на следующую страницу, вы можете либо просто использовать предложение, либо пропустить всех пользователей с баллом выше, чем 949:
SELECT first_name, last_name, score FROM players WHERE game_id = 42 -- Let's call this the "seek predicate" AND score < 949 ORDER BY score DESC LIMIT 10;
Это даст вам игроков на следующей странице:
first_name | last_name | score ------------------------------ William | Fraser | 947 Claire | King | 945 Jessica | McDonald | 932 ... | ... | ...
Обратите внимание, что предыдущий запрос предполагает scoreуникальность playersтаблицы, что, конечно, маловероятно. Если бы Уильям Фрейзер также имел 949очки, как и Джек Харрис, последний игрок на первой странице, он был бы «потерян между страницами». Поэтому важно создать однозначное предложение ORDER BY и «предикат поиска», добавив дополнительный уникальный столбец:
SELECT player_id, first_name, last_name, score FROM players WHERE game_id = 42 -- assuming 15 is Jack Harris's player_id AND (score, player_id) < (949, 15) ORDER BY score DESC, player_id DESC LIMIT 10;
Теперь «предикат поиска» зависит от ORDER BYусловия. Вот несколько возможных альтернативных конфигураций:
-- "consistent" ASC and DESC correspond to > and < AND (score, player_id) > (949, 15) ORDER BY score ASC, player_id ASC -- "mixed" ASC and DESC complicate things a bit AND ((score < 949) OR (score = 949 AND player_id > 15)) ORDER BY score DESC, player_id ASC -- The above might be further performance-tweaked AND (score <= 949) AND ((score < 949) OR (score = 949 AND player_id > 15)) ORDER BY score DESC, player_id ASC
Если столбцы в ORDER BYпредложении являются обнуляемым, NULLS FIRSTи NULLS LASTможет применяться и в дальнейшем усложнит «искать предикат».
Как это лучше, чем OFFSET?
Метод поиска позволяет избежать дорогостоящих операций «пропустить и сосчитать», заменив их простым сканированием диапазона по индексу, который может охватывать «предикат поиска». Так как вы в любом случае применяете ORDER BY к столбцам «предиката поиска», вы, возможно, уже решили соответствующим образом их проиндексировать .
Хотя метод поиска не улучшает запросы для небольших номеров страниц, выборка больших номеров страниц выполняется значительно быстрее, что доказано в этом замечательном тесте:
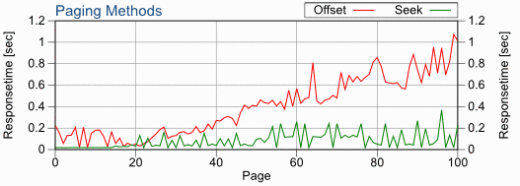
Воспроизводится с сайта use-the-index-luke.com с разрешения Маркуса Винанда.
Более интересные отзывы на эту тему можно найти в этой ветке reddit.com , в которую даже сам Том Кайт добавил пару замечаний .
Побочный эффект метода поиска
Побочным эффектом метода поиска является тот факт, что подкачка более «стабильна». Когда вы собираетесь отобразить страницу 2, и новый игрок тем временем достиг страницы 1, или если какой-либо игрок полностью удален, вы все равно будете отображать тех же игроков на странице 2. Другими словами, при использовании метода поиска , нет гарантии, что первый игрок на странице 2 имеет ранг 11.
Это может или не может быть желательным. Это может быть неуместно на странице 10’000, хотя.
Поддержка jOOQ 3.3 для метода поиска
В готовящемся выпуске jOOQ 3.3 ( выход которого запланирован на конец 2013 г.) будет включена поддержка метода поиска на уровне API SQL DSL. В дополнение к существующей поддержке LIMIT .. OFFSET в jOO, можно указать «предикат поиска» через синтетическое SEEKпредложение (аналогично синтетическому DIVIDE BYпредложению jOOQ ):
DSL.using(configuration)
.select(PLAYERS.PLAYER_ID,
PLAYERS.FIRST_NAME,
PLAYERS.LAST_NAME,
PLAYERS.SCORE)
.from(PLAYERS)
.where(PLAYERS.GAME_ID.eq(42))
.orderBy(PLAYERS.SCORE.desc(),
PLAYERS.PLAYER_ID.asc())
.seek(949, 15) // (!)
.limit(10)
.fetch();
Вместо того чтобы явно формулировать «предикат поиска», просто передайте последнюю запись из предыдущего запроса, и jOOQ увидит, что все записи до и включая эту запись пропущены, учитывая ORDER BYпредложение.
Это выглядит намного более читабельным, чем реальный SQL, потому что «предикат поиска» ближе к ORDER BYпредложению, к которому он принадлежит. Кроме того, здесь применяется стандартная безопасность типов значений jOOQ , помогая вам найти правильную степень / арность и типы данных для вашего SEEKпредложения. В приведенном выше примере следующие вызовы методов не будут компилироваться в Java:
// Not enough arguments in seek()
.orderBy(PLAYERS.SCORE.desc(),
PLAYERS.PLAYER_ID.asc())
.seek(949)
// Wrong argument types in seek()
.orderBy(PLAYERS.SCORE.desc(),
PLAYERS.PLAYER_ID.asc())
.seek(949, "abc")
Начало работы с методом поиска
Благодаря встроенной поддержке API для SEEKпредложения вы можете снова получить контроль над своим SQL и довольно легко реализовать высокопроизводительный SQL. Ранние пользователи уже могут поиграть с текущим состоянием jOOQ 3.3.0 Open Source Edition , которое доступно на GitHub .
И даже если вы не используете jOOQ, попробуйте метод поиска. Впоследствии у вас может быть гораздо более быстрое приложение!