партнеров по JCG , недавно написал очень хорошую статью о том, как использовать асинхронную обработку для увеличения пропускной способности вашего сервера . Давайте узнаем, как он это сделал.
(ПРИМЕЧАНИЕ: оригинальный пост был слегка отредактирован для улучшения читабельности)
Не секрет, что контейнеры сервлетов Java не особенно подходят для обработки большого количества одновременно работающих пользователей. Общепринятая модель потоков на запрос эффективно ограничивает число одновременных подключений количеством одновременно работающих потоков, которые JVM может обработать. И поскольку каждый новый поток вносит значительное увеличение объема используемой памяти и использования ЦП (переключение контекста), обработка более 100-200 одновременных соединений кажется нелепой идеей в Java. По крайней мере, это было в эпоху до Servlet 3.0.
В этой статье мы напишем масштабируемый и надежный файловый сервер с ограничением скорости. Во второй версии, используя функцию асинхронной обработки Servlet 3.0, мы сможем обрабатывать в десять раз большую нагрузку, используя еще меньше потоков. Никакого дополнительного оборудования не требуется, только несколько мудрых дизайнерских решений.
Алгоритм токена
Создавая файловый сервер, мы должны сознательно управлять нашими ресурсами, особенно пропускной способностью сети. Мы не хотим, чтобы один клиент занимал весь трафик, нам может даже потребоваться динамическое ограничение лимита загрузки во время выполнения, в зависимости от пользователя, времени суток и т. Д. — и, конечно, все происходит во время большой нагрузки. Разработчики любят изобретать велосипед, однако все наши требования уже учтены простым алгоритмом набора токенов .
Объяснение в Википедии довольно хорошее, но, поскольку мы немного подстроим алгоритм под наши нужды, приведем еще более простое описание. Сначала было ведро. В этом ведре были одинаковые жетоны. Каждый токен стоит 20 КБ (я буду использовать реальные значения из нашего приложения) необработанных данных. Каждый раз, когда клиент запрашивает файл, сервер пытается извлечь один токен из корзины. Если это удается, он отправляет 20 КБ клиенту. Повторите последние два предложения. Что если серверу не удалось получить токен, потому что корзина уже пуста? Он ждет.
Так откуда же идут токены? Фоновый процесс заполняет ведро время от времени. Теперь становится понятно. Если этот фоновый процесс добавляет 100 новых токенов каждые 100 мс (10 раз в секунду), каждый из которых стоит 20 КБ, сервер способен отправлять максимум 20 МБ / с (100 × 20 КБ × 10), общий для всех клиентов. Конечно, если корзина заполнена (1000 жетонов), новые жетоны игнорируются. Это работает на удивление хорошо — если корзина пуста, клиенты ждут следующего цикла наполнения корзины; и контролируя емкость сегмента, мы можем ограничить общую пропускную способность.
Кстати, наша упрощенная реализация корзины токенов начинается с интерфейса (весь исходный код доступен на GitHub в ветке global-bucket ):
|
01
02
03
04
05
06
07
08
09
10
11
|
public interface TokenBucket { int TOKEN_PERMIT_SIZE = 1024 * 20; void takeBlocking() throws InterruptedException; void takeBlocking(int howMany) throws InterruptedException; boolean tryTake(); boolean tryTake(int howMany);} |
Методы takeBlocking () синхронно ожидают, когда токен станет доступным, в то время как tryTake () принимает токен только в том случае, если он доступен, и сразу возвращает true, если он был принят, в противном случае — false. К счастью, термин bucket — это просто абстракция: поскольку токены неразличимы, все, что нам нужно реализовать, так как bucket — это целочисленный счетчик. Но поскольку ведро по своей сути многопоточно и требует некоторого ожидания, нам необходим более сложный механизм. Семафор кажется почти идеальным:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
@Service@ManagedResourcepublic class GlobalTokenBucket extends TokenBucketSupport { private final Semaphore bucketSize = new Semaphore(0, false); private volatile int bucketCapacity = 1000; public static final int BUCKET_FILLS_PER_SECOND = 10; @Override public void takeBlocking(int howMany) throws InterruptedException { bucketSize.acquire(howMany); } @Override public boolean tryTake(int howMany) { return bucketSize.tryAcquire(howMany); }} |
Семафор точно соответствует нашим требованиям. bucketSize представляет текущее количество токенов в корзине. bucketCapacity, с другой стороны, ограничивает максимальный размер корзины. Это изменчиво, потому что это может быть изменено через JMX (видимость):
|
01
02
03
04
05
06
07
08
09
10
|
@ManagedAttributepublic int getBucketCapacity() { return bucketCapacity;}@ManagedAttributepublic void setBucketCapacity(int bucketCapacity) { isTrue(bucketCapacity >= 0); this.bucketCapacity = bucketCapacity;} |
Как вы можете видеть, я использую Spring и его поддержку JMX. Spring Framework не является абсолютно необходимым в этом приложении, но он приносит некоторые приятные функции. Например, реализация фонового процесса, который периодически заполняет контейнер, выглядит следующим образом:
|
1
2
3
4
5
6
7
|
@Scheduled(fixedRate = 1000 / BUCKET_FILLS_PER_SECOND)public void fillBucket() { final int releaseCount = min(bucketCapacity / BUCKET_FILLS_PER_SECOND, bucketCapacity - bucketSize.availablePermits()); bucketSize.release(releaseCount);} |
Этот код содержит серьезную многопоточную ошибку, которую мы можем игнорировать для целей этой статьи. Предполагается заполнить ведро до максимального значения — это всегда будет работать?
Кроме того, вот фрагмент XML (applicationContext.xml), необходимый для работы аннотации @Scheduled :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
<?xml version="1.0" encoding="UTF-8"?> xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:task="http://www.springframework.org/schema/task" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task-3.0.xsd"> <context:component-scan base-package="com.blogspot.nurkiewicz.download" /> <context:mbean-export/> <task:annotation-driven scheduler="bucketFillWorker"/> <task:scheduler id="bucketFillWorker" pool-size="1"/></beans> |
Имея маркерную абстракцию и очень простую реализацию, мы можем разработать реальные файлы, возвращающие сервлет. Я всегда возвращаю один и тот же фиксированный файл размером почти 200 КБ):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
@WebServlet(urlPatterns = "/*", name="downloadServletHandler")public class DownloadServlet extends HttpRequestHandlerServlet {}@Servicepublic class DownloadServletHandler implements HttpRequestHandler { private static final Logger log = LoggerFactory.getLogger(DownloadServletHandler.class); @Resource private TokenBucket tokenBucket; @Override public void handleRequest(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { final File file = new File("/home/dev/tmp/ehcache-1.6.2.jar"); final BufferedInputStream input = new BufferedInputStream(new FileInputStream(file)); try { response.setContentLength((int) file.length()); sendFile(request, response, input); } catch (InterruptedException e) { log.error("Download interrupted", e); } finally { input.close(); } } private void sendFile(HttpServletRequest request, HttpServletResponse response, BufferedInputStream input) throws IOException, InterruptedException { byte[] buffer = new byte[TokenBucket.TOKEN_PERMIT_SIZE]; final ServletOutputStream outputStream = response.getOutputStream(); for (int count = input.read(buffer); count > 0; count = input.read(buffer)) { tokenBucket.takeBlocking(); outputStream.write(buffer, 0, count); } }} |
HttpRequestHandlerServlet был использован здесь. Как можно проще: прочитайте 20 КБ файла, извлеките токен из корзины (ожидая, если он недоступен), отправьте чанк клиенту, повторите до конца файла.
Верьте или нет, это на самом деле работает! Независимо от того, сколько (или сколько) клиентов одновременно получают доступ к этому сервлету, общая пропускная способность исходящей сети никогда не превышает 20 МБ! Алгоритм работает, и я надеюсь, что вы почувствуете, как его использовать. Но давайте посмотрим правде в глаза — глобальный лимит слишком негибкий и отчасти хромой — один клиент может фактически потреблять всю вашу пропускную способность.
Так что, если бы у нас было отдельное ведро для каждого клиента? Вместо одного семафора — карта? Каждый клиент имеет отдельный независимый предел пропускной способности, поэтому нет риска голодания. Но есть еще больше:
некоторые клиенты могут быть более привилегированными, иметь больше или вообще не иметь ограничений,
некоторые могут быть в черном списке, что приводит к отклонению соединения или очень низкой пропускной способности
Запрет IP-адресов, требующие аутентификации, куки-файлов / проверки агента пользователя и т. д.
мы могли бы попытаться сопоставить параллельные запросы, поступающие от одного и того же клиента, и использовать один и тот же блок для всех из них, чтобы избежать мошенничества, открыв несколько соединений. Мы также можем отклонить последующие подключения
и многое другое…
Наш расширенный интерфейс расширяется, что позволяет реализации использовать новые возможности (см. Ветвь для запроса-синхронизации ):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
public interface TokenBucket { void takeBlocking(ServletRequest req) throws InterruptedException; void takeBlocking(ServletRequest req, int howMany) throws InterruptedException; boolean tryTake(ServletRequest req); boolean tryTake(ServletRequest req, int howMany); void completed(ServletRequest req);}public class PerRequestTokenBucket extends TokenBucketSupport { private final ConcurrentMap<Long, Semaphore> bucketSizeByRequestNo = new ConcurrentHashMap<Long, Semaphore>(); @Override public void takeBlocking(ServletRequest req, int howMany) throws InterruptedException { getCount(req).acquire(howMany); } @Override public boolean tryTake(ServletRequest req, int howMany) { return getCount(req).tryAcquire(howMany); } @Override public void completed(ServletRequest req) { bucketSizeByRequestNo.remove(getRequestNo(req)); } private Semaphore getCount(ServletRequest req) { final Semaphore semaphore = bucketSizeByRequestNo.get(getRequestNo(req)); if (semaphore == null) { final Semaphore newSemaphore = new Semaphore(0, false); bucketSizeByRequestNo.putIfAbsent(getRequestNo(req), newSemaphore); return newSemaphore; } else { return semaphore; } } private Long getRequestNo(ServletRequest req) { final Long reqNo = (Long) req.getAttribute(REQUEST_NO); if (reqNo == null) { throw new IllegalAccessError("Request # not found in: " + req); } return reqNo; }} |
Реализация очень похожа (полный класс здесь ) за исключением того, что один семафор был заменен картой. Я не использую сам объект запроса в качестве ключа карты по различным причинам, а использую уникальный номер запроса, который я назначаю вручную при получении нового соединения. Вызов завершен () очень важно, в противном случае карта будет расти непрерывно, что приводит к утечке памяти. В целом, реализация блока токенов не сильно изменилась, также сервлет загрузки практически не изменился (за исключением передачи запроса в блок токенов). Теперь мы готовы к стресс-тестированию!
Тестирование пропускной способности
В целях тестирования мы будем использовать JMeter с этим замечательным набором плагинов . Во время 20-минутного сеанса тестирования мы разогреваем наш сервер, запуская один новый поток (параллельное соединение) каждые 6 секунд, чтобы достичь 100 потоков через 10 минут. В течение следующих десяти минут мы будем поддерживать 100 одновременных подключений, чтобы увидеть, насколько стабильно работает сервер. Вот активные темы со временем:
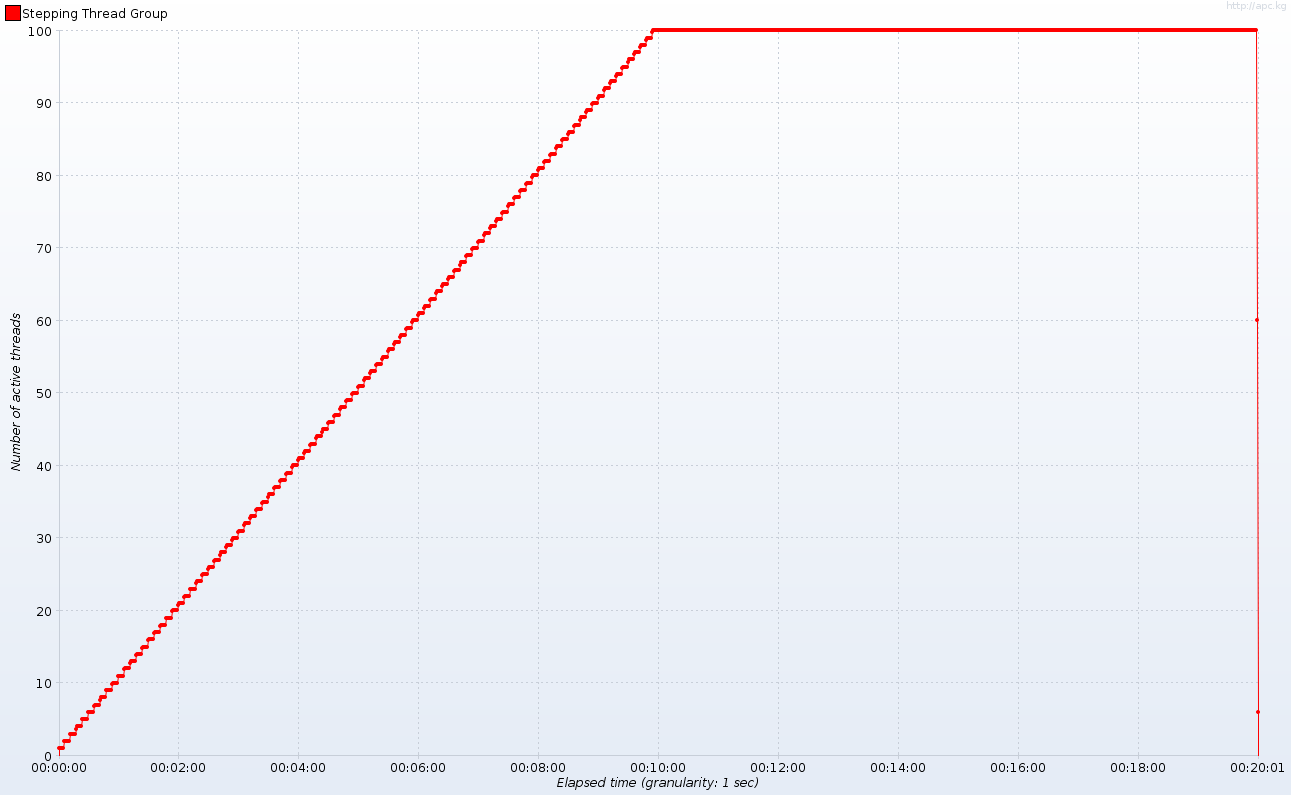
Важное примечание : я искусственно уменьшил количество рабочих потоков HTTP до 10 в Tomcat (проверено 7.0.10). Это далеко от реальной конфигурации, но я хотел бы подчеркнуть некоторые явления, возникающие при высокой нагрузке по сравнению с возможностями сервера. При размере пула по умолчанию мне понадобилось бы несколько клиентских машин, на которых выполнялся распределенный сеанс JMeter, чтобы генерировать достаточно трафика. Если у вас есть ферма серверов или пара серверов в облаке (в отличие от моего 3-летнего ноутбука), я был бы рад увидеть результаты в более реалистичной среде.
Вспоминая, сколько рабочих потоков HTTP доступно в Tomcat, время отклика далеко не удовлетворительное:
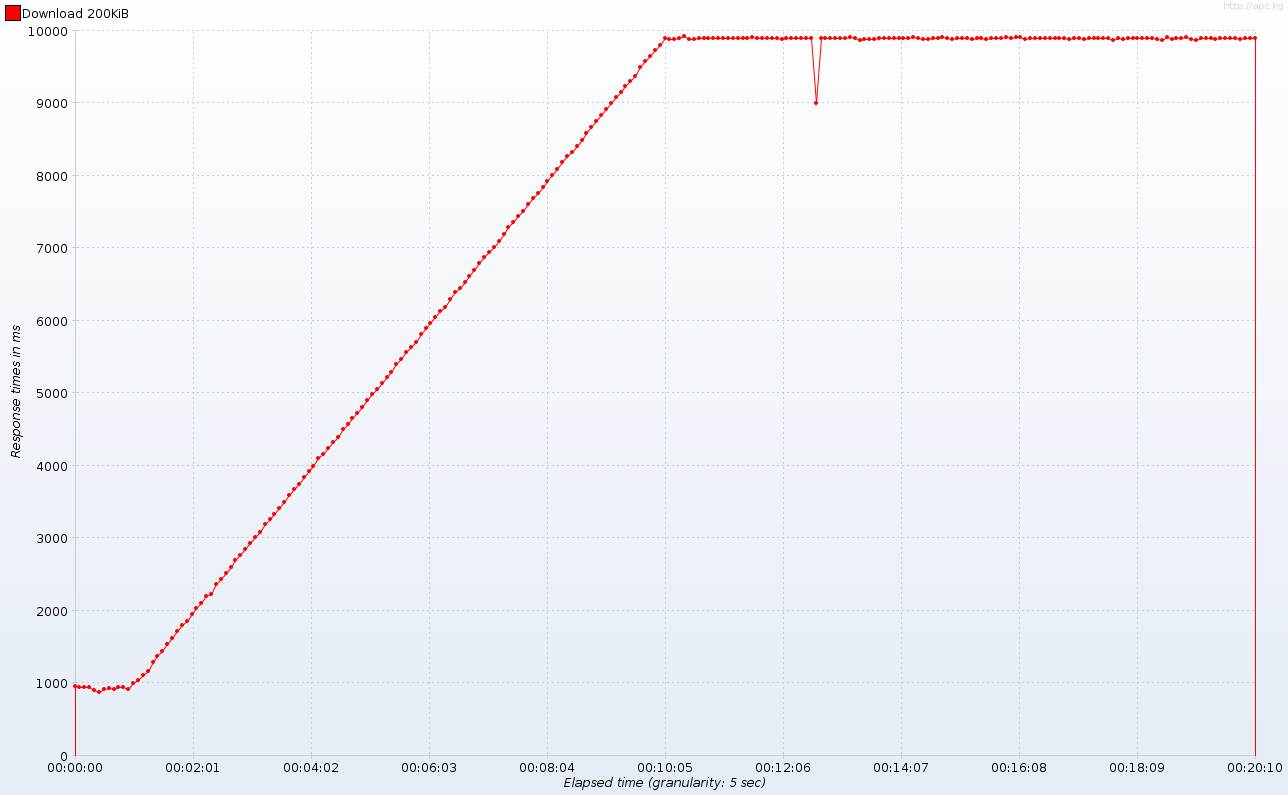
Обратите внимание на плато в начале теста: примерно через минуту (подсказка: когда число одновременных подключений превышает 10) время отклика стремительно стабилизируется примерно через 10 секунд через 10 минут (количество одновременных подключений достигает ста). Еще раз: такое же поведение будет происходить с 100 рабочими потоками и 1000 одновременных подключений — это просто вопрос масштаба. График задержек ответов (время между отправкой запроса и получением первых строк ответа) устраняет любые сомнения:
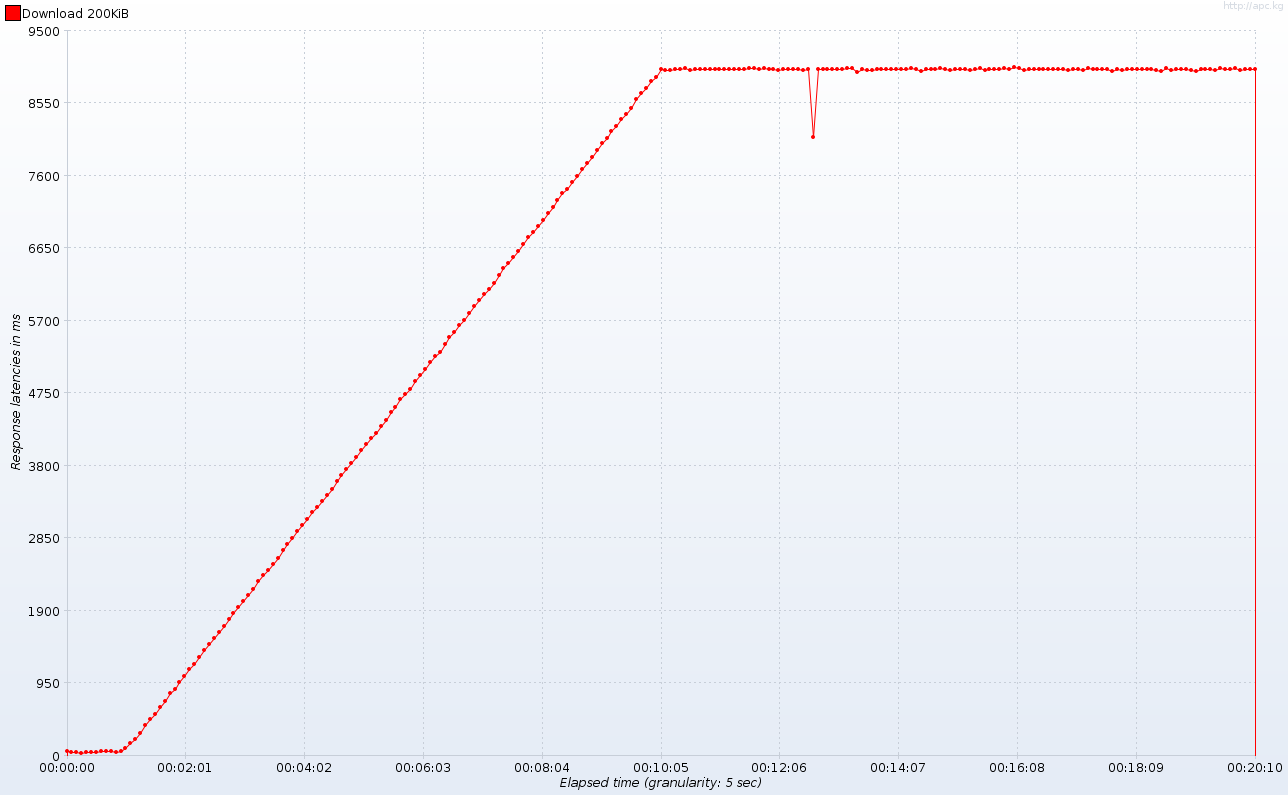
Ниже магического числа 10 потоков наше приложение реагирует практически мгновенно. Это действительно важно для клиентов, так как получение только заголовков (особенно Content-Type и Content-Length) позволяет им более точно информировать пользователя о происходящем. Так в чем же причина того, что Tomcat ждет ответа? Здесь нет магии. У нас всего 10 потоков, и каждому соединению требуется один поток, поэтому Tomcat (и любой другой контейнер, предшествующий сервлету 3.0) обрабатывает 10 клиентов, а остальные 90 находятся в … очереди. В тот момент, когда один из 10 счастливчиков завершен, выполняется одно соединение из очереди. Это объясняет среднюю задержку в 9 секунд, в то время как сервлету требуется только 1 секунда для обслуживания запроса (200 КБ с пределом 20 КБ / с). Если вы все еще не уверены, Tomcat предоставляет хорошие индикаторы JMX, показывающие, сколько потоков занято и сколько запросов поставлено в очередь:
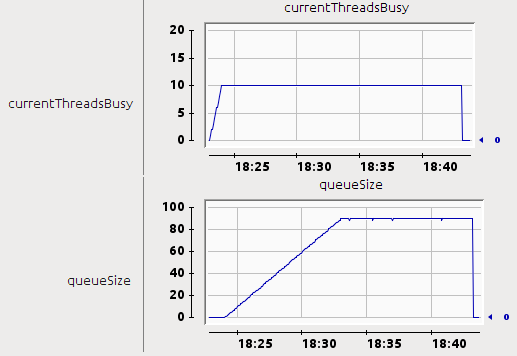
С традиционными сервлетами мы ничего не можем поделать. Пропускная способность ужасна, но увеличение общего количества потоков не вариант (подумайте: от 100 до 1000). Но вам на самом деле не нужен профилировщик, чтобы обнаружить, что потоки здесь не являются узким местом. Посмотрите внимательно на DownloadServletHandler, где вы думаете, что большую часть времени проводит? Чтение файла? Отправлять данные обратно клиенту? Нет, сервлет ждет … А потом ждет еще больше. Непродуктивно зависает на семафоре — к счастью, процессор не пострадал, но что, если он был реализован с использованием ожидания ожидания? К счастью, Tomcat 7 наконец поддерживает …
Servlet 3.0 асинхронная обработка
Мы близки к тому, чтобы увеличить пропускную способность нашего сервера на порядок, но требуются некоторые нетривиальные изменения (см. Ветку master ). Во-первых, загрузочный сервлет должен быть помечен как асинхронный (хорошо, это все еще тривиально):
|
1
2
|
@WebServlet(urlPatterns = "/*", name="downloadServletHandler", asyncSupported = true)public class DownloadServlet extends HttpRequestHandlerServlet {} |
Основное изменение происходит в обработчике загрузки. Вместо того, чтобы отправлять весь файл в цикле с большим количеством ожиданий (takeBlocking ()), мы разделяем цикл на отдельные итерации, каждая из которых заключена в Callable. Теперь мы будем использовать небольшой пул потоков, который будет использоваться всеми ожидающими соединениями. Каждая задача в пуле очень проста: вместо того, чтобы ждать токен, он запрашивает его неблокирующим образом (tryTake ()). Если токен доступен, часть файла отправляется клиенту (sendChunkWorthOneToken ()). Если токен недоступен (корзина пуста), ничего не происходит. Независимо от того, был ли токен доступен или нет, задача повторно отправляется в очередь для дальнейшей обработки (это по сути очень сложный, многопоточный цикл). Поскольку существует только один пул, задача попадает в конец очереди, что позволяет обслуживать другие соединения.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
@Servicepublic class DownloadServletHandler implements HttpRequestHandler { @Resource private TokenBucket tokenBucket; @Resource private ThreadPoolTaskExecutor downloadWorkersPool; @Override public void handleRequest(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { final File file = new File("/home/dev/tmp/ehcache-1.6.2.jar"); response.setContentLength((int) file.length()); final BufferedInputStream input = new BufferedInputStream(new FileInputStream(file)); final AsyncContext asyncContext = request.startAsync(request, response); downloadWorkersPool.submit(new DownloadChunkTask(asyncContext, input)); } private class DownloadChunkTask implements Callable<Void> { private final BufferedInputStream fileInputStream; private final byte[] buffer = new byte[TokenBucket.TOKEN_PERMIT_SIZE]; private final AsyncContext ctx; public DownloadChunkTask(AsyncContext ctx, BufferedInputStream fileInputStream) throws IOException { this.ctx = ctx; this.fileInputStream = fileInputStream; } @Override public Void call() throws Exception { try { if (tokenBucket.tryTake(ctx.getRequest())) { sendChunkWorthOneToken(); } else downloadWorkersPool.submit(this); } catch (Exception e) { log.error("", e); done(); } return null; } private void sendChunkWorthOneToken() throws IOException { final int bytesCount = fileInputStream.read(buffer); ctx.getResponse().getOutputStream().write(buffer, 0, bytesCount); if (bytesCount < buffer.length) done(); else downloadWorkersPool.submit(this); } private void done() throws IOException { fileInputStream.close(); tokenBucket.completed(ctx.getRequest()); ctx.complete(); } }} |
Я оставляю детали API Servlet 3.0, есть множество менее сложных примеров в Интернете. Просто не забудьте вызвать startAsync () и работать с возвращенным AsyncContext вместо простого запроса и ответа.
Кстати, создание пула потоков с использованием Spring по-детски легко (и мы получаем хорошие имена потоков в отличие от Executors и ExecutorService ):
Правильно, одного потока достаточно для обслуживания ста одновременно работающих клиентов. Убедитесь сами (количество рабочих потоков HTTP все еще равно 10, и да, масштаб в миллисекундах).
Время отклика с течением времени

Время отклика с течением времени
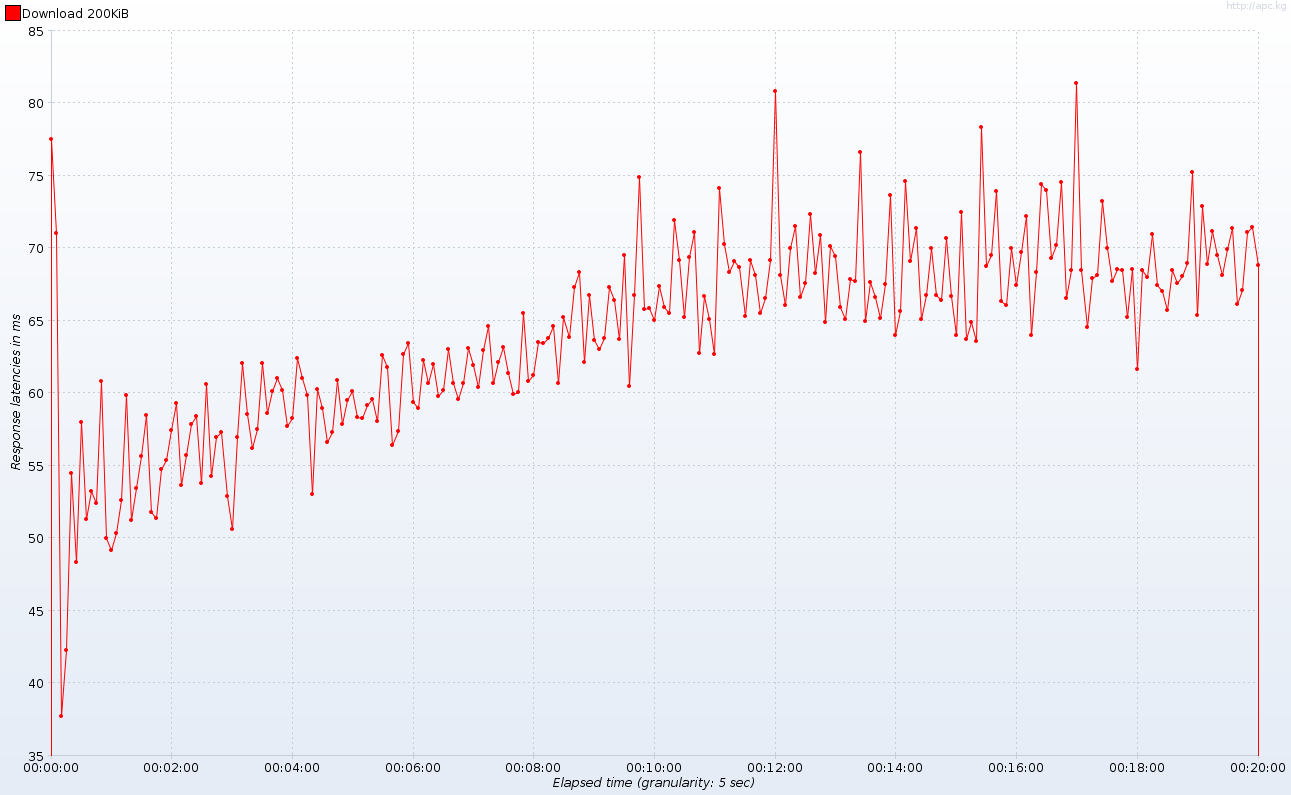
Как видите, время отклика, когда сто клиентов одновременно скачивают файл, всего на 5% выше по сравнению с системой почти без нагрузки. Также задержки отклика не особенно пострадают от увеличения нагрузки. Я не могу продвинуть сервер еще дальше из-за моих ограниченных аппаратных ресурсов, но у меня есть основания полагать, что это простое приложение будет обрабатывать вдвое больше соединений: и HTTP-потоки, и рабочий поток загрузки не были полностью использованы в течение всего теста , Это также означает, что мы увеличили емкость нашего сервера в 10 раз, даже не используя все потоки!
Надеюсь, вам понравилась эта статья. Конечно, не каждый вариант использования может быть так легко масштабирован, но в следующий раз вы заметите, что ваш сервлет в основном ожидает — не тратьте потоки HTTP и рассмотрите асинхронную обработку сервлета 3.0. И проверить, измерить и сравнить! Доступны полные исходные коды приложений (см. Различные разделы), включая план тестирования JMeter.
Зоны улучшения
Есть еще несколько мест, которые требуют внимания и улучшения. Если хотите, не стесняйтесь, разветвляйтесь, модифицируйте и тестируйте:
- Во время профилирования я обнаружил, что в более чем 80% исполнений DownloadChunkTask не получает токен, а только перепланирует его сам. Это ужасная трата процессорного времени, которую можно легко исправить (как?)
- Попробуйте открыть файл и отправить длину содержимого в рабочем потоке, а не в HTTP-потоке (до запуска асинхронного контекста)
- Как можно реализовать глобальное ограничение поверх ограничений пропускной способности на запрос? У вас есть хотя бы пара вариантов: либо ограничить размер очереди пула рабочих загрузок и отклонить выполнение, либо обернуть PerRequestTokenBucket переопределенным GlobalTokenBucket (шаблон декоратора)
- Метод TokenBucket.tryTake () явно нарушает принцип разделения команд и запросов. Не могли бы вы подсказать, как это должно выглядеть? Почему это так сложно?
- Я знаю, что мой тест постоянно читает один и тот же маленький файл, поэтому влияние на производительность ввода-вывода минимально. Но в реальной ситуации некоторый уровень кэширования наверняка был бы применен поверх дискового хранилища. Так что разница не так уж велика (сейчас приложение использует очень маленький объем памяти, много места для кеша).
Уроки выучены
- Петлевой интерфейс не бесконечно быстр. Фактически на моей машине localhost был неспособен обрабатывать более 80 МБ / с.
- Я не использую простой объект запроса в качестве ключа в bucketSizeByRequestNo. Прежде всего, нет никаких гарантий относительно equals () и hashCode () для этого интерфейса. И что еще важнее — прочитайте следующий пункт …
- С сервлетами 3.0 при обработке запроса вы должны явно вызывать complete (), чтобы очистить и закрыть соединение. Очевидно, что после вызова этого метода объекты запроса и ответа становятся бесполезными. Что было неочевидно (и я понял, почему это сложно), так это то, что Tomcat повторно использует объекты запросов (пул) и некоторое их содержимое для последующих подключений. Это означает, что следующий код является неправильным и опасным, что может привести к доступу / повреждению атрибутов других запросов или даже сеанса (?!?)
|
1
2
|
ctx.complete();ctx.getRequest().getAttribute("SOME_KEY"); |
Вот и все. Очень хороший учебник по увеличению пропускной способности сервера с помощью асинхронной обработки Servlet 3.0 от Томаша Нуркевича , одного из наших партнеров по JCG . Не забудьте поделиться!
Статьи по Теме: