Поскольку я получил много отзывов о моем предыдущем посте, где я создал очень простой генератор изображений Ascii на Java (найдите его на GitHub ), я решил продолжить работу над проектом и добавить к нему еще несколько функций, которые, надеюсь, вам понравятся еще больше. , Я переработал основную его часть и сделал ее очень расширяемой, чтобы ее было очень легко использовать для тестирования различных алгоритмов, создания различных выходных данных и т. Д. В этой статье я представлю новую архитектуру проекта, чтобы вы могли легко интегрировать его в свой собственный код и расширять его по мере необходимости.
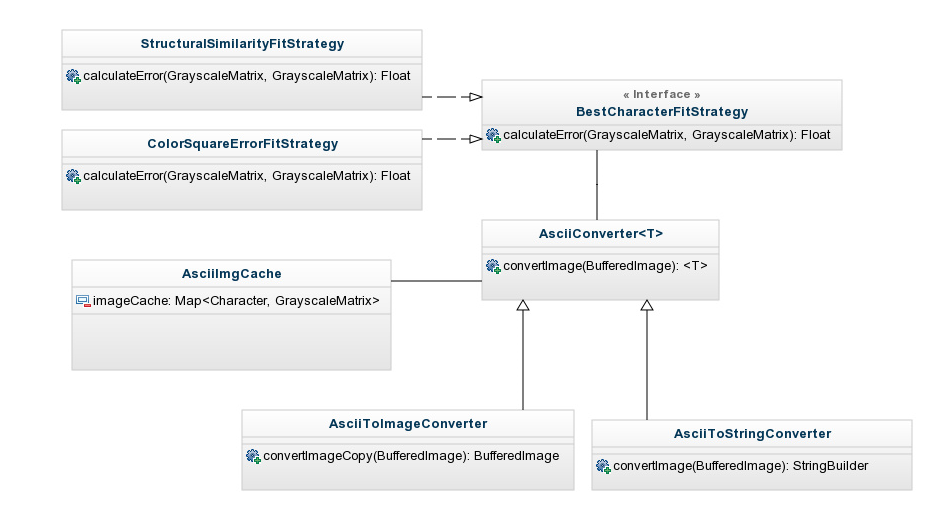
Архитектура:
AsciiImgCache
Перед выполнением любого ascii art рендеринга необходимо создать экземпляр этого класса. Он берет шрифт и список символов для использования в качестве параметров и создает карту изображений для каждого символа. Существует также список символов по умолчанию, если вы не хотите беспокоиться о своих собственных.
Если вам интересно:
private static final char[] defaultCharacters =
"$@B%8&WM#*oahkbdpqwmZO0QLCJUYXzcvunxrjft/\\|()1{}[]?-_+~<>i!lI;:,\"^`'. "
Пример:
// use only '/' '\' and ' '
AsciiImgCache mediumBlackAndWhiteCache = AsciiImgCache.
create(new Font("Courier", Font.BOLD, 10), new char[] {'\\', ' ', '/'});
// use default list
AsciiImgCache largeFontCache = AsciiImgCache.
create(new Font("Courier",Font.PLAIN, 16));
BestCharacterFitStrategy
Это абстракция алгоритма, используемого для определения того, насколько похожа часть исходного изображения на каждый символ. У него есть один метод:
float calculateError(final GrayscaleMatrix character, final GrayscaleMatrix tile);
Реализация должна сравнить два изображения и вернуть ошибку с плавающей точкой. Каждый символ будет сравниваться, и будет выбран тот, который возвращает наименьшую ошибку. В настоящее время доступны две реализации: ColorSquareErrorFitStrategy и StructuralSdentifityFitStrategy.
ColorSquareErrorFitStrategy
Очень просто понять, он сравнивает каждый пиксель и вычисляет среднеквадратичную ошибку различий в градациях серого. Говоря математически, это:
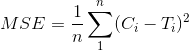
где n — количество пикселей, а C и T — пиксели от изображения символа и мозаики соответственно.
StructuralSimilarityFitStrategy
Алгоритм индекса структурного сходства (SSIM) претендует на то, чтобы воспроизводить человеческое восприятие, и его целью является улучшение традиционных методов, таких как MSE. Я не буду вдаваться в подробности о том, как это работает, вы можете прочитать больше в Википедии, если вы хотите узнать больше. Я немного поэкспериментировал с этим и реализовал версию, которая, казалось, давала лучшие результаты для этого случая.
AsciiConverter
Это сердце процесса, и оно содержит всю логику для мозаичного изображения исходного изображения и использования конкретных реализаций для расчета наилучшего соответствия символов. Тем не менее, он не знает, как создать конкретное искусство ascii — его нужно разделить на подклассы. В настоящее время существует две реализации: AsciiToImageConverter и AsciiToStringConverter — которые, как вы, вероятно, догадались, производят вывод изображения и строки.
Пример использования
Поскольку фрагмент кода стоит тысячи слов, я покажу вам весь процесс в действии, который должен завершить все части:
// initialize cache
AsciiImgCache cache = AsciiImgCache.create(new Font("Courier",Font.BOLD, 6));
// load image
BufferedImage portraitImage = ImageIO.read(new File("image.png"));
// initialize converters
AsciiToImageConverter imageConverter =
new AsciiToImageConverter(cache, new ColorSquareErrorFitStrategy());
AsciiToStringConverter stringConverter =
new AsciiToStringConverter(cache, new StructuralSimilarityFitStrategy());
// image output
ImageIO.write(imageConverter.convertImage(portraitImage), "png",
new File("ascii_art.png"));
// string converter, output to console
System.out.println(stringConverter.convertImage(portraitImage));
Вот несколько примеров изображений, созданных с различными параметрами:
{kind=link}
Шрифт 16 pts, шрифт MSE
16 pts, шрифт SSIM
10 pts с 3 символами,
шрифт MSE 10 pts с 3 символами,
шрифт SSIM 6 pts, шрифт MSE
6 pts, SSIM
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Дальнейшая работа
Некоторые идеи, которые я имею в виду:
- Исследуйте и попытайтесь реализовать больше алгоритмов сравнения изображений
- Попробуйте предварительно обработать изображение, чтобы получить лучшие результаты (улучшить контрастность, использовать обнаружение краев и т. Д.)
- Обработка изображений может быть распараллелена для повышения производительности, попробуйте ее и измерьте усиление, чтобы увидеть, если оно того стоит.
- Добавьте еще несколько конвертеров (т.е. вывод html)
- Добавить поддержку для вывода с цветными символами
- Добавить тесты в проект
Если у вас есть идеи по улучшению или вы найдете какие-либо проблемы с кодом, не стесняйтесь комментировать или вносить свой вклад в этот репозиторий через GitHub !