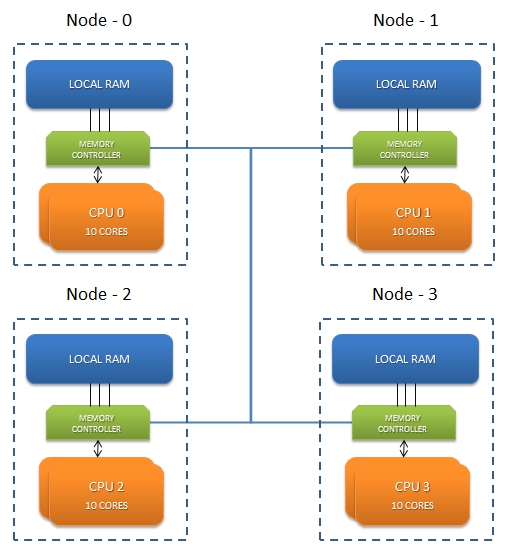
Эти блоки с огромными ядрами поставляются с архитектурой неоднородного доступа к памяти (NUMA). NUMA — это архитектура, которая повышает производительность доступа к памяти для локальных узлов. Эти новые аппаратные блоки разделены на разные зоны, называемые узлами. Эти узлы имеют определенное количество ядер с выделенной им частью памяти. Таким образом, для блока с 1 ТБ ОЗУ и 80 ядрами у нас есть 4 узла, каждый из которых имеет 20 ядер и 256 ГБ выделенной памяти.
Вы можете проверить это с помощью команды numactl --hardware
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
>numactl --hardwareavailable: 4 nodes (0-3)node 0 size: 258508 MBnode 0 free: 186566 MBnode 1 size: 258560 MBnode 1 free: 237408 MBnode 2 size: 258560 MBnode 2 free: 234198 MBnode 3 size: 256540 MBnode 3 free: 237182 MBnode distances:node 0 1 2 3 0: 10 20 20 20 1: 20 10 20 20 2: 20 20 10 20 3: 20 20 20 10 |
Когда JVM запускается, он запускает поток, который запланирован на ядрах в некоторых случайных узлах. Каждый поток использует свою локальную память, чтобы быть максимально быстрой. Поток может быть в состоянии ОЖИДАНИЯ в какой-то момент и перенесен на ЦП. На этот раз не гарантируется, что он будет на том же узле. Теперь на этот раз он должен получить доступ к удаленной области памяти, которая добавляет задержку. Удаленный доступ к памяти медленнее, потому что инструкции должны пройти по соединительной линии, которая вводит дополнительные переходы.
Команда Linux numactl предоставляет способ привязать процесс только к определенным узлам. Он блокирует процесс для определенного узла как для выполнения, так и для выделения памяти. Если экземпляр JVM заблокирован для одного узла, то трафик между узлами удаляется, и весь доступ к памяти будет происходить в быстрой локальной памяти.
|
1
2
|
numactl --cpunodebind=nodes, -c nodes Only execute process on the CPUs of nodes. |
Создан небольшой тест, который пытается сериализовать большой объект и вычисляет транзакции в секунду и задержку.
Чтобы выполнить Java-процесс, связанный с одним узлом, выполните
|
1
|
numactl --cpunodebind=0 java -Dthreads=10 -jar serializationTest.jar |
Провел этот тест на двух разных коробках.
Коробка А
4 процессора x 10 ядер x 2 (гиперпоточность) = всего 80 ядер
Узлы: 0,1,2,3
Коробка B
2 процессора x 10 ядер x 2 (гиперпоточность) = всего 40 ядер
Узлы: 0,1
Скорость процессора: 2,4 ГГц для обоих.
В настройках по умолчанию также используются все узлы, доступные в ящиках.
| коробка | Политика NUMA | TPS | Латентность (средняя) | Задержка (мин) |
| По умолчанию | 261 | 37 | 18 | |
| В | По умолчанию | 387 | 25 | 5 |
| -cpunodebind = 0,1 | 405 | 23 | 3 | |
| В | -cpunodebind = 0 | 1613 | 5 | 3 |
| -cpunodebind = 0 | 1619 | 5 | 3 |
Таким образом, мы можем сделать вывод, что настройки по умолчанию для Box A с большим количеством узлов показывают низкий результат при тесте «CPU-Intesive» по сравнению с настройками по умолчанию для Box с 2 узлами B. Но поскольку мы связываем процесс только с 2 узлами, он работает одинаково лучше. Возможно, из-за того, что у него меньше узлов для перехода, и вероятность того, что потоки будут перепланированы на те же самые, увеличена до 50%.
С --cpunodebind=0 он просто превосходит все случаи.
ПРИМЕЧАНИЕ. Выше был запущен тест с 10 потоками на 10 ядрах.
Тест Jar: скачать
Источники тестов: скачать
Ссылка: NUMA & Java от нашего партнера JCG Химадри Сингха в блоге Billions & Terabytes .