Подходы в памяти могут достигать невероятной скорости, помещая рабочий набор данных в системную память. Когда все данные хранятся в памяти, отпадает необходимость решать проблемы, возникающие при использовании традиционных вращающихся дисков. Это означает, например, что нет необходимости поддерживать дополнительные копии кэша данных и управлять синхронизацией между ними. Но у этого подхода есть и обратная сторона: данные хранятся только в памяти, они не сохранятся, если завершится работа всего кластера. Поэтому такие типы хранилищ данных вообще не считаются постоянными.
В этом посте я попытаюсь изучить новую функцию постоянного сохранения Apache Ignite и дать ясную и понятную картину работы встроенного сохранения Apache Ignite.
В большинстве случаев вы не можете (не должны) хранить весь набор данных в памяти для своего приложения, чаще всего вам следует хранить относительно небольшое горячее или активное подмножество данных, чтобы повысить производительность приложения. Остальные данные должны храниться где-то на недорогих дисках или магнитной ленте для архивирования. Существует два основных требования к хранению базы данных в памяти:
- Постоянные носители для хранения зафиксированных транзакций, тем самым поддерживая долговечность и для целей восстановления, если база данных в памяти должна быть перезагружена в память.
- Постоянное хранилище для хранения резервной копии всей базы данных в памяти.
Постоянное хранилище или носитель может быть любой распределенной или локальной файловой системой, SAN, базой данных NoSQL или даже RDBMS, такой как Postgres или Oracle. Apache Ignite (начиная с 1.5) предоставляет элегантный способ подключения хранилищ постоянных данных, таких как RDBMS или NoSQL DB, таких как Mongo DB или Cassandra. Чаще всего постоянство в СУБД будет узким местом, и у вас никогда не было горизонтального масштабирования в вашей системе. Для получения дополнительной информации я рекомендовал вам ознакомиться с примером главы книги « Высокопроизводительные вычисления в памяти с Apache Ignite ».
Итак, начиная с версии 2.1.0 , Apache Ignite предоставляет ACID и совместимое с SQL хранилище дисков, которое прозрачно интегрируется с долговременной памятью Ignite в качестве дополнительного уровня диска, хранящего данные и индексы на SSD, Flash, 3D XPoint и других энергонезависимых типах. хранилища.
Собственное постоянство Apache Ignite использует новую архитектуру долговременной памяти, которая позволяет хранить и обрабатывать данные и индексы как в памяти, так и на диске. Всякий раз, когда эта функция включена, Apache Ignite сохраняет расширенный набор данных на диске и подмножество данных в ОЗУ в зависимости от его емкости. Если в ОЗУ отсутствует подмножество данных или индекс, Durable Memory извлекает его с диска, как показано на новых рисунках ниже.
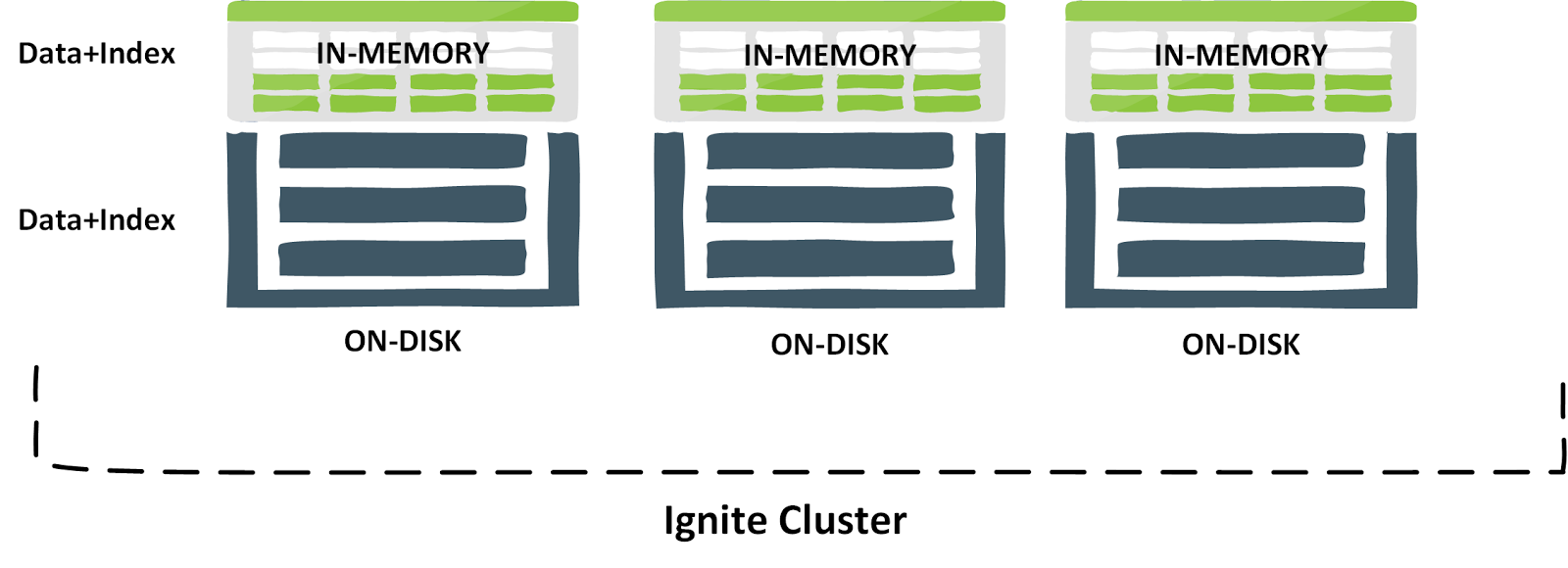
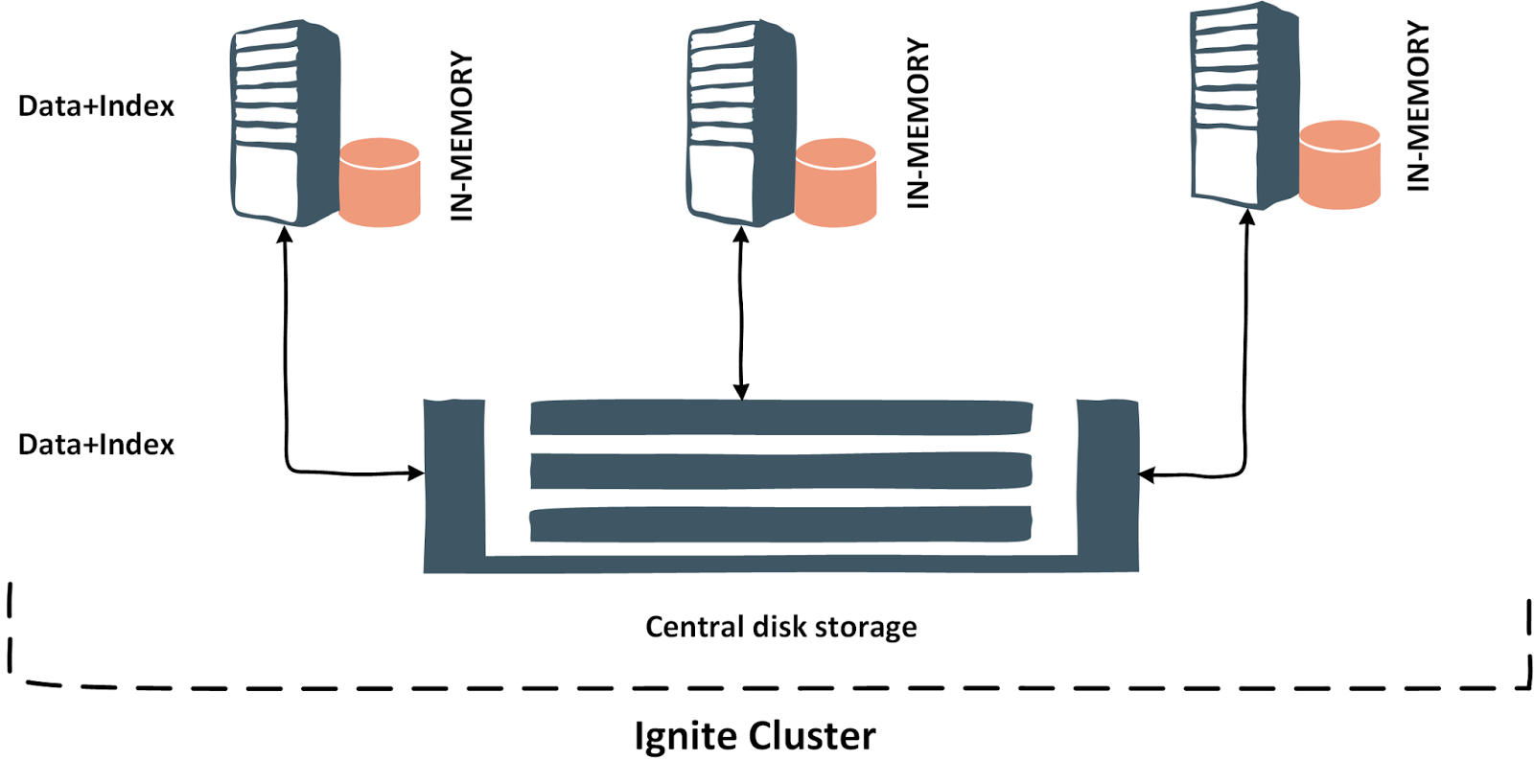
Данные также могут храниться в центральном дисковом хранилище, где все узлы Ignite подключены, как показано ниже.
Прежде чем мы начнем, давайте рассмотрим предварительные условия проекта в нашей песочнице:
- Apache Ignite версия 2.1.0
- JVM 1.8
- Версия Apache Maven> 3.0.3
- * основанная на nix операционная система
Установка.
Существует два основных способа использования Apache Ignite:
- Загрузите бинарный дистрибутив, распакуйте архив где-нибудь в вашей ОС и запустите скрипт bash ./ignite.sh с весенними конфигурационными файлами.
- Создайте проект maven с необходимыми зависимостями Apache Ignite, настройте узел с помощью кода Java и запустите его.
Здесь я собираюсь использовать первый вариант.
Шаг 1.
- Загрузите бинарный дистрибутив Apache Ignite и разархивируйте его в своей песочнице.
- Измените файл IGNITE_HOME / examples / config / persistentstore / example-persistent-store.xml и прокомментируйте следующую часть конфигурации кэша.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
<property name="cacheConfiguration"><list> <bean class="org.apache.ignite.configuration.CacheConfiguration"> <property name="name" value="testCache"/> <property name="backups" value="1"/> <property name="atomicityMode" value="TRANSACTIONAL"/> <property name="writeSynchronizationMode" value="FULL_SYNC"/> <property name="indexedTypes"> <list> <value>java.lang.Long</value> <value>org.apache.ignite.examples.model.Organization</value> </list> </property> </bean> </list></property> |
Обратите внимание, что для включения собственной персистентности Ignite вам нужно только передать следующую конфигурацию (экземпляр PersistentStoreConfiguration), которая уже предварительно настроена в файле example-persistent-store.XML.
|
1
2
3
|
<property name="persistentStoreConfiguration"><bean class="org.apache.ignite.configuration.PersistentStoreConfiguration"/></property> |
- Запустите следующую команду из каталога IGNITE_HOME.
|
1
|
./ignite.sh $IGNITE_HOME/examples/config/persistentstore/example-persistent-store.xml |
|
1
|
Step 2. create a Maven project with the following command. |
|
1
|
mvn archetype:create -DgroupId=com.blu.imdg -DartifactId=ignite-persistence |
- Добавьте следующие зависимости в pom.xml
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
<dependency> <groupId>org.apache.ignite</groupId> <artifactId>ignite-core</artifactId> <version>2.1.0</version> </dependency> <dependency> <groupId>org.apache.ignite</groupId> <artifactId>ignite-spring</artifactId> <version>2.1.0</version> </dependency> <dependency> <groupId>org.apache.ignite</groupId> <artifactId>ignite-indexing</artifactId> <version>2.1.0</version> </dependency> |
- Создайте класс Java со следующим содержимым.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
public class HelloWorld { public static void main(String[] args) { System.out.println("Hello Ignite"); // create a new instance of TCP Discovery SPI TcpDiscoverySpi spi = new TcpDiscoverySpi(); // create a new instance of tcp discovery multicast ip finder TcpDiscoveryMulticastIpFinder tcMp = new TcpDiscoveryMulticastIpFinder(); tcMp.setAddresses(Arrays.asList("localhost")); // change your IP address here // set the multi cast ip finder for spi spi.setIpFinder(tcMp); // create new ignite configuration IgniteConfiguration cfg = new IgniteConfiguration(); cfg.setClientMode(true); // set the discovery§ spi to ignite configuration cfg.setDiscoverySpi(spi); // Start ignite Ignite ignite = Ignition.start(cfg); ignite.active(true); // get or create cache IgniteCache cache = ignite.getOrCreateCache("testCache"); // put some cache elements for (int i = 1; i <= 100; i++) { cache.put(i, Integer.toString(i)); } // get them from the cache and write to the console for (int i = 1; i <= 100; i++) { System.out.println("Cache get:" + cache.get(i)); } ignite.close(); }} |
Обратите внимание, что мы используем режим клиента Ignite для манипулирования данными. После запуска приложения HelloWorld в кеш нужно вставить 100 элементов (имя кеша
testCache ).
Шаг 3.
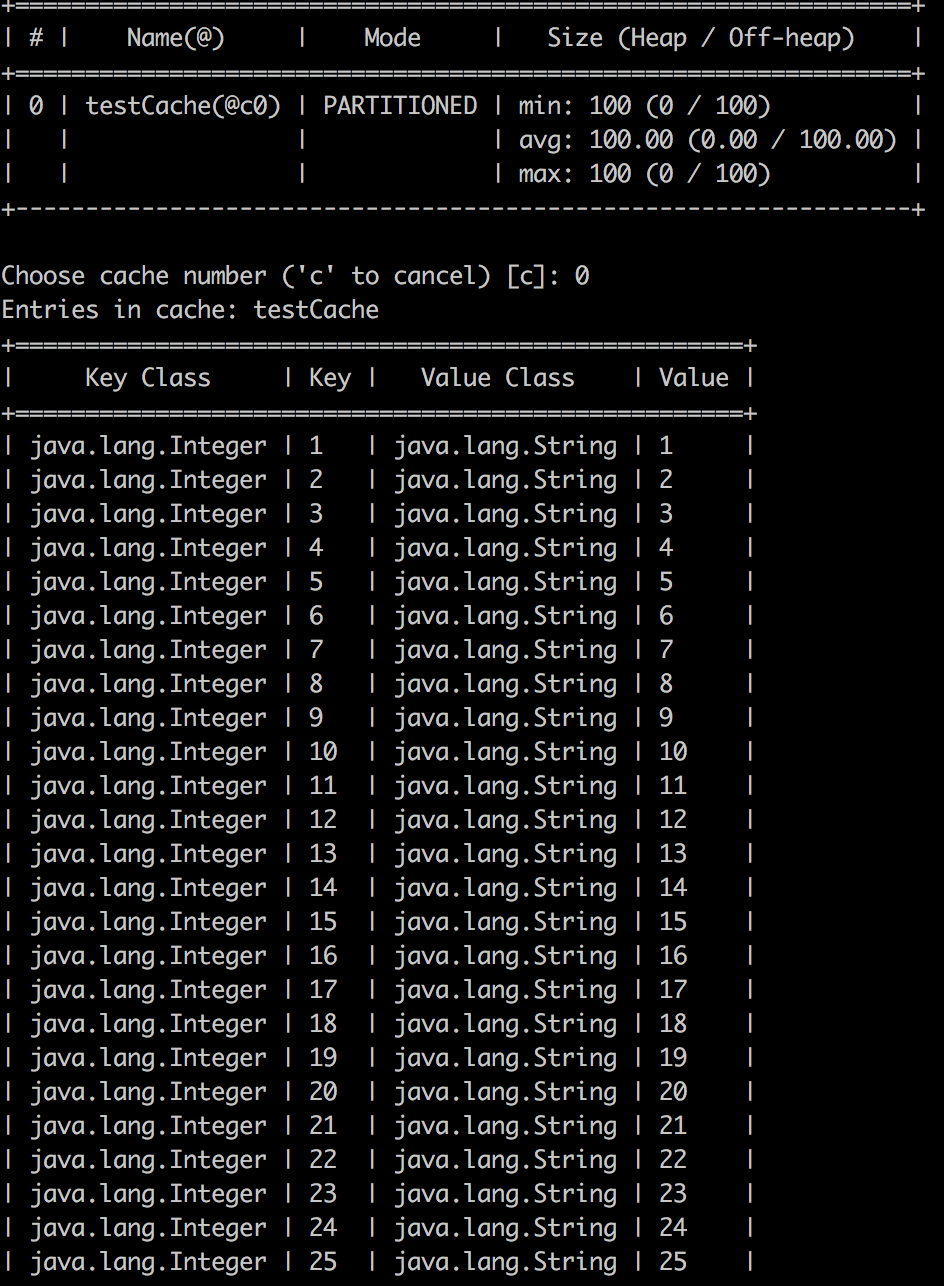
- давайте использовать инструмент команды ignitevisor для проверки данных. используйте команду cache -scan в инструменте управления ignitevisor. Вы должны получить аналогичную иллюстрацию в вашей консоли. Все 100 элементов в кеше.

- Теперь посмотрим, что произошло под капотом. Запустите следующую команду из каталога IGNITE_HOME / work
|
1
|
du -h . |
Вы должны получить что-то вроде в вашей консоли, как показано ниже.
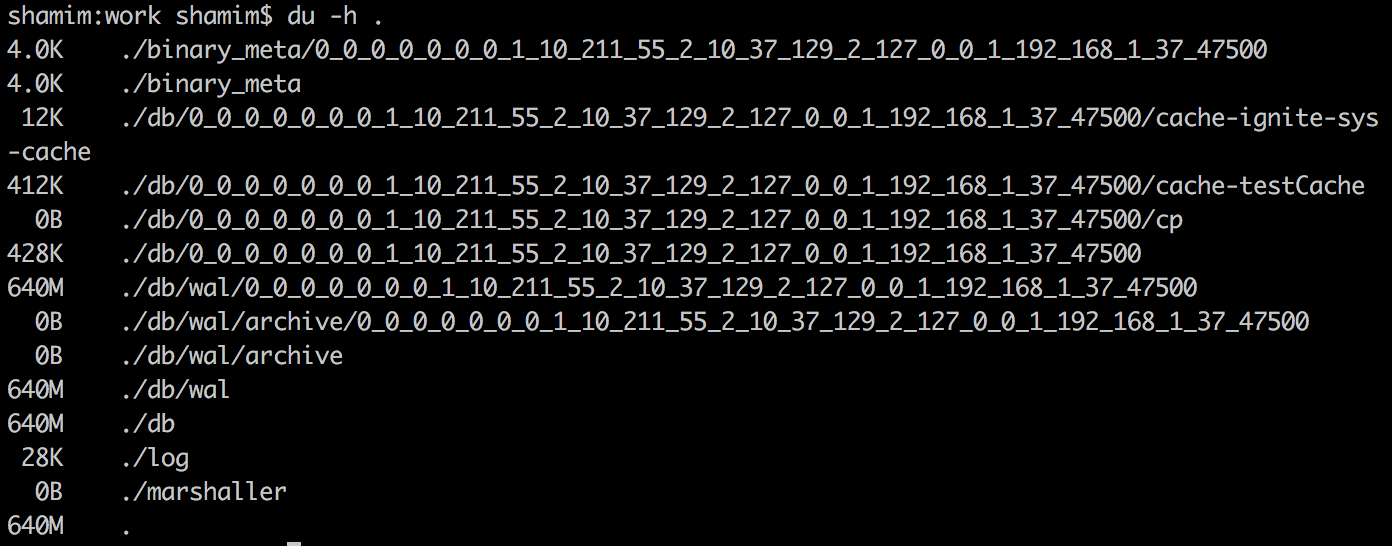
Если Apache Ignite имеет встроенное постоянство, Ignite сохранит все данные и индекс в памяти и на диске на всех узлах кластера.
Если вы пройдете через каталог db / 0_0_0_0_0_0_0_1_10_211_55_2_10_37_129_2_127_0_0_1_192_168_1_37_47500 (в моем случае), вы найдете отдельную папку для каждого кэша. Папка с именем cache-testCache будет содержать все записи кэша (100 элементов), которые мы только что вставили.
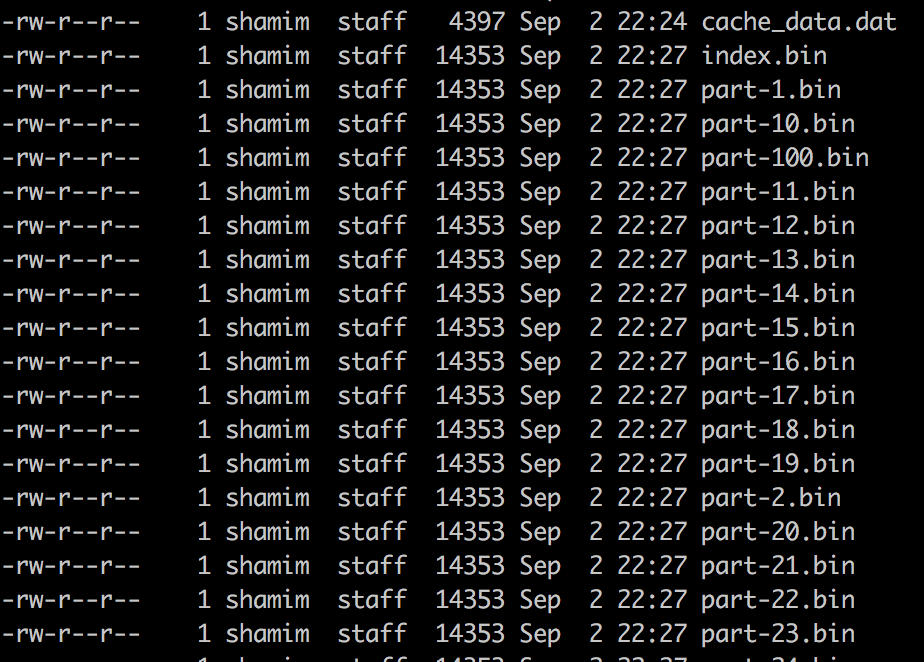
Файл index.bin является индексом записей кэша, и каждый элемент кэша получает свой отдельный файл страницы. Почему это случилось? теперь архитектура Ignite является архитектурой на основе страниц. Давайте внимательнее посмотрим, память теперь разбивается на регионы -> регионы делятся на сегменты -> сегменты делятся на страницы. Страницы можно поменять на диск. Страницы могут хранить:
- данные
- метаданные
- показатель
Страница является блоком фиксированной длины, она также поддерживает автоматическую дефрагментацию. Если вы внимательно посмотрите на размер страниц, все они составляют 14 КБ. Всякий раз, когда Ignite необходимо загрузить данные с диска, он просто загружает файл подкачки, и поэтому он очень быстрый.
Кроме того, существует еще одна концепция записи с опережением записи (WAL). Если вы выполняете обновление, сначала он обновит данные в памяти и пометит страницу как грязную, а затем сохранит данные в журнале опережающей записи. Ignite просто добавьте обновление в файл WAL. Файл WAL очень похож на файл commitlog Cassandra, с одним отличием. Cassandra записывает параллельные данные в память и файл commitlog на диске, с другой стороны, Ignite сначала обновляет данные в памяти, а затем добавляет данные в WAL. Для получения дополнительной информации, я рекомендую вам взглянуть на
документация , которая является довольно исчерпывающей.
Шаг 4
- Перезапустите узел Ignite и проверьте кэш
testCache с
воспламенитель Вы закончите с удивлением, что нет данных в кэш.

- Давайте немного изменим наш класс helloworld и снова запустим приложение, прокомментируем или удалим следующие фрагменты кода, как показано ниже.
|
1
2
3
4
|
// put some cache elementsfor (int i = 1; i <= 100; i++) { cache.put(i, Integer.toString(i));} |
|
1
|
Run the application and check the cache testCache through ignitevisor and you application console. |
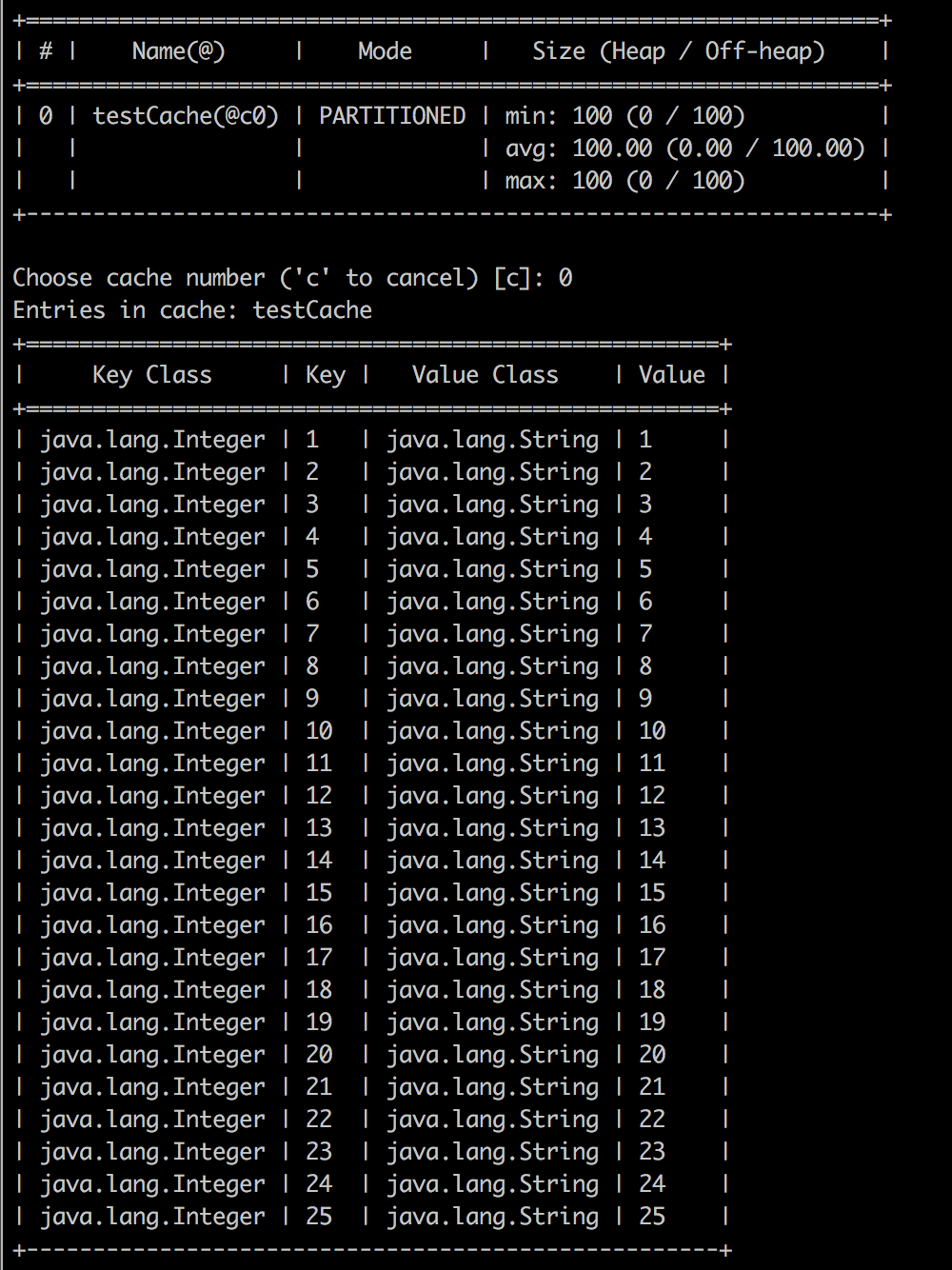
Всякий раз, когда происходит какой-либо запрос на чтение, Ignite сначала проверяет данные в памяти. Если набор данных не существует в памяти, Ignite немедленно загружает записи кэша с диска и загружает в память. Также обратите внимание, что все записи в памяти в offheap.
Преимущества
Благодаря встроенному постоянству Ignite, теперь вы можете легко создавать резервные копии для восстановления данных, Денис Магда пишет исчерпывающую статью для восстановления данных с использованием встроенного сохранения Ignite. Здесь я должен упомянуть одну репликацию данных между кластерами. Используя встроенное постоянство Ignite, теперь вы можете реплицировать данные из одного кластера в другой в режиме онлайн. Вы можете использовать любые стандартные инструменты репликации данных на диске, чтобы скопировать измененный набор данных из основного центра обработки данных в автономный центр обработки данных или кластер Ignite.
| Ссылка: | Настойчивость Apache Ignite Native — краткий обзор нашего партнера по JCG Шамима Буйяна в блоге My workspace . |