ПРИМЕЧАНИЕ РЕДАКЦИИ: В этом посте мы представляем всеобъемлющее руководство по Apache Hadoop. Apache Hadoop — это программная среда с открытым исходным кодом, написанная на Java для распределенного хранения и распределенной обработки очень больших наборов данных на компьютерных кластерах, построенных из стандартного оборудования. Все модули в Hadoop разработаны с фундаментальным предположением, что аппаратные сбои являются общими и должны автоматически обрабатываться платформой.
Hadoop стал де-факто инструментом, используемым для распределенных вычислений. По этой причине мы предоставили множество учебников здесь, на Java Code Geeks, большинство из которых можно найти здесь . Кроме того, мы регулярно публикуем новые статьи на Hadoop, чтобы освещать новые варианты использования (следите за обновлениями, подписавшись на нашу рассылку ).
Теперь мы хотели создать отдельную справочную публикацию, которая обеспечит основу для работы с Hadoop и поможет вам быстро запустить собственные приложения. Наслаждайтесь!
Содержание
1. Введение
Apache Hadoop — это фреймворк, предназначенный для обработки больших наборов данных, распределенных по большим наборам машин с использованием аппаратного обеспечения. Основные идеи были взяты из файловой системы Google (GFS или GoogleFS), представленной в этом документе и документе MapReduce .
Ключевым преимуществом Apache Hadoop является его дизайн для масштабируемости, то есть легко добавить новое оборудование для расширения существующего кластера с помощью средств хранения и вычислительной мощности. В отличие от других решений используемые принципы не полагаются на аппаратное обеспечение и предполагают его высокую доступность, а скорее принимают тот факт, что одиночные машины могут выйти из строя и что в этом случае их работа должна выполняться другими машинами в том же кластере без любое взаимодействие со стороны пользователя. Таким образом, можно построить огромные и надежные кластеры, не вкладывая в дорогостоящее оборудование.
Проект Apache Hadoop включает в себя следующие модули:
- Hadoop Common: Утилиты, которые используются другими модулями.
- Распределенная файловая система Hadoop (HDFS): распределенная файловая система, аналогичная той, которая разработана Google под названием GFS.
- Hadoop YARN: этот модуль предоставляет ресурсы для планирования заданий, используемые платформой MapReduce.
- Hadoop MapReduce: платформа, предназначенная для обработки огромного количества данных
Модули, перечисленные выше, образуют ядро Apache Hadoop, в то время как экосистема содержит множество связанных с Hadoop проектов, таких как Avro , HBase , Hive или Spark .
2. Настройка
2.1 Настройка «одного узла»
Чтобы начать, мы собираемся установить Apache Hadoop на одном узле кластера. Этот тип установки предназначен только для того, чтобы иметь работающую установку Hadoop, чтобы испачкать руки. Конечно, у вас нет преимуществ реального кластера, но этой установки достаточно для прохождения остальной части учебника.
Хотя возможно установить Apache Hadoop в операционной системе Windows, GNU / Linux является базовой платформой для разработки и производства. Для установки Apache Hadoop необходимо выполнить следующие два требования:
- Java> = 1.7 должна быть установлена.
- ssh должен быть установлен и sshd должен быть запущен.
Если ssh и sshd не установлены, это можно сделать с помощью следующих команд в Ubuntu:
|
1
2
|
$ sudo apt-get install ssh$ sudo apt-get install rsync |
Теперь, когда ssh установлен, мы создаем пользователя с именем hadoop , который позже установит и запустит кластер HDFS и задания MapReduce:
|
1
|
$ sudo useradd -s /bin/bash -m -p hadoop hadoop |
Как только пользователь создан, мы открываем для него оболочку, создаем для него пару ключей SSH, копируем содержимое открытого ключа в файл authorized_keys и проверяем, что мы можем войти в localhost, используя ssh без пароля:
|
1
2
3
4
|
$ su - hadoop$ ssh-keygen -t rsa -P ""$ cat $HOME/.ssh/id-rsa.pub >> $HOME/.ssh/authorized_keys$ ssh localhost |
Настроив базовую среду, мы теперь можем скачать дистрибутив Hadoop и распаковать его в /opt/hadoop . Запуск команд HDFS только из командной строки требует, чтобы были установлены переменные среды JAVA_HOME и HADOOP_HOME , и двоичные файлы HDFS были добавлены к пути (пожалуйста, настройте пути к вашей среде):
|
1
2
3
|
$ export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64$ export HADOOP_HOME=/opt/hadoop/hadoop-2.7.1$ export PATH=$PATH:$HADOOP_HOME/bin |
Эти строки также можно добавить в файл .bash_profile чтобы они не .bash_profile каждый раз снова.
Чтобы запустить так называемый «псевдораспределенный» режим, мы добавляем следующие строки в файл $HADOOP_HOME/etc/hadoop/core-site.xml :
|
1
2
3
4
5
6
|
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property></configuration> |
Следующие строки добавляются в файл $HADOOP_HOME/etc/hadoop/hdfs-site.xml (пожалуйста, измените пути к вашим потребностям):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/opt/hadoop/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/opt/hadoop/hdfs/datanode</value> </property></configuration> |
Как пользователь hadoop, мы создаем пути, которые мы настроили выше, как хранилище:
|
1
2
|
mkdir -p /opt/hadoop/hdfs/namenodemkdir -p /opt/hadoop/hdfs/datanode |
Прежде чем мы начнем кластер, мы должны отформатировать файловую систему:
|
1
|
$ $HADOOP_HOME/bin/hdfs namenode -format |
Теперь пришло время запустить кластер HDFS:
|
1
2
3
4
5
6
|
$ $HADOOP_HOME/sbin/start-dfs.shStarting namenodes on [localhost]localhost: starting namenode, logging to /opt/hadoop/hadoop-2.7.1/logs/hadoop-hadoop-namenode-m1.outlocalhost: starting datanode, logging to /opt/hadoop/hadoop-2.7.1/logs/hadoop-hadoop-datanode-m1.outStarting secondary namenodes [0.0.0.0]0.0.0.0: starting secondarynamenode, logging to /opt/hadoop/hadoop-2.7.1/logs/hadoop-hadoop-secondarynamenode-m1.out |
Если запуск кластера прошел успешно, мы можем указать нашему браузеру следующий URL: http: // localhost: 50070 /. Эта страница может использоваться для мониторинга состояния кластера и для просмотра содержимого файловой системы с помощью пункта меню Utilities > Browse the file system .
2.2 Настройка «Кластера»
Настройка Hadoop как кластера очень похожа на настройку «одного узла». В основном должны быть выполнены те же шаги, что и выше. Единственное отличие состоит в том, что кластеру нужен только один NameNode, то есть мы должны создавать и настраивать каталог для NameNode только на узле, который должен запускать экземпляр NameNode (главный узел).
Файл $HADOOP_HOME/etc/hadoop/slaves можно использовать, чтобы сообщить Hadoop обо всех машинах в кластере. Просто введите имя каждого компьютера в виде отдельной строки в этом файле, где первая строка обозначает узел, который должен быть ведущим (то есть запускает NameNode):
|
1
2
3
4
|
master-node.mydomain.comslave-node.mydomain.comanother-slave-node.mydomain.com... |
Прежде чем продолжить, убедитесь, что вы можете использовать ssh на всех машинах в подчиненном файле, используя их DNS-имя (как хранится в подчиненном файле) без указания пароля. В качестве предварительного условия это означает, что вы создали пользователя Hadoop на всех компьютерах и скопировали файл открытого ключа пользователя Hadoop из главного узла в файл author_keys на все другие машины в кластере, используя, например, следующую команду:
|
1
|
$ ssh-copy-id -i $HOME/.ssh/id_rsa.pub hadoop@slave-node.mydomain.com |
Мы изменили следующие строки в файле $HADOOP_HOME/etc/hadoop/core-site.xml , чтобы он содержал DNS-имя главного узла на всех машинах:
|
1
2
3
4
5
6
|
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master-node.mydomain.com:9000</value> </property></configuration> |
Кроме того, теперь мы можем также увеличить коэффициент репликации в соответствии с настройкой нашего кластера. Здесь мы используем значение 3, предполагая, что у нас есть как минимум три разных узла данных:
|
1
2
3
4
5
|
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> |
Если подчиненные файлы настроены правильно и доверенный доступ (т. Е. Доступ без пароля для пользователя hadoop) настроен для всех компьютеров, перечисленных в файле slaves , кластер можно запустить с помощью следующей командной строки на этом главном узле:
|
1
|
$ $HADOOP_HOME/sbin/start-dfs.sh |
По желанию, вместо автоматического запуска кластера с главного узла, можно также использовать сценарий hadoop-daemon.sh для запуска либо NameNode, либо DataNode на каждой из машин:
|
1
2
|
$ $HADOOP_HOME/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs start namenode$ $HADOOP_HOME/sbin/hadoop-daemons.sh --config $HADOOP_CONF_DIR --script hdfs start datanode |
Заменив команду start на stop , позже можно остановить выделенные серверы:
|
1
2
|
$ $HADOOP_HOME/sbin/hadoop-daemons.sh --config $HADOOP_CONF_DIR --script hdfs stop datanode$ $HADOOP_HOME/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs stop namenode |
Обратите внимание, что сначала все DataNodes должны быть остановлены. NameNode останавливается после завершения работы всех узлов данных.
3. HDFS
3.1. Архитектура HDFS
HDFS (распределенная файловая система Hadoop), как уже сказано в названии, является распределенной файловой системой, работающей на обычном оборудовании. Как и другие распределенные файловые системы, он обеспечивает доступ к файлам и каталогам, которые хранятся на разных компьютерах в сети, прозрачно для пользовательского приложения. Но в отличие от других аналогичных решений, HDFS делает несколько предположений, которые не столь распространены:
- Отказ оборудования рассматривается скорее как норма, чем как исключение. Вместо того, чтобы полагаться на дорогие отказоустойчивые аппаратные системы, выбирается стандартное оборудование. Это не только уменьшает затраты на установку всего кластера, но и позволяет легко заменить неисправное оборудование.
- Поскольку Hadoop предназначен для пакетной обработки больших наборов данных, требования, вытекающие из более ориентированного на пользователя стандарта POSIX, смягчены. Следовательно, доступ с низкой задержкой к произвольным частям файла менее желателен, чем потоковые файлы с высокой пропускной способностью.
- Приложения, использующие Hadoop, обрабатывают большие наборы данных, которые находятся в больших файлах. Следовательно, Hadoop настроен на обработку больших файлов вместо множества маленьких файлов.
- Большинство приложений для работы с большими данными записывают данные один раз и часто их читают (файлы журналов, HTML-страницы, предоставленные пользователем изображения и т. Д.). Поэтому Hadoop предполагает, что файл один раз создается, а затем никогда не обновляется. Это упрощает модель когерентности и обеспечивает высокую пропускную способность.
В HDFS существует два разных типа серверов: NameNodes и DataNodes. Хотя существует только один NameNode, количество DataNode не ограничено.
NameNode обслуживает все операции метаданных в файловой системе, такие как создание, открытие, закрытие или переименование файлов и каталогов. Поэтому он управляет полной структурой файловой системы. Внутренне файл разбивается на один или несколько блоков данных, и эти блоки данных хранятся в одном или нескольких узлах данных. Знание о том, какие блоки данных образуют конкретный файл, находится в NameNode, следовательно, клиент получает список блоков данных из NameNode и может впоследствии напрямую связаться с DataNode для чтения или записи данных.
Тот факт, что весь кластер имеет только один NameNode, делает всю архитектуру очень простой, но также вводит одну точку отказа (SPOF). До Hadoop 2.0 не было возможности запустить два узла NameN в режиме отработки отказа, то есть, когда один узел NameN не работал из-за сбоя машины или из-за операции обслуживания, весь кластер не работал. Более новые версии Hadoop позволяют запускать два экземпляра NameNode в активной / пассивной конфигурации с горячим резервированием. В качестве требования для этой конфигурации предполагается, что на обоих компьютерах, на которых работают серверы NameNodes, должно быть одинаковое оборудование и общее хранилище (которое снова должно быть доступно).
HDFS использует традиционную иерархическую файловую систему. Это означает, что данные находятся в файлах, которые сгруппированы в каталоги. Можно создавать и удалять файлы и каталоги и перемещать файлы из одного каталога в другой. В отличие от других файловых систем, HDFS в настоящее время не поддерживает жесткие или программные ссылки.
Репликация данных является ключевым элементом отказоустойчивости в HDFS. Коэффициент репликации файла определяет, сколько копий этого файла должно храниться в кластере. Как эти реплики распределяются по кластеру, определяется политикой репликации. Текущая политика по умолчанию пытается сохранить одну реплику блока в той же локальной стойке, что и исходная, и вторую реплику в другой удаленной стойке.
Если должна быть другая реплика, она будет храниться в той же удаленной стойке, что и вторая реплика. Поскольку пропускная способность сети между узлами, работающими в одной стойке, как правило, больше, чем между разными стойками (которые должны проходить через коммутаторы), эта политика позволяет приложениям считывать все реплики из одной стойки и тем самым не использовать сетевые коммутаторы, которые соединяют стеллажи. Основное предположение здесь состоит в том, что сбой в стойке гораздо менее вероятен, чем сбой узла.
Вся информация о пространстве имен HDFS хранится в NameNode и хранится в памяти. Изменения в этой структуре данных записываются как записи в журнал транзакций с именем EditLog. Этот EditLog хранится как обычный файл в файловой системе операционной системы, в которой работает NameNode. Использование журнала транзакций для записи всех изменений позволяет восстановить эти изменения в случае сбоя NameNode. Следовательно, когда NameNode запускается, он считывает журнал транзакций с локального диска и применяет все сохраненные в нем изменения к последней версии пространства имен.
Как только все изменения будут применены, он сохраняет обновленную структуру данных в локальной файловой системе в файле с именем FsImage. После этого журнал транзакций можно удалить, так как он был применен, и его информация была сохранена в последнем файле FsImage. С этого момента все последующие изменения снова сохраняются в новом журнале транзакций. Процесс применения журнала транзакций к более старой версии FsImage и последующей замены его последней версии называется «контрольной точкой». В настоящее время такие контрольные точки выполняются только при запуске NameNode.
Узлы данных хранят блоки в своей локальной файловой системе и распределяют файлы по каталогам, чтобы локальная файловая система могла эффективно с ними справляться. При запуске DataNode сканирует структуру локальной файловой системы и затем отправляет список всех блоков, которые он хранит, в NameNode (BlockReport).
HDFS устойчива к нескольким типам сбоев:
- Ошибка DataNode: каждый DataNode время от времени отправляет сообщение пульса в NameNode. Если NameNode не получает пульса в течение определенного периода времени от DataNode, узел считается мертвым, и дальнейшие операции для него не запланированы. Мертвый DataNode уменьшает коэффициент репликации сохраненных блоков данных. Чтобы предотвратить потерю данных, NameNode может запустить новые процессы репликации, чтобы увеличить коэффициент репликации для этих блоков.
- Сетевые разделы: если кластер разбивается на два или более разделов, NameNode теряет соединение с набором DataNodes. Эти узлы данных считаются мертвыми, и дальнейшие операции ввода-вывода для них не запланированы.
- Целостность данных: когда клиент загружает данные в файловую систему, он вычисляет контрольную сумму для каждого блока данных. Эта контрольная сумма хранится в скрытом файле в том же пространстве имен. Если тот же файл читается позже, клиент, считывающий блоки данных, также извлекает скрытый файл и сравнивает контрольные суммы с теми, которые он вычисляет для полученных блоков.
- Ошибка NameNode: поскольку NameNode является единственной точкой отказа, очень важно, чтобы его данные (EditLog и FsImage) могли быть восстановлены. Поэтому можно настроить хранение более одной копии файлов EditLog и FsImage. Хотя это уменьшает скорость, с которой NameNode может обрабатывать операции, одновременно обеспечивается наличие нескольких копий критических файлов.
3.2. HDFS Руководство пользователя
HDFS могут быть доступны по-разному. Помимо Java API и оболочки C вокруг этого API, дистрибутив также поставляется с оболочкой, в которой есть команды, похожие на другие известные оболочки, такие как bash или csh.
Следующая команда показывает, как вывести список всех файлов в корневом каталоге:
|
1
2
3
4
|
[hdfs@m1 ~]$ hdfs dfs -ls /Found 2 itemsdrwxr-xr-x - hdfs hdfs 0 2016-01-01 09:13 /appsdrwx------ - hdfs hdfs 0 2016-01-01 08:22 /user |
Новый каталог можно создать, указав -mkdir качестве третьего параметра и имя каталога в качестве четвертого параметра:
|
1
2
3
4
5
6
|
[hdfs@m1 ~]$ hdfs dfs -mkdir /foo[hdfs@m1 ~]$ hdfs dfs -ls /Found 3 itemsdrwxr-xr-x - hdfs hdfs 0 2015-08-06 09:13 /appsdrwxr-xr-x - hdfs hdfs 0 2016-01-18 07:02 /foodrwx------ - hdfs hdfs 0 2015-07-21 08:22 /user |
Команды -put и -put можно использовать для загрузки или загрузки файла из файловой системы:
|
1
2
3
4
5
6
7
8
|
[hdfs@m1 ~]$ echo "Hello World" > /tmp/helloWorld.txt[hdfs@m1 ~]$ hdfs dfs -put /tmp/helloWorld.txt /foo/helloWorld.txt[hdfs@m1 ~]$ hdfs dfs -get /foo/helloWorld.txt /tmp/helloWorldDownload.txt[hdfs@m1 ~]$ cat /tmp/helloWorldDownload.txtHello World[hdfs@m1 ~]$ hdfs dfs -ls /fooFound 1 items-rw-r--r-- 3 hdfs hdfs 12 2016-01-01 18:04 /foo/helloWorld.txt |
Теперь, когда мы увидели, как составлять список файлов с помощью оболочки HDFS, пришло время реализовать простую команду -ls в Java. Поэтому мы создаем простой проект maven и добавляем следующую строку в pom.xml :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
<properties> <hadoop.version>2.7.1</hadoop.version></properties><dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency></dependencies><build> <plugins> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <archive> <manifest> <mainClass>ultimate.hdfs.HdfsClient</mainClass> </manifest> </archive> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <finalName>${project.artifactId}-${project.version}</finalName> <appendAssemblyId>true</appendAssemblyId> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins></build> |
Строки выше говорят maven использовать версию 2.7.1 клиентской библиотеки Hadoop. Код для перечисления содержимого произвольного каталога, предоставленного в командной строке, выглядит следующим образом:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
public class HdfsClient { public static void main(String[] args) throws IOException { if (args.length < 1) { System.err.println("Please provide the HDFS path (hdfs://hosthdfs:port/path)"); return; } String hadoopConf = System.getProperty("hadoop.conf"); if (hadoopConf == null) { System.err.println("Please provide the system property hadoop.conf"); return; } Configuration conf = new Configuration(); conf.addResource(new Path(hadoopConf + "/core-site.xml")); conf.addResource(new Path(hadoopConf + "/hdfs-site.xml")); conf.addResource(new Path(hadoopConf + "/mapred-site.xml")); conf.set("fs.hdfs.impl", org.apache.hadoop.hdfs.DistributedFileSystem.class.getName()); conf.set("fs.file.impl", org.apache.hadoop.fs.LocalFileSystem.class.getName()); FileSystem fileSystem = FileSystem.get(conf); RemoteIterator<LocatedFileStatus> iterator = fileSystem.listFiles(new Path(args[0]), false); while (iterator.hasNext()) { LocatedFileStatus fileStatus = iterator.next(); Path path = fileStatus.getPath(); System.out.println(path); } }} |
После проверки наличия необходимого аргумента в командной строке создается объект Configuration . Это заполнено доступными ресурсами Hadoop. Кроме того, свойства fs.hdfs.impl и fs.file.impl устанавливаются так, как это может случиться при использовании плагина сборки, что значения переопределяются. Наконец, объект FileSystem извлекается из статического метода get() и listFiles() его метод listFiles() . Итерация по возвращенным записям обеспечивает список файлов в данном каталоге:
|
1
2
|
$ java -Dhadoop.conf=/opt/hadoop/hadoop-2.7.1/etc/hadoop/ -jar target/hdfs-client-0.0.1-SNAPSHOT-jar-with-dependencies.jar hdfs://localhost:9000/foohdfs://m1:9000/foo/helloWorld.txt |
4. MapReduce
4.1. MapReduce Архитектура
Распределенная файловая система для хранения огромных объемов данных становится необходимой для анализа этих данных. MapReduce — это такая структура, которая была впервые описана Джеффри Дином и Санджаем Гемаватом (оба работают в Google). В основном он состоит из двух функций: Map и Reduce .
Функция Map принимает в качестве входных данных пару ключ / значение и вычисляет промежуточную пару ключ / значение. Ключ и значение промежуточной пары могут полностью отличаться от тех, которые передаются в функцию, единственное, что нужно учитывать, — это то, что инфраструктура MapReduce сгруппирует промежуточные значения с одним и тем же ключом.
Функция Reduce берет одну клавишу из промежуточных клавиш и все значения, которые принадлежат этой клавише, и вычисляет выходное значение для этого списка значений. Поскольку список значений может стать довольно большим, платформа предоставляет для них итератор, так что не все значения должны быть загружены в память.
Интересным моментом этой концепции является то, что функции Map и Reduce сохраняют состояния. Таким образом, фреймворк может создать произвольное количество экземпляров для каждой функции и позволить им работать одновременно. В сочетании с файловой системой HDFS это дает возможность запускать на каждом DataNode экземпляр Map который обрабатывает данные, хранящиеся на этом локальном DataNode.
Без необходимости переноса входных данных на внешний компьютер обработка данных может происходить в том же месте, где находятся данные. Кроме того, промежуточные результаты также могут храниться в виде файлов в файловой системе HDFS и, следовательно, использоваться заданиями Reduce . Все вместе вся структура может масштабироваться до огромных объемов данных, поскольку с каждым добавленным в кластер DataNode также становятся доступными новые вычислительные возможности, которые могут обрабатывать эти данные, хранящиеся на этом новом узле.
Очень простой пример для лучшего понимания подхода MapReduce — это вариант использования подсчета слов. В этом случае мы предполагаем, что у нас есть сотни текстовых файлов и что мы хотим вычислить, как часто каждое слово появляется в этих текстах. Идея, как решить эту проблему с помощью инфраструктуры MapReduce, заключается в реализации функции Map которая принимает в качестве входных данных имя текстового файла в качестве ключа и содержимое этого файла в качестве значения (name / content):
|
1
2
3
|
map(String key, String value): for word in value: submitIntermediate(word, 1) |
Каждый вызов submitIntermediate() создает промежуточную пару ключ / значение со словом в качестве ключа и значением «one»:
|
1
2
3
4
5
6
|
"Hello"/1"World"/1..."Hello"/1"World"/1... |
Поскольку инфраструктура MapReduce теперь группирует все промежуточные пары ключ / значение по ключу, все пары ключ / значение для ключа «World» передаются в функцию Reduce . Эта функция теперь имеет задачу только подсчитать количество значений «один»:
|
1
2
3
4
5
|
reduce(String key, Iterator values): result = 0 for value in values: result += v submitFinal(result) |
Окончательный результат будет выглядеть следующим образом:
|
1
2
3
|
"Hello"/2"World"/2... |
Иногда имеет смысл ввести дополнительную фазу после функции Map которая вызывается на том же узле и которая уже группирует все пары промежуточных ключей / значений с одним и тем же ключом перед их передачей в функцию Reduce . Эта фаза часто называется фазой Combine и в приведенном выше примере будет реализована аналогично функции reduce .
Цель этого дополнительного этапа — уменьшить объем данных, передаваемых от одного узла к другому, поскольку на практике все значения с одним и тем же ключом должны передаваться на узел, который выполняет функцию Reduce для этого ключа. В нашем примере выше могут быть сотни промежуточных («Hello» / 1) пар, которые должны быть переданы на узел Reduce обрабатывающий ключ «Hello». Если Combine шаг Combine уже уменьшил бы их, только одна пара из каждого узла Map для ключа «Hello» должна была бы быть перенесена в узел Reduce .
Хотя транспортировка промежуточных пар ключ / значение в узлы Reduce и их объединение в один список для каждого ключа является частью структуры, часто упоминается, что она имеет фазу Shuffle . Следовательно, этот этап может быть реализован и оптимизирован один раз для всех видов использования.
4.2. Пример MapReduce
Теперь, когда мы изучили основы инфраструктуры MapReduce, пришло время реализовать простой пример. В этом уроке мы собираемся создать «инвертированный индекс» из пары текстовых файлов. «Инвертированный индекс» означает, что мы создаем для каждого слова список текстовых файлов, в которых оно встречается. Этот вид индекса используется поисковыми системами, такими как Google, Elasticsearch или Solr, для поиска всех страниц, которые указаны для поискового запроса. В реальных условиях упорядочение списка является наиболее важной работой, так как мы ожидаем, что наиболее «релевантные» страницы будут перечислены первыми. В этом примере мы, конечно, реализуем только первый базовый шаг, который сканирует набор текстовых файлов и создает для него соответствующий «инвертированный индекс».
Мы начнем с создания проекта maven в командной строке (и предположим, что maven настроен правильно):
|
1
|
mvn archetype:create -DgroupId=ultimate-tutorials -DartifactId=mapreduce-example |
Это создаст следующую структуру в файловой системе:
|
1
2
3
4
5
6
7
8
|
|-- src| |-- main| | `-- java| | `-- ultimatetutorials| `-- test| | `-- java| | `-- ultimatetutorials`-- pom.xml |
Мы добавляем следующие строки в файл pom.xml :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.1</version> </dependency></dependencies><build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> <configuration> <archive> <manifest> <mainClass>ultimatetutorial.InvertedIndex</mainClass> </manifest> </archive> </configuration> </plugin> </plugins></build> |
Раздел dependencies определяет артефакты maven, которые мы будем использовать (здесь: библиотека hadoop-client в версии 2.7.1). Чтобы запустить наше приложение без указания основного класса в командной строке, мы определяем основной класс с помощью maven-jar-plugin .
Этот основной класс выглядит следующим образом:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
public class InvertedIndex { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "inverted index"); job.setJarByClass(InvertedIndex.class); job.setMapperClass(InvertedIndexMapper.class); job.setCombinerClass(InvertedIndexReducer.class); job.setReducerClass(InvertedIndexReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); }} |
После создания объекта Configuration создается новый экземпляр Job , передавая конфигурацию и имя задания. Далее мы указываем класс, который реализует задание MapReduce а также классы, которые реализуют Mapper , Combiner и Reducer . Поскольку шаг Combiner — это в основном только шаг Reduce который выполняется локально, мы выбираем тот же класс, что и для шага Reducer . Теперь необходимо задание MapReduce того типа, какой выходной ключ и значения. Поскольку мы собираемся предоставить список документов для каждого термина, мы выбираем класс Text . Наконец, мы предоставляем путь для входных и выходных документов и запускаем работу, вызывая waitForCompletion .
На шаге Map нашей реализации MapReduce мы собираемся разбить входной документ на термины и создать промежуточные пары ключ / значение в форме (термин / документ):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
public class InvertedIndexMapper extends Mapper<Object, Text, Text, Text> { private static final Log LOG = LogFactory.getLog(InvertedIndexMapper.class); @Override protected void map(Object key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer tokenizer = new StringTokenizer(value.toString(), ".,; \\t\\n?!\\"/()[]$%"); while (tokenizer.hasMoreTokens()) { String token = tokenizer.nextToken(); Text keyOut = new Text(token); String fileName = ((FileSplit) context.getInputSplit()).getPath().toString(); Text valueOut = new Text(fileName); LOG.info("Key/Value: " + keyOut + "/" + valueOut); context.write(keyOut, valueOut); } }} |
Реализация mapper в основном подклассирует класс Mapper и переопределяет метод map() . В этом методе значение (т. Е. Документ) разбивается на токены, и каждый токен записывается в Context как ключ. Создание токенов с помощью StringTokenizer конечно, очень простой способ, и его недостаточно для многих других типов документов, но в этом примере показано, как создавать разные ключи для одной пары ключ / значение ввода. Значением промежуточной пары ключ / значение должно быть имя файла документа, поэтому мы вызываем метод getInputSplit() в контексте, FileSplit его к FileSplit и записываем полученный путь в контекст.
Промежуточные пары ключ / значение, созданные этой реализацией Mapper , затем передаются в Reducer :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
public class InvertedIndexReducer extends Reducer<Text,Text,Text,Text> { @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { List<String> valueList = new LinkedList<String>(); for (Text value : values) { String valueAsString = new String(value.getBytes(), Charset.forName("UTF-8")); if (!valueList.contains(valueAsString)) { valueList.add(value.toString()); } } StringBuilder sb = new StringBuilder(); for (String value : valueList) { if (sb.length() > 0) { sb.append(","); } sb.append(value); } context.write(key, new Text(sb.toString())); }} |
Как и Mapper , Reducer подклассирует соответствующий класс из среды Hadoop и переопределяет метод reduce() . Этот метод reduce для каждого промежуточного ключа список значений. В нашем случае это список путей документов, которые содержат термин (ключ). Поскольку этот список может быть настолько длинным, что он не помещается в память, платформа предоставляет итератор для значений. Но в этом простом примере список документов будет достаточно коротким, чтобы мы могли хранить все пути документов в LinkedList , чтобы отфильтровать дубликаты. Выходная пара ключ / значение — это просто термин с разделенным запятыми списком документов, содержащих этот термин.
После компиляции исходного кода с помощью mvn install мы можем загрузить набор документов в HDFS. Пример проекта содержит несколько текстовых документов в папке src/test/resources которые можно загрузить в HDFS с помощью следующей команды:
|
1
|
hdfs dfs -put src/test/resources/ input |
Это создаст новую папку с именем input в домашнем каталоге пользователя hadoop (при условии, что команда выполнена как пользователь hadoop). Если папка уже существует, ее можно удалить, вызвав:
|
1
|
hdfs dfs -rm -r /user/hadoop/input |
Теперь мы можем запустить работу MapReduce:
|
1
|
hadoop jar target/mapreduce-example-0.0.1-SNAPSHOT.jar /user/hadoop/input /user/hadoop/output |
Если работа завершится успешно, мы увидим строку, похожую на следующую в выводе:
|
1
2
3
|
...INFO mapreduce.Job: Job job_local498794269_0001 completed successfully... |
Следующая команда сообщает нам, как называются выходные файлы:
|
1
2
3
4
|
hadoop@m1:~/mapreduce-example$ hdfs dfs -ls outputFound 2 items-rw-r--r-- 1 hadoop supergroup 0 2016-01-01 14:55 output/_SUCCESS-rw-r--r-- 1 hadoop supergroup 121228 2016-01-01 14:55 output/part-r-00000 |
Файл с именем _SUCCESS является только маркерным файлом и не содержит никаких данных. Фактический вывод хранится в файле part-r-00000 :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
hadoop@m1:~/mapreduce-example$ hdfs dfs -cat output/part-r-00000API hdfs://localhost:9000/user/hadoop/input/4FreeWeatherProvidersAPIToDevelopAWeatherApp.txtAPIs hdfs://localhost:9000/user/hadoop/input/WildflySwarmTowardsMaturityAndASmallContribution.txtAWS hdfs://localhost:9000/user/hadoop/input/ExampleOfUsingExtensionsInSwift.txtAbout hdfs://localhost:9000/user/hadoop/input/ExampleOfUsingExtensionsInSwift.txtAccept hdfs://localhost:9000/user/hadoop/input/RunningAnyDockerImageOnOpenshiftOrigin.txtAdd hdfs://localhost:9000/user/hadoop/input/RunningAnyDockerImageOnOpenshiftOrigin.txtAfter hdfs://localhost:9000/user/hadoop/input/RunningAnyDockerImageOnOpenshiftOrigin.txtAll hdfs://localhost:9000/user/hadoop/input/4FreeWeatherProvidersAPIToDevelopAWeatherApp.txtAlma hdfs://localhost:9000/user/hadoop/input/ExampleOfUsingExtensionsInSwift.txtAmazon hdfs://localhost:9000/user/hadoop/input/ExampleOfUsingExtensionsInSwift.txtAnd hdfs://localhost:9000/user/hadoop/input/UseJUnitsExpectedExceptionsSparingly.txt,hdfs://localhost:9000/user/hadoop/input/MicroservicesUseCases.txt... |
Как и ожидалось, этот файл теперь содержит упорядоченный список всех терминов вместе с путями к документам, которые содержат это слово. Так, например, термин «И» содержится в двух документах «UseJUnitsExpectedExceptionsSparingly.txt» и «MicroservicesUseCases.txt».
5. пряжа
5.1. ЯРН Архитектура
YARN (еще одно средство согласования ресурсов) было представлено в Hadoop с версией 2.0 и решает несколько проблем с планированием ресурсов MapReduce в версии 1.0. Чтобы понять преимущества YARN, мы должны рассмотреть, как планирование ресурсов работало в версии 1.0.
Задание MapReduce разбивается платформой на задачи (задачи Map, задачи Reducer), и каждая задача выполняется на компьютерах DataNode в кластере. Для выполнения задач каждый компьютер DataNode предоставил заранее определенное количество слотов (слотов карты, слотов редукторов). JobTracker отвечал за резервирование слотов выполнения для различных задач задания и следил за их выполнением. Если выполнение не удалось, он зарезервировал другой слот и перезапустил задачу. Он также очищает временные ресурсы и делает зарезервированный слот доступным для других задач.
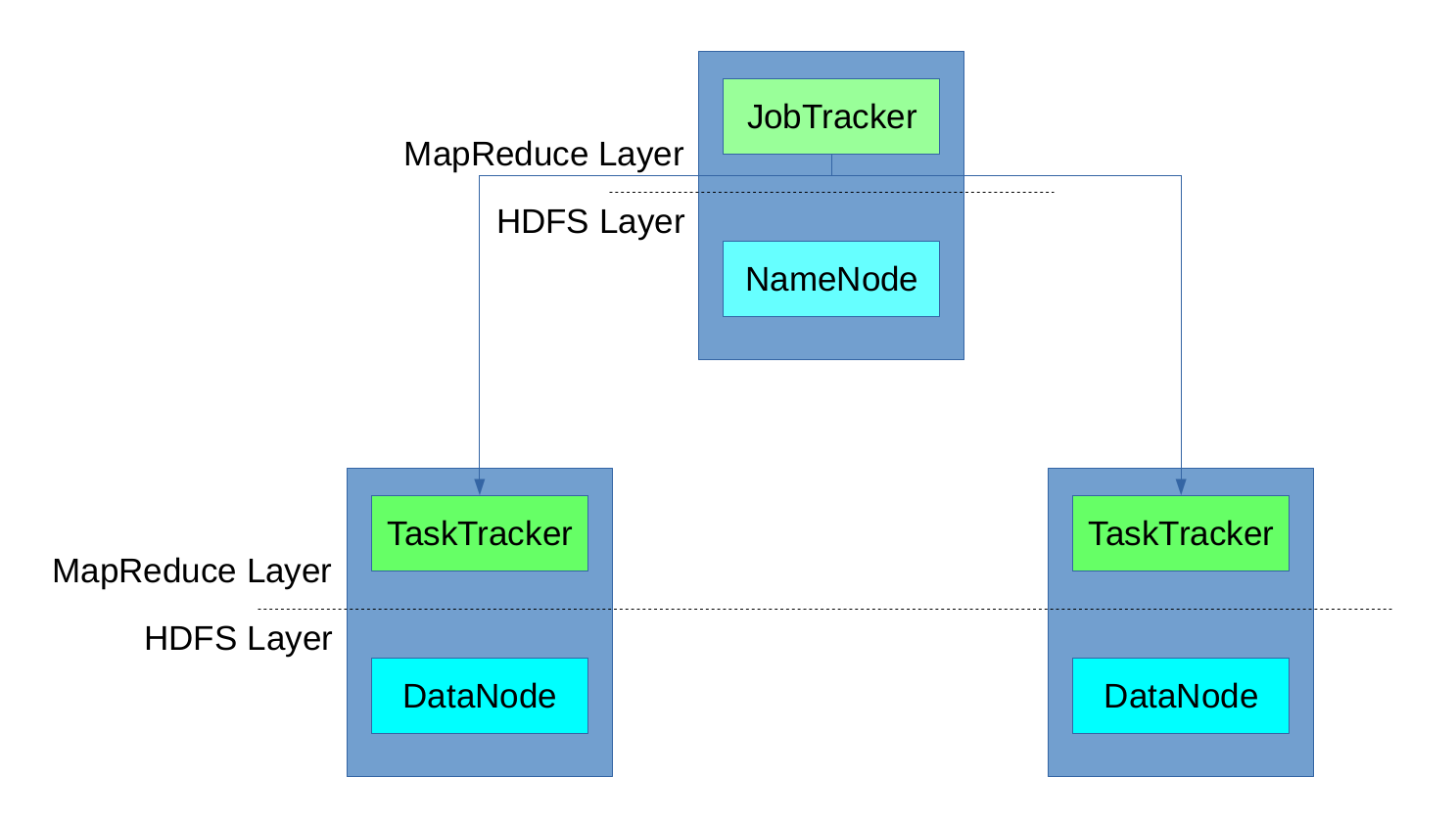
Рисунок 1: MapReduce
Тот факт, что в Hadoop 1.0 был только один экземпляр JobTracker, привел к проблеме, которая может привести к сбою всего выполнения MapReduce в случае сбоя JobTracker (единственная точка отказа). Кроме того, наличие только одного экземпляра JobTracker ограничивает масштабируемость (для очень больших кластеров с тысячами узлов).
Концепция предопределенной карты и сокращения слотов также вызывала проблемы с ресурсами в случае использования всех слотов карты, в то время как сокращение слотов все еще доступно, и наоборот. В общем, было невозможно повторно использовать инфраструктуру MapReduce для других типов вычислений, таких как задания в реальном времени. Хотя MapReduce является пакетной средой, приложения, которые хотят обрабатывать большие наборы данных, хранящиеся в HDFS, и немедленно информировать пользователя о результатах, не могут быть реализованы с его помощью. Помимо того факта, что MapReduce 1.0 не обеспечивала предоставление результатов вычислений в реальном времени, все другие типы приложений, которые хотят выполнять вычисления на данных HDFS, должны были быть реализованы как задания Map и Reduce, что не всегда было возможно.
Поэтому Hadoop 2.0 представил YARN в качестве менеджера ресурсов, который больше не использует слоты для управления ресурсами. Вместо этого узлы имеют «ресурсы» (например, ядра памяти и ЦП), которые могут быть распределены приложениями для каждого запроса. Таким образом, задания MapReduce могут выполняться вместе с заданиями, не относящимися к MapReduce, в одном кластере.
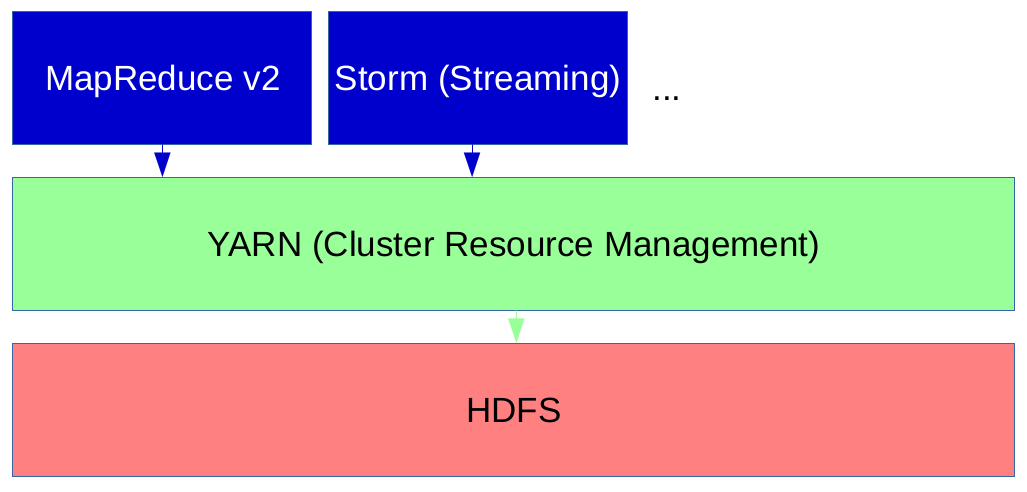
Рисунок 2: пряжа
Сердцем YARN является диспетчер ресурсов (RM), который работает на главном узле и действует как глобальный планировщик ресурсов. Он также осуществляет арбитраж ресурсов между конкурирующими приложениями. В отличие от диспетчера ресурсов, диспетчеры узлов (NM) работают на подчиненных узлах и взаимодействуют с RM. NodeManager отвечает за создание контейнеров, в которых работают приложения, следит за использованием их ЦП и памяти и сообщает о них в RM.
Каждое приложение имеет свой собственный ApplicationMaster (AM), который работает в контейнере и согласовывает ресурсы с RM и работает с NM для выполнения и мониторинга задач. Поэтому реализация MapReduce в Hadoop 2.0 поставляется с AM (называемым MRAppMaster), который запрашивает контейнеры для выполнения задач карты из RM, получает идентификаторы контейнеров из RM и затем выполняет задачи карты в предоставленных контейнерах. По завершении задач сопоставления он запрашивает новые контейнеры для выполнения задач сокращения и запускает их выполнение на предоставленных контейнерах.
Если не удается выполнить задачу, она перезапускается ApplicationMaster. В случае сбоя ApplicationMaster RM попытается перезапустить все приложение (до двух раз по умолчанию). Поэтому ApplicationMaster может сигнализировать, поддерживает ли он восстановление задания. В этом случае ApplicationMaster получает предыдущее состояние от RM и может перезапустить только незавершенные задачи.
Если происходит сбой NodeManager, т. Е. RM не получает пульса от него, он удаляется из списка активных узлов, и все его задачи рассматриваются как сбойные. В отличие от версии 1.0 Hadoop, ResourceManager можно настроить на высокую доступность.
5.2. YARN Пример
Теперь, когда мы узнали об архитектуре YARN, пришло время выполнить задание MapReduce в YARN. Поэтому мы настраиваем в файле, $HADOOP_HOME/etc/hadoop/mapred-site.xmlчто должна использоваться инфраструктура YARN:
|
1
2
3
4
5
6
|
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property></configuration> |
Затем мы добавляем следующее свойство в файл $HADOOP_HOME/etc/hadoop/yarn-site.xml:
|
01
02
03
04
05
06
07
08
09
10
|
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property></configuration> |
Теперь пришло время запустить менеджер ресурсов:
|
1
2
3
4
|
$ sbin/start-yarn.shstarting yarn daemonsstarting resourcemanager, logging to /opt/hadoop/hadoop-2.7.1/logs/yarn-hadoop-resourcemanager-m1.outlocalhost: starting nodemanager, logging to /opt/hadoop/hadoop-2.7.1/logs/yarn-hadoop-nodemanager-m1.out |
Когда мы запускаем задание MapReduce, используя YARN, результат немного отличается:
|
01
02
03
04
05
06
07
08
09
10
|
$ hadoop jar target/mapreduce-example-0.0.1-SNAPSHOT.jar input output...The url to track the job: http://m1:8088/proxy/application_1454013410608_0001/Running job: job_1454013410608_0001Job job_1454013410608_0001 running in uber mode : false map 0% reduce 0% map 86% reduce 0% map 100% reduce 0% map 100% reduce 100%Job job_1454013410608_0001 completed successfully |
Как показывают сообщения журнала, можно отслеживать задания, используя веб-интерфейс, работающий через порт 8088:

Рисунок 3: YARN RM
6. Загрузите исходный код Apache Hadoop.
Это был учебник по Apache Hadoop.