Это полезно в любое время, когда вам нужно оценить выражения, неизвестные во время компиляции, или проанализировать нетривиальный пользовательский ввод или файлы в странном формате. Конечно, для любой из этих задач можно создать собственный анализатор, созданный вручную. Однако обычно это занимает гораздо больше времени и усилий. Небольшое знание хорошего генератора парсеров может превратить эти трудоемкие задачи в простые и быстрые упражнения.
Этот пост начинается с небольшой демонстрации полезности ANTLR. Затем мы объясним, что такое ANTLR и как он работает. Наконец, мы покажем, как скомпилировать простое «Hello word!» язык в абстрактное синтаксическое дерево. В посте также объясняется, как добавить обработку ошибок и как проверить язык.
Следующий пост показывает, как создать настоящий язык выражения.
Примеры реальных слов
ANTLR, кажется, популярен в слове с открытым исходным кодом. Среди прочего, он используется Apache Camel , Apache Lucene , Apache Hadoop , Groovy и Hibernate . Все они нуждались в парсере для пользовательского языка. Например, Hibernate использует ANTLR для анализа языка запросов HQL.
Все это большие фреймворки и, следовательно, более вероятно, что потребуется язык, специфичный для предметной области, чем небольшое приложение Список небольших проектов, использующих ANTLR, доступен в его списке витрин . Мы также нашли одно обсуждение StackOverflow по этой теме.
Чтобы увидеть, где ANTLR может быть полезен и как он может сэкономить время, попробуйте оценить следующие требования:
- Добавить калькулятор формул в систему учета. Он рассчитает значения формул, таких как
(10 + 80)*sales_tax. - Добавьте расширенное поле поиска в поисковую систему рецептов. Он будет искать квитанции, соответствующие выражениям, таким как
(chicken and orange) or (no meat and carrot).
Наша надежная оценка — полтора дня, включая документацию, тесты и интеграцию в проект. ANTLR стоит посмотреть, если вы столкнулись с аналогичными требованиями и сделали значительно более высокую оценку.
обзор
ANTLR — генератор кода. Он принимает так называемый файл грамматики в качестве входных данных и генерирует два класса: лексер и парсер.
Сначала запускается Lexer и разбивает входные данные на части, называемые токенами. Каждый токен представляет более или менее значимую часть ввода. Поток токенов передается парсеру, который выполняет всю необходимую работу. Именно парсер создает абстрактное синтаксическое дерево, интерпретирует код или переводит его в какую-то другую форму.
Файл грамматики содержит все, что нужно ANTLR для генерации правильного лексера и парсера. Должен ли он генерировать классы Java или Python, генерирует ли анализатор абстрактное синтаксическое дерево, код ассемблера или напрямую интерпретирует код и так далее. Поскольку в этом руководстве показано, как построить абстрактное синтаксическое дерево, мы будем игнорировать другие параметры в следующих пояснениях.
Что наиболее важно, файл грамматики описывает, как разбить входные данные на токены и как построить дерево из токенов. Другими словами, файл грамматики содержит правила лексера и правила парсера.
Каждое правило лексера описывает один токен:
|
1
|
TokenName: regular expression; |
Правила парсера сложнее. Самая основная версия похожа на правило лексера:
|
1
|
ParserRuleName: regular expression; |
Они могут содержать модификаторы, которые определяют специальные преобразования для входных, корневых и дочерних элементов в результирующем абстрактном синтаксическом дереве или действиях, выполняемых при каждом использовании правила. Почти вся работа обычно выполняется внутри правил парсера.
инфраструктура
Сначала мы покажем инструменты, облегчающие разработку с помощью ANTLR. Конечно, ничего из того, что описано в этой главе, не нужно. Все примеры работают только с maven, текстовым редактором и подключением к интернету.
В рамках проекта ANTLR был разработан отдельный IDE , плагин Eclipse и плагин Idea . Мы не нашли плагин NetBeans.
ANTLRWorks
Автономный ide называется ANTLRWorks . Загрузите его со страницы загрузки проекта. ANTLRWorks — это отдельный файл jar, для его запуска используйте java -jar antlrworks-1.4.3.jar .
В среде IDE больше функций и она более стабильна, чем плагин Eclipse.
Eclipse Plugin
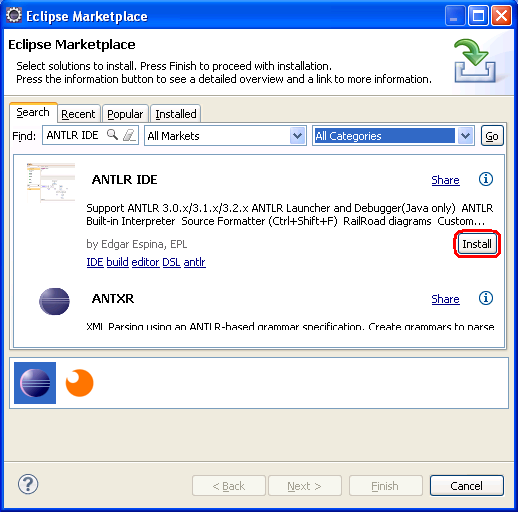
Загрузите и распакуйте ANTLR v3 со страницы загрузки ANTLR. Затем установите плагин ANTLR из Eclipse Marketplace:
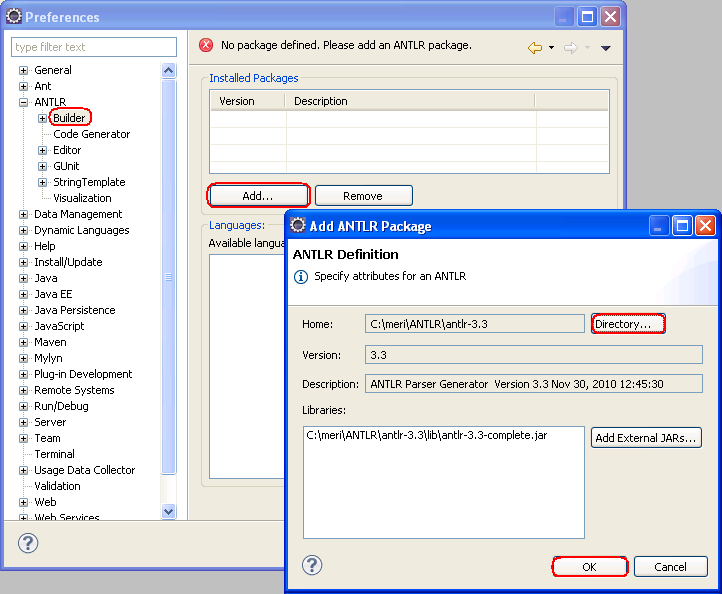
Перейдите в «Настройки» и настройте каталог установки ANTLR v3:
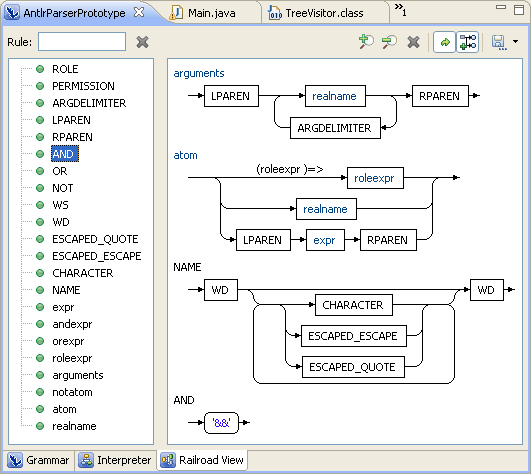
Чтобы проверить конфигурацию, загрузите образец файла грамматики и откройте его в eclipse. Он будет открыт в редакторе ANTLR. Редактор имеет три вкладки:
- Грамматика — текстовый редактор с подсветкой синтаксиса, дополнением кода и так далее.
- Интерпретатор — компилирует тестовые выражения в синтаксические деревья, может давать другой результат, чем сгенерированный парсер. Как правило, в правильных выражениях возникает исключение с ошибочным предикатом.
- Railroad View — рисует красивые графики ваших правил лексера и парсера.
Пустой проект — Конфигурация Maven
В этой главе показано, как добавить ANTLR в проект maven. Если вы используете Eclipse и у вас еще не установлен плагин m2eclipse, установите его с http://download.eclipse.org/technology/m2e/releases сайта обновления. Это сделает вашу жизнь намного проще.
Создать проект
Создайте новый проект maven и укажите maven-archetype-quickstart на экране «Выбор архетипа». Если вы не используете Eclipse, команда mvn archetype:generate достигает того же.
зависимость
Добавьте зависимость ANTLR в pom.xml :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
org.antlrantlr3.3jarcompile |
Примечание: поскольку ANTLR не имеет истории обратной совместимости, лучше указать требуемую версию.
Плагины
Плагин Antlr Maven запускается на этапе создания источников и генерирует Java-классы как лексера, так и анализатора из файлов грамматики (.g). Добавьте его в pom.xml :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
org.antlrantlr3-maven-plugin3.3 run antlr generate-sources antlr |
Создайте папку src/main/antlr3 . Плагин ожидает все файлы грамматики там.
Сгенерированные файлы помещаются в каталог target/generated-sources/antlr3 . Поскольку этот каталог не находится по умолчанию в пути сборки maven, мы используем build-helper-maven-plugin, чтобы добавить его туда:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
org.codehaus.mojobuild-helper-maven-plugin add-source generate-sources add-source ${basedir}/target/generated-sources/antlr3 |
Если вы используете eclipse, вам необходимо обновить конфигурацию проекта: щелкните правой кнопкой мыши проект -> ‘maven’ -> ‘Обновить конфигурацию проекта’.
Попробуй это
Вызовите maven для проверки конфигурации проекта: щелкните правой кнопкой мыши проект -> «Запуск от имени» -> «Maven generate-sources». В качестве альтернативы используйте mvn generate-sources .
Сборка должна быть успешной. Вывод консоли должен содержать вывод плагина antlr3-maven-plugin:
|
1
2
3
4
|
[INFO] --- antlr3-maven-plugin:3.3:antlr (run antlr) @ antlr-step-by-step ---[INFO] ANTLR: Processing source directory C:\meri\ANTLR\workspace\antlr-step-by-step\src\main\antlr3[INFO] No grammars to processANTLR Parser Generator Version 3.3 Nov 30, 2010 12:46:29 |
За ним должен следовать вывод плагина build-helper-maven-plugin:
|
1
2
|
[INFO] --- build-helper-maven-plugin:1.7:add-source (add-source) @ antlr-step-by-step ---[INFO] Source directory: C:\meri\ANTLR\workspace\antlr-step-by-step\target\generated-sources\antlr3 added. |
Результат этого этапа находится на github, тег 001-config_antlr .
Привет слово
Мы создадим простейший возможный языковой парсер — привет парсер слов. Он строит небольшое абстрактное синтаксическое дерево из одного выражения: «Hello word!».
Мы будем использовать его, чтобы показать, как создать файл грамматики и создать из него классы ANTLR. Затем мы покажем, как использовать сгенерированные файлы и создать модульный тест.
Первый файл грамматики
Antlr3-maven-plugin ищет файлы грамматики в каталоге src/main/antlr3 . Он создает новый пакет для каждого подкаталога с грамматикой и генерирует в него классы синтаксического анализатора и лексера. Поскольку мы хотим создавать классы в пакете org.meri.antlr_step_by_step.parsers , нам нужно создать src/main/antlr3/org/meri/antlr_step_by_step/parsers .
Имя грамматики и имя файла должны быть идентичны. Файл должен иметь суффикс .g. Более того, каждый файл грамматики начинается с объявления имени грамматики. Наша грамматика S001HelloWord начинается со следующей строки:
|
1
|
grammar S001HelloWord; |
за восклицанием всегда следуют варианты генератора. Мы работаем над проектом Java и хотим скомпилировать выражения в абстрактное синтаксическое дерево:
|
1
2
3
4
5
6
|
options { // antlr will generate java lexer and parser language = Java; // generated parser should create abstract syntax tree output = AST;} |
Antlr не генерирует объявление пакета поверх сгенерированных классов. Мы должны использовать @parser::header и @lexer::header чтобы обеспечить его соблюдение. Заголовки должны следовать за блоком параметров:
|
1
2
3
4
5
6
7
|
@lexer::header { package org.meri.antlr_step_by_step.parsers;}@parser::header { package org.meri.antlr_step_by_step.parsers;} |
Каждый файл грамматики должен иметь хотя бы одно правило лексера. Каждое правило лексера должно начинаться с заглавной буквы. У нас есть два правила: первое определяет токен приветствия, второе определяет маркер эндсимвола. Приветствие должно быть «Hello word», а символ конца должен быть «!».
|
1
2
|
SALUTATION:'Hello word'; ENDSYMBOL:'!'; |
Точно так же каждый файл грамматики должен иметь хотя бы одно правило синтаксического анализа. Каждое правило синтаксического анализатора должно начинаться со строчной буквы. У нас есть только одно правило синтаксического анализа: любое выражение в нашем языке должно состоять из приветствия, за которым следует символ конца.
|
1
|
expression : SALUTATION ENDSYMBOL; |
Примечание: порядок элементов файла грамматики фиксирован. Если вы измените его, плагин antlr потерпит неудачу.
Генерация лексера и парсера
Сгенерируйте лексер и парсер из командной строки с помощью команды mvn generate-sources или из Eclipse:
- Щелкните правой кнопкой мыши по проекту.
- Нажмите «Выполнить как».
- Нажмите «Maven генерировать источники».
Плагин Antlr создаст папку target / generate-sources / antlr / org / meri / antlr_step_by_step / parsers и поместит в нее файлы S001HelloWordLexer.java и S001HelloWordParser.java.
Используйте Lexer и Parser
Наконец, мы создаем класс компилятора. У него есть только один публичный метод, который:
- вызывает сгенерированный лексер для разделения ввода на токены,
- вызывает сгенерированный парсер для сборки AST из токенов,
- выводит дерево результатов AST в консоль,
- возвращает абстрактное синтаксическое дерево.
Компилятор находится в классе S001HelloWordCompiler :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
public CommonTree compile(String expression) { try { //lexer splits input into tokens ANTLRStringStream input = new ANTLRStringStream(expression); TokenStream tokens = new CommonTokenStream( new S001HelloWordLexer( input ) ); //parser generates abstract syntax tree S001HelloWordParser parser = new S001HelloWordParser(tokens); S001HelloWordParser.expression_return ret = parser.expression(); //acquire parse result CommonTree ast = (CommonTree) ret.tree; printTree(ast); return ast; } catch (RecognitionException e) { throw new IllegalStateException("Recognition exception is never thrown, only declared."); } |
Примечание. Не беспокойтесь об исключении RecognitionException, объявленном в S001HelloWordParser.expression() . Это никогда не брошено.
Тестирование Это
Мы заканчиваем эту главу небольшим тестовым примером для нашего нового компилятора. Создайте класс S001HelloWordTest :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public class S001HelloWordTest { /** * Abstract syntax tree generated from "Hello word!" should have an * unnamed root node with two children. First child corresponds to * salutation token and second child corresponds to end symbol token. * * Token type constants are defined in generated S001HelloWordParser * class. */ @Test public void testCorrectExpression() { //compile the expression S001HelloWordCompiler compiler = new S001HelloWordCompiler(); CommonTree ast = compiler.compile("Hello word!"); CommonTree leftChild = ast.getChild(0); CommonTree rightChild = ast.getChild(1); //check ast structure assertEquals(S001HelloWordParser.SALUTATION, leftChild.getType()); assertEquals(S001HelloWordParser.ENDSYMBOL, rightChild.getType()); }} |
Тест пройдет успешно. Он выведет абстрактное синтаксическое дерево на консоль:
|
1
2
3
|
0 null -- 4 Hello word -- 5 ! |
Грамматика в IDE
Откройте S001HelloWord.g в редакторе и перейдите на вкладку переводчика.
- Выделите правило выражения в левом верхнем углу.
- Напишите «Привет, слово!» в верхнем правом углу.
- Нажмите зеленую стрелку в левом верхнем углу.
Интерпретатор сгенерирует дерево разбора:

Копировать грамматику
Каждая новая грамматика в этом уроке основана на предыдущей. Мы составили список шагов, необходимых для копирования старой грамматики в новую. Используйте их, чтобы скопировать OldGrammar в NewGrammar:
- Скопируйте OldGrammar.g в NewGrammar.g в том же каталоге.
- Измените объявление
grammar NewGrammar;наgrammar NewGrammar; - Генерация парсера и лексера.
- Создайте новый класс NewGrammarCompiler, аналогичный предыдущему классу OldGrammarCompiler .
- Создайте новый тестовый класс NewGrammarTest, аналогичный предыдущему классу OldGrammarTest .
Ни одна задача на самом деле не завершена без соответствующей обработки ошибок. Сгенерированные классы ANTLR пытаются по возможности восстанавливаться после ошибок. Они сообщают об ошибках в консоль, но нет встроенного API для программного поиска ошибок синтаксиса.
Это может быть хорошо, если мы будем строить компилятор только из командной строки. Тем не менее, давайте предположим, что мы создаем графический интерфейс для нашего языка, или используем результат в качестве входных данных для другого инструмента. В таком случае нам нужен доступ API ко всем сгенерированным ошибкам.
В начале этой главы мы поэкспериментируем с обработкой ошибок по умолчанию и создадим для нее контрольный пример. Затем мы добавим наивную обработку ошибок, которая будет генерировать исключение при возникновении первой ошибки. Наконец, мы перейдем к «реальному» решению. Он будет собирать все ошибки во внутреннем списке и предоставлять методы для доступа к ним.
В качестве побочного продукта в главе показано, как:
- добавить пользовательское предложение catch в правила парсера ,
- добавлять новые методы и поля в сгенерированные классы ,
- переопределить сгенерированные методы .
Обработка ошибок по умолчанию
Сначала мы попытаемся разобрать различные неправильные выражения. Цель состоит в том, чтобы понять поведение обработки ошибок ANTLR по умолчанию. Мы создадим контрольный пример из каждого эксперимента. Все тестовые наборы находятся в классе S001HelloWordExperimentTest .
Выражение 1 : Hello word?
Дерево результатов очень похоже на правильное:
|
1
2
3
|
0 null -- 4 Hello word -- 5 ?<missing ENDSYMBOL> |
Консольный вывод содержит ошибки:
|
1
2
|
line 1:10 no viable alternative at character '?'line 1:11 missing ENDSYMBOL at '<eof>' |
Контрольный пример : следующий контрольный пример проходит без проблем. Не генерируется никаких исключений, и типы узлов дерева абстрактного синтаксиса такие же, как в правильном выражении.
|
01
02
03
04
05
06
07
08
09
10
|
@Test public void testSmallError() { //compile the expression S001HelloWordCompiler compiler = new S001HelloWordCompiler(); CommonTree ast = compiler.compile("Hello word?"); //check AST structure assertEquals(S001HelloWordParser.SALUTATION, ast.getChild(0).getType()); assertEquals(S001HelloWordParser.ENDSYMBOL, ast.getChild(1).getType()); } |
Выражение 2 : Bye!
Дерево результатов очень похоже на правильное:
|
1
2
3
4
5
6
7
|
0 null -- 4 <missing> -- 5 ! </missing> |
Консольный вывод содержит ошибки:
|
1
2
3
4
|
line 1:0 no viable alternative at character 'B'line 1:1 no viable alternative at character 'y'line 1:2 no viable alternative at character 'e'line 1:3 missing SALUTATION at '!' |
Контрольный пример : следующий контрольный пример проходит без проблем. Не генерируется никаких исключений, и типы узлов дерева абстрактного синтаксиса такие же, как в правильном выражении.
|
01
02
03
04
05
06
07
08
09
10
|
@Test public void testBiggerError() { //compile the expression S001HelloWordCompiler compiler = new S001HelloWordCompiler(); CommonTree ast = compiler.compile("Bye!"); //check AST structure assertEquals(S001HelloWordParser.SALUTATION, ast.getChild(0).getType()); assertEquals(S001HelloWordParser.ENDSYMBOL, ast.getChild(1).getType()); } |
Выражение 3 : Incorrect Expression
В дереве результатов есть только корневой узел без дочерних элементов:
|
1
|
0 |
Консольный вывод содержит много ошибок:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
line 1:0 no viable alternative at character 'I'line 1:1 no viable alternative at character 'n'line 1:2 no viable alternative at character 'c'line 1:3 no viable alternative at character 'o'line 1:4 no viable alternative at character 'r'line 1:5 no viable alternative at character 'r'line 1:6 no viable alternative at character 'e'line 1:7 no viable alternative at character 'c'line 1:8 no viable alternative at character 't'line 1:9 no viable alternative at character ' 'line 1:10 no viable alternative at character 'E'line 1:11 no viable alternative at character 'x'line 1:12 no viable alternative at character 'p'line 1:13 no viable alternative at character 'r'line 1:14 no viable alternative at character 'e'line 1:15 no viable alternative at character 's'line 1:16 no viable alternative at character 's'line 1:17 no viable alternative at character 'i'line 1:18 no viable alternative at character 'o'line 1:19 no viable alternative at character 'n'line 1:20 mismatched input '<EOF>' expecting SALUTATION |
Тестовый пример : мы наконец нашли выражение, которое приводит к разной древовидной структуре.
|
1
2
3
4
5
6
7
8
9
|
@Test public void testCompletelyWrong() { //compile the expression S001HelloWordCompiler compiler = new S001HelloWordCompiler(); CommonTree ast = compiler.compile("Incorrect Expression"); //check AST structure assertEquals(0, ast.getChildCount()); } |
Обработка ошибок в Lexer
Каждое правило лексера ‘RULE’ соответствует методу mRULE в сгенерированном лексере. Например, наша грамматика имеет два правила:
|
1
2
|
SALUTATION:'Hello word'; ENDSYMBOL:'!'; |
и сгенерированный лексер имеет два соответствующих метода :
|
1
2
3
4
5
6
7
|
public final void mSALUTATION() throws RecognitionException { // ...}public final void mENDSYMBOL() throws RecognitionException { // ...} |
В зависимости от того, какое исключение выдается, лексер может или не может попытаться восстановиться после него. Однако каждая ошибка заканчивается в reportError(RecognitionException e) . Сгенерированный лексер наследует это:
|
1
2
3
|
public void reportError(RecognitionException e) { displayRecognitionError(this.getTokenNames(), e); } |
Результат: мы должны изменить метод reportError или displayRecognitionError в лексере.
Обработка ошибок в парсере
Наша грамматика имеет только одно правило синтаксического анализа ‘expression’:
|
1
|
expression SALUTATION ENDSYMBOL; |
Выражение соответствует методу expression() в сгенерированном парсере:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
public final expression_return expression() throws RecognitionException { //initialization try { //parsing } catch (RecognitionException re) { reportError(re); recover(input,re); retval.tree = (Object) adaptor.errorNode(input, retval.start, input.LT(-1), re); } finally { } //return result;} |
Если произойдет ошибка, парсер будет:
- сообщить об ошибке на консоль,
- оправиться от ошибки,
- добавить узел ошибки (вместо обычного узла) в абстрактное синтаксическое дерево.
Отчет об ошибках в синтаксическом анализаторе немного сложнее, чем отчет об ошибках в лексере:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
/** Report a recognition problem. * * This method sets errorRecovery to indicate the parser is recovering * not parsing. Once in recovery mode, no errors are generated. * To get out of recovery mode, the parser must successfully match * a token (after a resync). So it will go: * * 1. error occurs * 2. enter recovery mode, report error * 3. consume until token found in resynch set * 4. try to resume parsing * 5. next match() will reset errorRecovery mode * * If you override, make sure to update syntaxErrors if you care about that. */ public void reportError(RecognitionException e) { // if we've already reported an error and have not matched a token // yet successfully, don't report any errors. if ( state.errorRecovery ) { return; } state.syntaxErrors++; // don't count spurious state.errorRecovery = true; displayRecognitionError(this.getTokenNames(), e); } |
На этот раз у нас есть два возможных варианта:
- заменить предложение catch в методе правила синтаксического анализа собственной обработкой,
- переопределить методы парсера.
Antlr предоставляет два способа изменить сгенерированное предложение catch в парсере. Мы создадим две новые грамматики, каждая из которых демонстрирует один способ, как это сделать. В обоих случаях мы выполним анализатор при первой ошибке.
Во-первых, мы можем добавить rulecatch к правилу синтаксического анализа новой грамматики S002HelloWordWithErrorHandling:
|
1
2
3
4
5
|
expression : SALUTATION ENDSYMBOL;catch [RecognitionException e] { //Custom handling of an exception. Any java code is allowed. throw new S002HelloWordError(":(", e);} |
Конечно, нам пришлось добавить импорт исключения S002HelloWordError в блок заголовков :
|
1
2
3
4
5
6
|
@parser::header { package org.meri.antlr_step_by_step.parsers; //add imports (see full line on Github) import ... .S002HelloWordWithErrorHandlingCompiler.S002HelloWordError;} |
Класс компилятора почти такой же, как и раньше. Он объявляет новое исключение:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
public class S002HelloWordWithErrorHandlingCompiler extends AbstractCompiler { public CommonTree compile(String expression) { // no change here } @SuppressWarnings("serial") public static class S002HelloWordError extends RuntimeException { public S002HelloWordError(String arg0, Throwable arg1) { super(arg0, arg1); } }} |
Затем ANTLR заменит предложение catch по умолчанию в методе правила выражения нашей собственной обработкой :
|
01
02
03
04
05
06
07
08
09
10
11
12
|
public final expression_return expression() throws RecognitionException { //initialization try { //parsing } catch (RecognitionException re) { //Custom handling of an exception. Any java code is allowed. throw new S002HelloWordError(":(", e); } finally { } //return result;} |
Как обычно, грамматика , класс компилятора и тестовый класс доступны на Github.
В качестве альтернативы мы можем поместить правило rulecatch между блоком заголовка и первым правилом лексера. Этот метод демонстрируется в грамматике S003HelloWordWithErrorHandling :
|
1
2
3
4
5
6
7
|
//change error handling in all parser rules@rulecatch { catch (RecognitionException e) { //Custom handling of an exception. Any java code is allowed. throw new S003HelloWordError(":(", e); }} |
Мы должны добавить импорт исключения S003HelloWordError в блок заголовков:
|
1
2
3
4
5
6
|
@parser::header { package org.meri.antlr_step_by_step.parsers; //add imports (see full line on Github) import ... .S003HelloWordWithErrorHandlingCompiler.S003HelloWordError;} |
Класс компилятора точно такой же, как и в предыдущем случае. ANTLR заменит предложение по умолчанию во всех правилах синтаксического анализатора :
|
01
02
03
04
05
06
07
08
09
10
11
12
|
public final expression_return expression() throws RecognitionException { //initialization try { //parsing } catch (RecognitionException re) { //Custom handling of an exception. Any java code is allowed. throw new S003HelloWordError(":(", e); } finally { } //return result;} |
Опять же, грамматика , класс компилятора и тестовый класс доступны на Github.
К сожалению, у этого метода есть два недостатка. Во-первых, он не работает в лексере, только в парсере. Во-вторых, функция отчетов и восстановления по умолчанию работает разумным образом. Он пытается восстановиться после ошибок. Как только он начинает восстанавливаться, он не генерирует новых ошибок. Сообщения об ошибках генерируются, только если анализатор не находится в режиме восстановления после ошибок.
Нам понравилась эта функциональность, поэтому мы решили изменить только стандартную реализацию отчетов об ошибках.
Добавить методы и поля к сгенерированным классам
Мы будем хранить все ошибки лексера / парсера в приватном списке. Кроме того, мы добавим два метода в сгенерированные классы:
- hasErrors — возвращает true, если произошла хотя бы одна ошибка,
- getErrors — возвращает все сгенерированные ошибки.
Новые поля и методы добавляются в блок @members:
|
1
2
3
4
5
6
7
|
@lexer::members { //everything you need to add to the lexer}@parser::members { //everything you need to add to the parser} |
блоки членов должны быть помещены между блоком заголовка и первым правилом лексера. Пример приведен в грамматике с именем S004HelloWordWithErrorHandling :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
//add new members to generated lexer@lexer::members { //add new field private List<RecognitionException> errors = new ArrayList <RecognitionException> (); //add new method public List<RecognitionException> getAllErrors() { return new ArrayList<RecognitionException>(errors); } //add new method public boolean hasErrors() { return !errors.isEmpty(); }}//add new members to generated parser@parser::members { //add new field private List<RecognitionException> errors = new ArrayList <RecognitionException> (); //add new method public List<RecognitionException> getAllErrors() { return new ArrayList<RecognitionException>(errors); } //add new method public boolean hasErrors() { return !errors.isEmpty(); }} |
И сгенерированный лексер, и сгенерированный парсер содержат все поля и методы, записанные в блоке members.
Переопределение сгенерированных методов
Чтобы переопределить сгенерированный метод, сделайте то же самое, что и для добавления нового, например, добавьте его в блок @members:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
//override generated method in lexer@lexer::members { //override method public void reportError(RecognitionException e) { errors.add(e); displayRecognitionError(this.getTokenNames(), e); }}//override generated method in parser@parser::members { //override method public void reportError(RecognitionException e) { errors.add(e); displayRecognitionError(this.getTokenNames(), e); }} |
Метод reportError теперь переопределяет поведение по умолчанию в лексере и парсере .
Собирать ошибки в компиляторе
Наконец, мы должны изменить наш класс компилятора. Новая версия собирает все ошибки после фазы анализа ввода:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
private List<RecognitionException> errors = new ArrayList<RecognitionException>();public CommonTree compile(String expression) { try { ... init lexer ... ... init parser ... ret = parser.expression(); //collect all errors if (lexer.hasErrors()) errors.addAll(lexer.getAllErrors()); if (parser.hasErrors()) errors.addAll(parser.getAllErrors()); //acquire parse result ... as usually ... } catch (RecognitionException e) { ... }} /*** @return all errors found during last run*/public List<RecognitionException> getAllErrors() { return errors;} |
Мы должны собирать ошибки лексера после того, как парсер завершил свою работу. Лексер вызывается из него и не содержит ошибок раньше. Как обычно, мы поместили грамматику , класс компилятора и тестовый класс на Github.
Загрузите тег 003-S002-S004HelloWordWithErrorHandling пошагового проекта antlr, чтобы найти все три метода обработки ошибок в одном и том же Java-проекте.
Ссылка: ANTLR Tutorial — Hello Word от нашего партнера по JCG Марии Юрковичовой в блоге This Is Stuff .