Itemis сделали это снова: они выпустили новый очень крутой плагин для Jetbrains MPS. Этот позволяет определять новые редакторы дерева.
Они выглядят так:
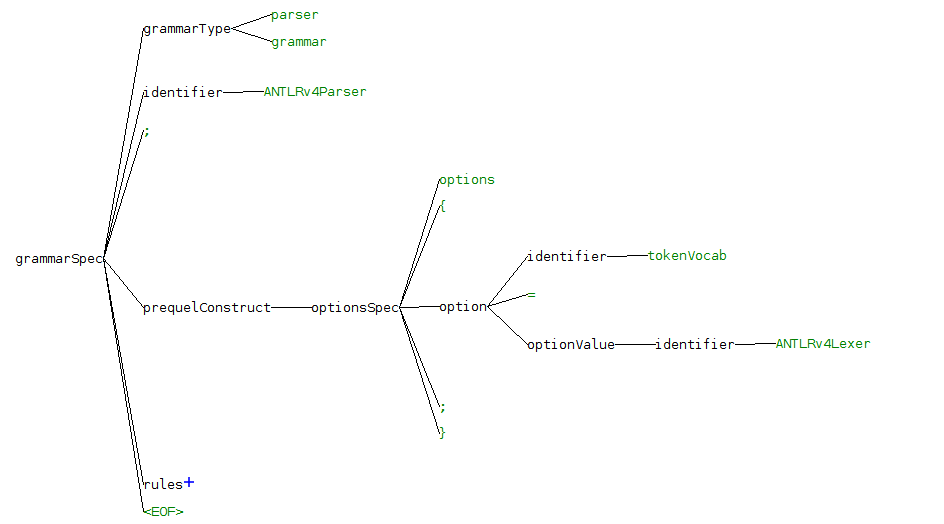
В этом посте мы увидим:
- как использовать парсеры ANTLR внутри MPS
- как представить проанализированный AST, используя обозначение дерева
В частности, мы собираемся использовать грамматику ANTLR, которая разбирает… грамматики ANTLR. Как мета это? Конечно, тот же самый подход можно использовать для каждой грамматики ANTLR.
Также всегда код доступен на GitHub .
зависимости
Прежде всего вам необходимо установить Jetbrains MPS. Возьмите свою бесплатную копию здесь .
Чтобы использовать обозначения дерева, вы должны установить платформу mbeddr. Просто зайдите сюда , скачайте zip и распакуйте его среди плагинов вашей установки MPS.
Все готово, время заняться программированием.
Упаковка ANTLR для использования внутри MPS
В предыдущем посте мы обсуждали, как использовать существующую грамматику ANTLR в проектах Java с использованием Gradle. Мы применим эту технику и здесь.
Начнем с загрузки грамматики отсюда: https://github.com/antlr/grammars-v4/tree/master/antlr4
Мы просто делаем небольшие изменения, напрямую подключая LexBasic к ANTLRv4Lexer. Обратите внимание, что нам также нужен LexerAdaptor .
Для упрощения использования мы создаем Фасад:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
package me.tomasetti.mpsantlr.parser;import me.tomassetti.antlr4.parser.ANTLRv4Lexer;import me.tomassetti.antlr4.parser.ANTLRv4Parser;import org.antlr.v4.runtime.CommonTokenStream;import org.antlr.v4.runtime.TokenStream;import java.io.*;import java.nio.charset.StandardCharsets;public class Antlr4ParserFacade { public ANTLRv4Parser.GrammarSpecContext parseString(String code) { InputStream inputStream = new ByteArrayInputStream(code.getBytes(StandardCharsets.UTF_8)); return parseStream(inputStream); } public ANTLRv4Parser.GrammarSpecContext parseFile(File file) throws FileNotFoundException { return parseStream(new FileInputStream(file)); } public ANTLRv4Parser.GrammarSpecContext parseStream(InputStream inputStream) { try { ANTLRv4Lexer lexer = new ANTLRv4Lexer(new org.antlr.v4.runtime.ANTLRInputStream(inputStream)); TokenStream tokens = new CommonTokenStream(lexer); ANTLRv4Parser parser = new ANTLRv4Parser(tokens); return parser.grammarSpec(); } catch (IOException e) { throw new RuntimeException("That is unexpected", e); } }} |
Теперь нам нужен файл сборки:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
buildscript { repositories { maven { name 'JFrog OSS snapshot repo' } jcenter() }} repositories { mavenCentral() jcenter()}apply plugin: 'java'apply plugin: 'antlr'apply plugin: 'idea'dependencies { antlr "org.antlr:antlr4:4.5.1" compile "org.antlr:antlr4-runtime:4.5.1" testCompile 'junit:junit:4.12'}generateGrammarSource { maxHeapSize = "64m" arguments += ['-package', 'me.tomassetti.antlr4.parser'] outputDirectory = new File("${project.buildDir}/generated-src/antlr/main/me/tomassetti/antlr4/parser".toString())} task fatJar(type: Jar) { manifest { attributes 'Implementation-Title': 'Antlr4-Parser', 'Implementation-Version': '0.0.1' } baseName = project.name + '-all' from { configurations.compile.collect { it.isDirectory() ? it : zipTree(it) } } with jar} |
Вы можете запустить:
- Идея Gradle для создания проекта Jetbrains IDEA
- gradle fatJar для создания Jar, который будет содержать наш скомпилированный код и все зависимости
Хороший. Теперь, чтобы использовать этот парсер в MPS, мы начнем с создания проекта. В мастере мы также выбираем параметры времени выполнения и песочницы. Как только мы это сделаем, мы должны скопировать наш толстый фляга в каталог моделей решения времени выполнения. В моем случае я запускаю из каталога проекта Java эту команду:
|
1
|
cp build/libs/parser-all.jar ../languages/me.tomassetti.mpsantlr/runtime/models/ |
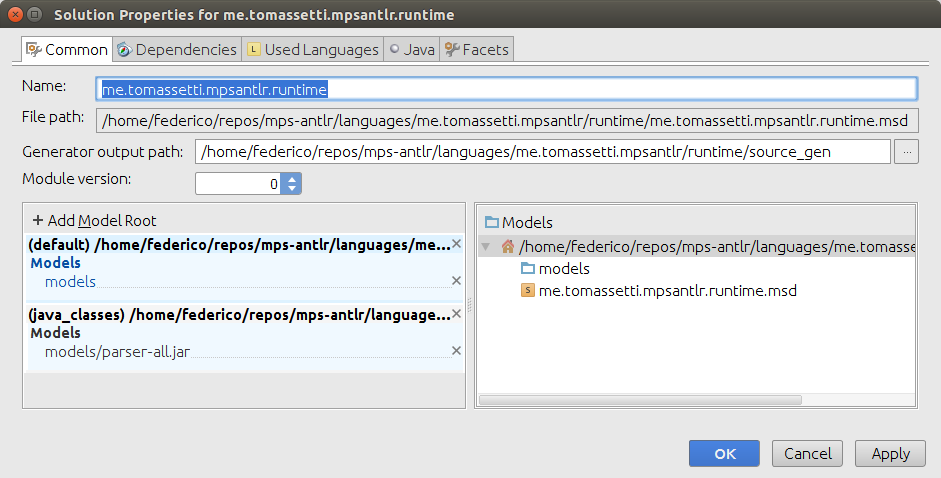
Затем мы добавляем его также в библиотеки:
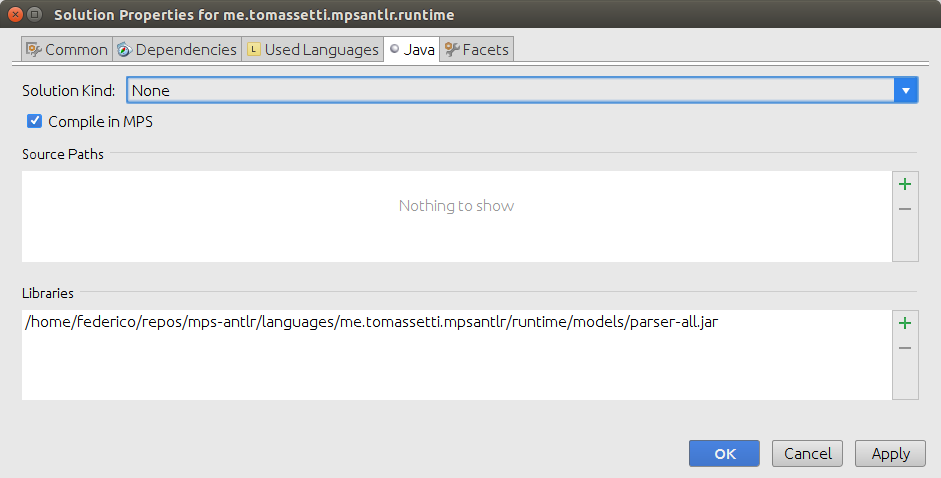
Теперь содержимое JAR должно появиться среди заглушек решения времени выполнения.
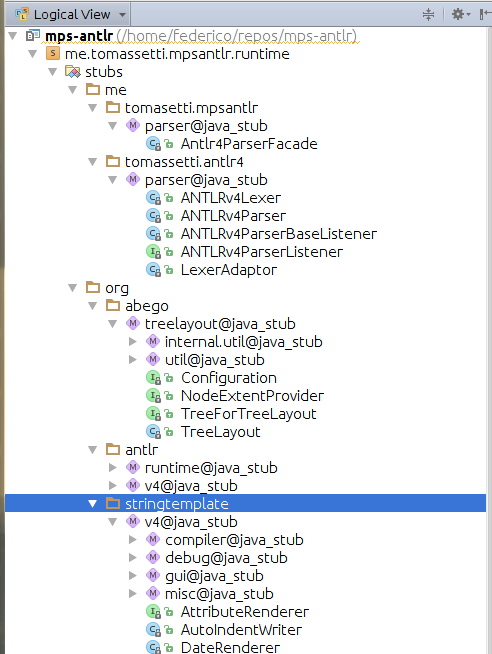
Создание узлов MPS из узлов AST
Теперь мы собираемся создать новую концепцию под названием AntlrImporter. Мы будем использовать его для выбора и импорта грамматик ANTLR в MPS:
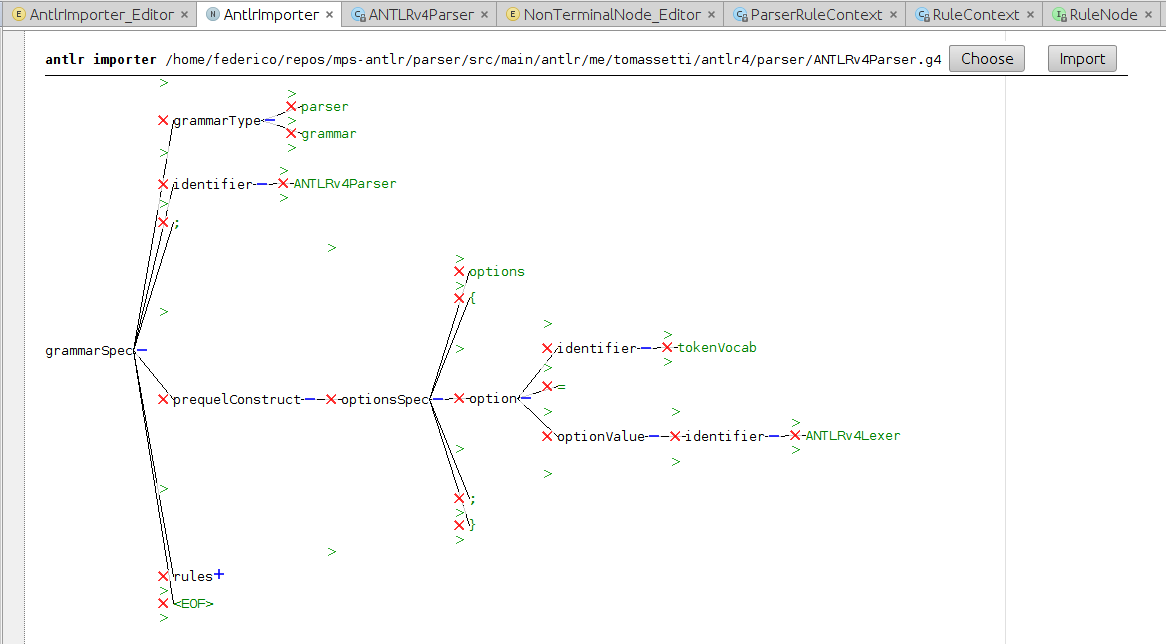
Структура Концепции будет довольно простой:
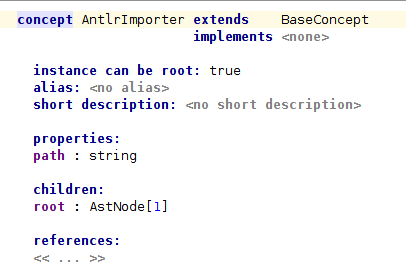
Нам также нужны концепции для узлов AST, которые мы собираемся импортировать. Прежде всего, определим абстрактное понятие AstNode . Затем мы определим две подконцепции для терминальных и нетерминальных узлов AST.
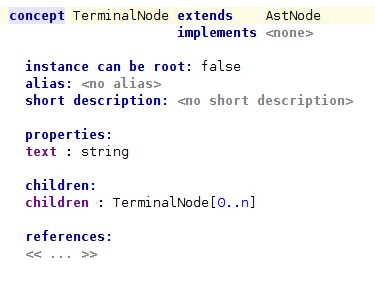
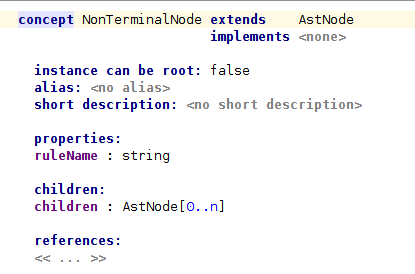
Теперь давайте посмотрим на редактор для AntlrImporter.
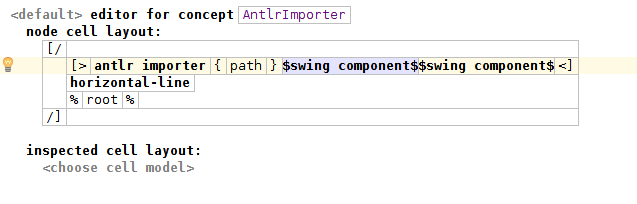
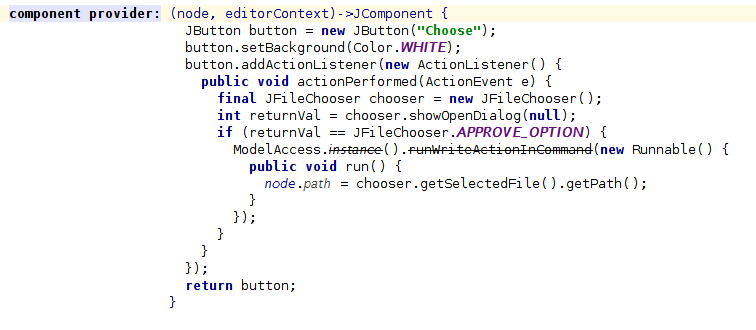
Первый компонент Swing — это кнопка, которая открывает окно выбора файлов. Таким образом, мы можем легко выбрать файл и указать путь к свойству. Или мы можем отредактировать его вручную, если захотим.
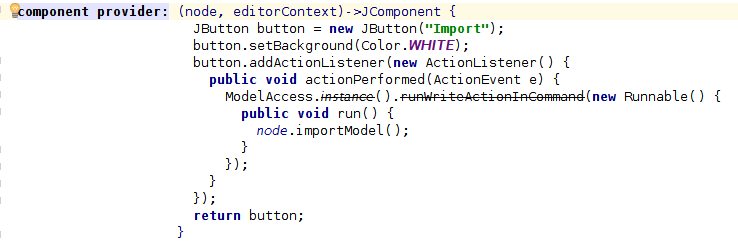
Как только мы выбрали файл, мы можем импортировать его, нажав на вторую кнопку
Логика импорта находится в importModel , метод в поведении AntlrImporter.
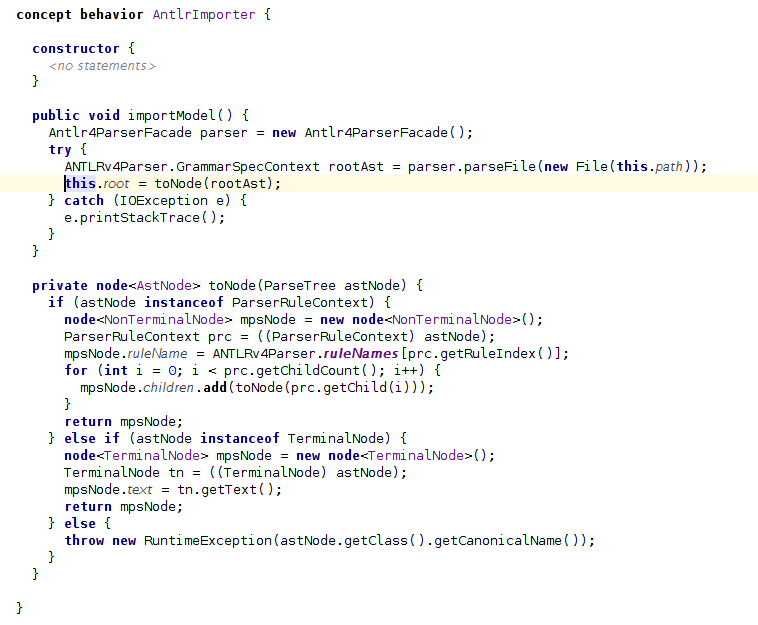
Хороший. Вот и все. При этом мы можем проанализировать любую грамматику ANTLR и получить ее в MPS. Теперь нам нужно просто использовать красивое представление. Мы собираемся для обозначения дерева.
Используя обозначение дерева
Нотация дерева удивительно проста в использовании.
Давайте начнем с добавления com.mbeddr.mpsutil.treenotation.styles.editor к зависимостям редактора нашего языка.
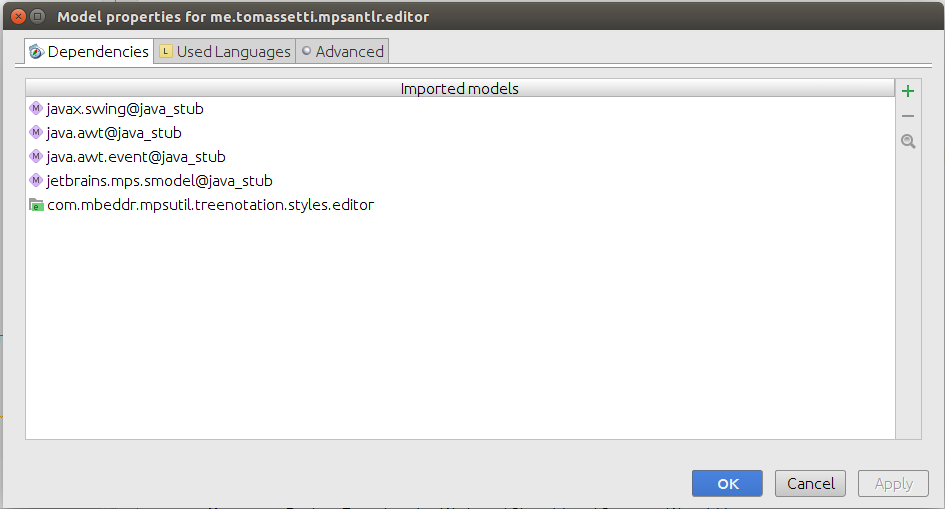
Нам также понадобится com.mbeddr.mpsutil.treenotation, чтобы быть среди используемых языков.
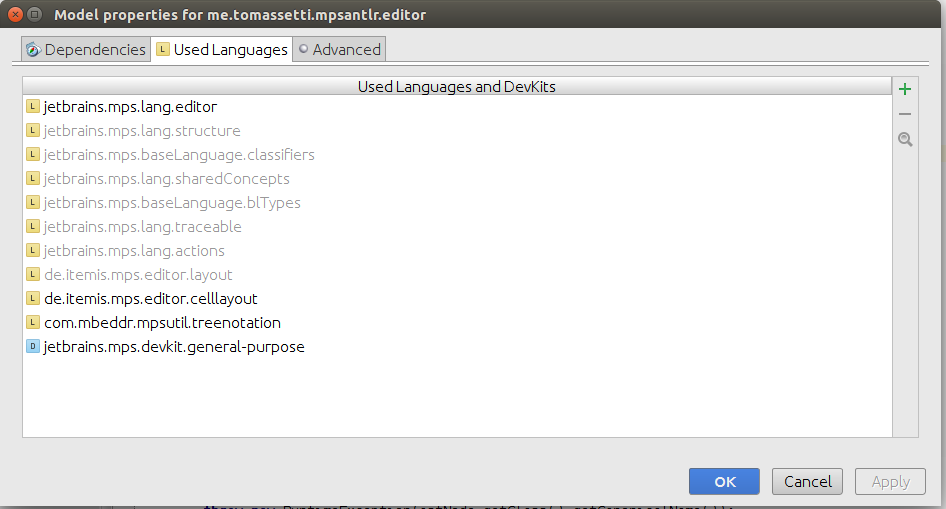
Редактор для Non TerminalNode состоит из одной ячейки дерева. Верхняя часть ячейки дерева представляет этот узел. Мы будем использовать ruleName для его представления. В нижней части вместо этого мы должны выбрать отношение, содержащее детей, которые будут отображаться в дереве.
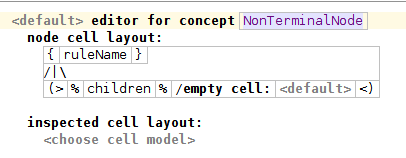
Мы можем поставить курсор на древовидный чертеж между верхней и нижней частью (символ «/ | \») и открыть инспектор. Там мы можем использовать атрибуты стиля, чтобы настроить внешний вид дерева

Мы просто решили показать дерево слева направо, а не сверху вниз. Затем мы решаем добавить больше пробелов между родителем и потомками, когда их слишком много. Таким образом, линии не слишком сильно перекрываются.
Вот так это выглядит без свойства

Вот как это выглядит с набором свойств
Есть и другие свойства, которые можно использовать, например, для контроля цвета и толщины линий. Или вы можете добавить формы на крайних линиях. Пока эти функции нам не нужны, но приятно знать, что они есть.
Редактор для TerminalNode очень прост

Выводы
С годами MPS стал более стабильным и простым в использовании. Это достигло точки, в которой вы можете быть очень продуктивным, используя его. Проекционное редактирование — это идея, которая существует уже некоторое время, и существуют другие реализации, такие как Whole Platform . Однако MPS достиг очень высокого уровня зрелости.
Я думаю, что мы все еще скучаем по:
- процессы и лучшие практики: как мы должны управлять зависимостями с другими проектами MPS? Как мы должны интегрироваться с библиотеками Java?
- примеры: на удивление мало приложений, которые общедоступны. В конце концов, многие пользователи разрабатывают DSL для своих конкретных целей и не собираются делиться ими. Однако это означает, что у нас мало возможностей учиться друг у друга
- расширения: команда Mbeddr проделывает потрясающую работу, предоставляя множество полезных возможностей в рамках платформы Mbeddr. Тем не менее, они, похоже, единственные, кто производит повторно используемые компоненты и делится ими
Я думаю, что сейчас пришло время вместе понять, чего мы можем достичь с помощью проекционного редактирования. На мой взгляд, это будут очень интересные времена.
Если мне нужно выразить одно желание, я бы хотел услышать больше о том, как другие используют MPS. Если вы там, пожалуйста, постучите. И оставить комментарий