Проще говоря, декомпилятор пытается обратить преобразование исходного кода в объектный код. Но есть много интересных сложностей — исходный код Java структурирован; байт-код, конечно, нет. Более того, преобразование не является взаимно-однозначным: две разные программы на Java могут выдавать идентичный байт-код. Нам нужно применить эвристику, чтобы получить разумное приближение к исходному источнику.
(A Tiny) Обновление байт-кода
Чтобы понять, как работает декомпилятор, необходимо понять основы байт-кода. Если вы уже знакомы с байт-кодом, смело переходите к следующему разделу.
JVM — это машина, основанная на стеке (в отличие от машины, основанной на регистрах), то есть инструкции работают с оценочным стеком. Операнды могут быть извлечены из стека, выполнены различные операции, а результаты возвращены в стек для дальнейшей оценки. Рассмотрим следующий метод:
|
1
2
3
4
|
public static int plus(int a, int b) { int c = a + b; return c;} |
Примечание. Весь байт-код, показанный в этой статье, выводится из javap , например, javap -c -p MyClass .
|
1
2
3
4
5
6
7
8
9
|
public static int plus(int, int); Code: stack=2, locals=3, arguments=2 0: iload_0 // load ‘x’ from slot 0, push onto stack 1: iload_1 // load ‘y’ from slot 1, push onto stack 2: iadd // pop 2 integers, add them together, and push the result 3: istore_2 // pop the result, store as ‘sum’ in slot 2 4: iload_2 // load ‘sum’ from slot 2, push onto stack 5: ireturn // return the integer at the top of the stack |
(Комментарии добавлены для ясности.)
Локальные переменные метода (включая аргументы метода) хранятся в том, что JVM называет массивом локальных переменных . Для краткости мы будем ссылаться на значение (или ссылку), хранящееся в местоположении #x в массиве локальной переменной, как `slot #x ‘(см. Спецификацию JVM §3.6.1 ).
Для методов экземпляра значение в слоте # 0 всегда является указателем this . Затем идут аргументы метода слева направо, за которыми следуют все локальные переменные, объявленные в методе. В приведенном выше примере метод является статическим, поэтому указатель отсутствует; Слот № 0 содержит параметр x , а слот № 1 содержит параметр y . Локальная переменная sum находится в слоте № 2.
Интересно отметить, что у каждого метода есть максимальный размер стека и максимальное хранилище локальных переменных, которые определяются во время компиляции.
Отсюда очевидно, что вы, возможно, изначально не ожидали, это то, что компилятор не пытался оптимизировать код. На самом деле, javac почти никогда не излучает оптимизированный байт-код. Это имеет множество преимуществ, в том числе возможность устанавливать точки останова в большинстве мест: если бы мы исключили избыточные операции загрузки / хранения, мы бы потеряли эту возможность. Таким образом, большая часть тяжелой работы выполняется во время выполнения компилятором JIT.
Декомпиляция
Итак, как вы можете взять неструктурированный, основанный на стеке байт-код и перевести его обратно в структурированный Java-код? Одним из первых шагов обычно является избавление от стека операндов, что мы делаем, отображая значения стека в переменные и вставляя соответствующие операции загрузки и сохранения.
«Переменная стека» назначается только один раз и используется один раз. Вы можете заметить, что это приведет к большому количеству избыточных переменных — об этом позже! Декомпилятор также может преобразовать байт-код в еще более простой набор инструкций, но мы не будем это здесь рассматривать.
Мы будем использовать обозначение s0 (и т. Д.) Для представления переменных стека , а v0 для представления истинных локальных переменных, на которые есть ссылка в исходном байт-коде (и которые хранятся в слотах).
| Bytecode | Переменные стека | Копирование распространения | |
|---|---|---|---|
| 0 1 2 3 4 5 |
iload_0 iload_1 я добавить istore_2 iload_2 я возвращаюсь |
s0 = v0 s1 = v1 s2 = s0 + s1 v2 = s2 s3 = v2 вернуть с3 |
v2 = v0 + v1
возврат v2 |
Мы переходим от байт-кода к переменным , присваивая идентификаторы каждому выдвинутому или iadd значению, например, iadd два операнда для добавления и толкает результат.
Затем мы применяем технику, называемую распространением копии, чтобы исключить некоторые из избыточных переменных. Распространение копии — это форма встраивания, в которой ссылки на переменные просто заменяются присвоенным значением при условии, что преобразование допустимо.
Что мы подразумеваем под «действительным»? Ну, есть некоторые важные ограничения. Учтите следующее:
|
1
2
3
|
0: s0 = v11: v1 = s42: v2 = s0 <-- s0 cannot be replaced with v1 |
Здесь, если бы мы заменили s0 на v0 , поведение изменилось бы, так как значение v0 изменяется после того, как s0 назначен, но до того, как он будет использован. Чтобы избежать этих осложнений, мы используем копирование только для встроенных переменных, которые назначаются ровно один раз .
Одним из способов обеспечения этого может быть отслеживание всех хранилищ для переменных, не являющихся стеками, т. Е. Мы знаем, что v1 назначен v1 0 в # 0, а также v1 1 в # 2. Поскольку существует более одного присвоения v1 , мы не можем выполнять копирование.
Наш оригинальный пример, однако, не имеет таких сложностей, и мы в итоге получаем хороший, краткий результат:
|
1
2
|
v2 = v0 + v1return v2 |
В сторону: восстановление имен переменных
Если переменные сводятся к ссылкам на слоты в байтовом коде, как тогда мы восстановим исходные имена переменных? Возможно, мы не можем. Чтобы улучшить отладку, байт-код для каждого метода может включать специальный раздел, называемый таблицей локальных переменных . Для каждой переменной в исходном источнике существует запись, которая задает имя, номер слота и диапазон байтовых кодов, к которым применяется имя. Эта таблица (и другие полезные метаданные) могут быть включены в разборку javap с помощью опции -v . Для нашего метода plus() приведенного выше, таблица выглядит следующим образом:
|
1
2
3
4
|
Start Length Slot Name Signature0 6 0 a I0 6 1 b I4 2 2 c I |
Здесь мы видим, что v2 ссылается на целочисленную переменную, первоначально названную ‘ c ‘ в смещениях байт-кода # 4-5.
Для классов, которые были скомпилированы без таблиц локальных переменных (или которые удалили их с помощью обфускатора), мы должны сгенерировать наши собственные имена. Есть много стратегий для этого; умная реализация может посмотреть, как переменная используется для подсказок на подходящем имени.
Анализ стека
В предыдущем примере мы могли гарантировать, какое значение было на вершине стека в любой заданной точке, и поэтому мы могли бы назвать s0 , s1 и так далее.
Пока что работа с переменными была довольно простой, потому что мы исследовали методы только с одним путем кода. В реальных приложениях большинство методов не будут такими удобными. Каждый раз, когда вы добавляете цикл или условие к методу, вы увеличиваете количество возможных путей, которые может использовать вызывающая сторона. Рассмотрим эту модифицированную версию нашего предыдущего примера:
|
1
2
3
4
|
public static int plus(boolean t, int a, int b) { int c = t ? a : b; return c;} |
Теперь у нас есть поток управления, чтобы усложнять вещи; Если попытаться выполнить те же задания, что и раньше, мы столкнемся с проблемой.
| Bytecode | Переменные стека | |
|---|---|---|
| 0 1 4 5 8 9 10 11 |
iload_0 ифек 8 iload_1 перейти к 9 iload_2 istore_3 iload_3 я возвращаюсь |
s0 = v0 если (s0 == 0) перейти к # 8 s1 = v1 Перейти к № 9 s2 = v2 v3 = {s1, s2} s4 = v3 возврат с4 |
Нам нужно быть немного умнее в том, как мы назначаем наши идентификаторы стека. Уже недостаточно рассматривать каждую инструкцию отдельно; нам нужно отслеживать, как выглядит стек в любом заданном месте, потому что есть несколько путей, по которым мы могли бы туда добраться.
Когда мы исследуем #9 , мы видим, что istore_3 извлекает одно значение, но у этого значения есть два источника: оно могло появиться либо в #5 либо в #8 . Значение в верхней части стека в #9 может быть либо s1 либо s2 , в зависимости от того, пришли мы из #5 или #8 соответственно. Следовательно, мы должны рассматривать их как одну и ту же переменную — мы объединяем их, и все ссылки на s1 или s2 становятся ссылками на однозначную переменную s{1,2} . После этой «перемаркировки» мы можем безопасно выполнять копирование.
| После перемаркировки | После распространения копии | |
|---|---|---|
| 0 1 4 5 8 9 10 11 |
s0 = v0 если (s0 == 0) перейти к # 8 s {1,2} = v1 Перейти к № 9 s {1,2} =: v2 v3 = s {1,2} s4 = v3 возврат с4 |
если (v0 == 0) перейти к # 8 s {1,2} = v1 Перейти к № 9 s {1,2} = v2 v3 = s {1,2} возврат v3 |
Обратите внимание на условную ветвь в #1 : если значение s0 равно нулю, мы переходим к блоку else ; в противном случае мы продолжаем идти по текущему пути. Интересно отметить, что условие теста отрицается по сравнению с исходным источником.
Теперь мы достаточно покрыты, чтобы погрузиться в…
Условные выражения
На этом этапе мы можем определить, что наш код может быть смоделирован с помощью тернарного оператора ( ?: : У нас есть условие, каждая ветвь имеет одно присваивание одной и той же переменной стека s {1,2}, после чего два пути сходятся.
Как только мы определили эту модель, мы можем сразу же свернуть троицу.
| После копирования проп. | Свернуть тройной | |
|---|---|---|
| 0 1 4 5 8 9 10 11 |
если (v0 == 0) перейти к # 8 s {1,2} = v1 перейти к 9 s {1,2} = v2 v3 = s {1,2} возврат v3 |
v3 = v0! = 0? v1: v2
возврат v3 |
Обратите внимание, что в рамках преобразования мы отрицали условие в #9 . Оказывается, что javac довольно предсказуемо в том, как он отменяет условия, поэтому мы можем более точно сопоставить исходный источник, если мы перевернем эти условия обратно.
В сторону — но какие бывают типы?
При работе со значениями стека JVM использует более упрощенную систему типов, чем исходный код Java. В частности, значения типа boolean , char и short обрабатываются с использованием тех же инструкций, что и значения int . Таким образом, сравнение v0 != 0 можно интерпретировать как:
|
1
|
v0 != false ? v1 : v2 |
…или же:
|
1
|
v0 != 0 ? v1 : v2 |
…или даже:
|
1
|
v0 != false ? v1 == true : v2 == true |
…и так далее!
Однако в этом случае нам повезло узнать точный тип v0 , так как он содержится в дескрипторе метода :
|
1
2
|
descriptor: (ZII)I flags: ACC_PUBLIC, ACC_STATIC |
Это говорит нам о том, что сигнатура метода имеет вид:
|
1
|
public static int plus(boolean, int, int) |
Мы также можем сделать вывод, что v3 должно быть int (в отличие от boolean ), потому что оно используется в качестве возвращаемого значения, а дескриптор сообщает нам тип возвращаемого значения. Затем мы остаемся с:
|
1
2
|
v3 = v0 ? v1 : v2return v3 |
Кроме того, если бы v0 была локальной переменной (а не формальным параметром), то мы могли бы не знать, что она представляет собой boolean значение, а не int . Помните ту локальную таблицу переменных, о которой мы упоминали ранее, которая сообщает нам исходные имена переменных? Он также содержит информацию о типах переменных, поэтому, если ваш компилятор настроен на выдачу отладочной информации, мы можем обратиться к этой таблице за подсказками типов. Существует еще одна похожая таблица с именем LocalVariableTypeTable, которая содержит аналогичную информацию; ключевое отличие состоит в том, что LocalVariableTypeTable может включать в себя подробную информацию о универсальных типах, тогда как LocalVariableTable не может. Стоит отметить, что эти таблицы являются непроверенными метаданными, поэтому они не обязательно заслуживают доверия . Особенно коварный обфускатор может решить заполнить эти таблицы ложью, и полученный байт-код все равно будет действительным! Используйте их по своему усмотрению.
Операторы короткого замыкания ( '&&' и '||' )
|
1
2
3
|
public static boolean fn(boolean a, boolean b, boolean c){ return a || b && c;} |
Что может быть проще? Байт-код, к сожалению, немного болезненный …
| Bytecode | Переменные стека | После распространения копии | |
|---|---|---|---|
| 0 1 4 5 8 9 12 13 16 17 |
iload_0 ИФН № 12 iload_1 ИФЭК № 16 iload_2 ИФЭК № 16 iconst_1 Перейти к # 17 iconst_0 я возвращаюсь |
s0 = v0 если (s0! = 0) перейти к # 12 s1 = v1 если (s1 == 0) перейти к # 16 s2 = v2 if (s2 == 0) перейти к # 16 s3 = 1 перейти к 17 s4 = 0 return s {3,4} |
if (v0! = 0) перейти к # 12 if (v1 == 0) перейти к # 16 if (v2 == 0) перейти к # 16 |
Инструкция ireturn в #17 может вернуть либо s3 либо s4 , в зависимости от того, какой путь ireturn . Мы называем их псевдонимами, как описано выше, а затем выполняем копирование для исключения s0 , s1 и s2 .
Нам осталось три последовательных условия на #1 , #5 и #7 . Как мы упоминали ранее, условные ветви либо перепрыгивают, либо переходят к следующей инструкции.
Приведенный выше байт-код содержит последовательности условных ветвей, которые следуют определенным и очень полезным шаблонам:
| Условное соединение (&&) | Условная дизъюнкция (||) | ||||
|---|---|---|---|---|---|
|
|
Если мы рассмотрим соседние пары условных выражений выше, #1...#5 не соответствуют ни одному из этих шаблонов, но #5...#9 является условной дизъюнкцией ( || ), поэтому мы применяем соответствующее преобразование:
|
1
2
3
4
5
6
|
1: if (v0 != 0) goto #12 5: if (v1 == 0 || v2 == 0) goto #1612: s{3,4} = 113: goto #1716: s{3,4} = 017: return s{3,4} |
Обратите внимание, что каждое применяемое нами преобразование может создавать возможности для выполнения дополнительных преобразований. В этом случае, применяя || transform реструктурировала наши условия, и теперь #1...#5 соответствуют шаблону && ! Таким образом, мы можем еще больше упростить метод, объединив эти строки в одну условную ветвь:
|
1
2
3
4
5
|
1: if (v0 == 0 && (v1 == 0 || v2 == 0)) goto #1612: s{3,4} = 113: goto #1716: s{3,4} = 017: return s{3,4} |
Это выглядит знакомо? Это должно: этот байт-код теперь соответствует шаблону троичного оператора ( ?: :), Который мы рассмотрели ранее. Мы можем уменьшить #1...#16 до одного выражения, а затем использовать копирование для вставки в s{3,4} в оператор return в #17 :
|
1
|
return (v0 == 0 && (v1 == 0 || v2 == 0)) ? 0 : 1; |
Используя дескриптор метода и таблицы типов локальных переменных, описанные ранее, мы можем вывести все типы, необходимые для сокращения этого выражения:
|
1
|
return (v0 == false && (v1 == false || v2 == false)) ? false : true; |
Ну, это, конечно, более лаконично, чем наша оригинальная декомпиляция, но все равно довольно неприятно. Давайте посмотрим, что мы можем сделать с этим. Мы можем начать со свертывания сравнений, таких как x == true и x == false для x и !x соответственно. Мы также можем исключить троичный оператор, уменьшив x ? false : true x ? false : true как простое выражение !x .
|
1
|
return !(!v0 && (!v1 || !v2)); |
Лучше, но это все еще немного. Если вы помните свою среднюю школу, вы можете увидеть, что теорема Де Моргана может быть применена здесь:
|
1
2
|
!(a || b) --> (!a) && (!b) !(a && b) --> (!a) || (!b) |
И поэтому:
|
1
|
return ! ( !v0 && ( !v1 || !v2 ) ) |
… становится:
|
1
|
return ( v0 || !(!v1 || !v2 ) ) |
… и в конце концов:
|
1
|
return ( v0 || (v1 && v2) ) |
Ура!
Работа с вызовами методов
Мы уже видели, как выглядит вызываемый метод: аргументы «приходят» в массиве locals. Для вызова метода аргументы должны быть помещены в стек, следуя указателю this в случае методов экземпляра). Вызов метода в байт-коде, как и следовало ожидать:
|
1
2
3
|
push arg_0 push arg_1 invokevirtual METHODREF |
Выше мы указали invokevirtual , который используется для вызова большинства методов экземпляра. JVM на самом деле имеет несколько инструкций, используемых для вызовов методов, каждая из которых имеет свою семантику:
-
invokeinterfaceвызывает методы интерфейса. -
invokevirtualвызывает методы экземпляра с использованием виртуальной семантики, т. е. вызов отправляется с надлежащим переопределением на основе типа времени выполнения цели. -
invokespecialактивизирует конкретный метод экземпляра (без виртуальной семантики); он чаще всего используется для вызова конструкторов, но также используется для вызовов, таких какsuper.method(). -
invokestaticвызывает статические методы. -
invokedynamicявляется наименее распространенным (в Java) и использует метод начальной загрузки для вызова пользовательского связывателя сайта вызовов. Он был создан для улучшения поддержки динамических языков и использовался в Java 8 для реализации лямбд.
Важной деталью для создателя декомпилятора является то, что пул констант класса содержит детали для любого вызванного метода, включая число и тип его аргументов, а также тип возвращаемого значения. Запись этой информации в классе вызывающей стороны позволяет среде выполнения проверить, что предполагаемый метод существует во время выполнения и соответствует ожидаемой подписи. Если целевой метод находится в стороннем коде, и его сигнатура изменяется, то любой код, который пытается вызвать старую версию, выдаст ошибку (в отличие от создания неопределенного поведения).
Возвращаясь к нашему примеру выше, наличие invokevirtual операции invokevirtual говорит нам, что целевой метод является методом экземпляра , и поэтому требует указатель this в качестве неявного первого аргумента. METHODREF в пуле констант говорит нам, что метод имеет один формальный параметр, поэтому мы знаем, что нам нужно METHODREF аргумент из стека в дополнение к указателю целевого экземпляра. Затем мы можем переписать код следующим образом:
|
1
|
arg_0.METHODREF(arg_1) |
Конечно, байт-код не всегда так дружелюбен; нет требования, чтобы аргументы стека аккуратно помещались в стек один за другим. Если, например, один из аргументов является троичным выражением, то будут промежуточные инструкции загрузки, хранения и ветвления, которые необходимо будет преобразовать независимо. Обфускаторы могут переписать методы в особенно запутанную последовательность инструкций. Хороший декомпилятор должен быть достаточно гибким, чтобы справляться со многими интересными крайними случаями, которые выходят за рамки этой статьи.
Там должно быть больше, чем это …
До сих пор мы ограничивались анализом одной последовательности кода, начиная со списка простых инструкций и применяя преобразования, которые производят более знакомые конструкции более высокого уровня. Если вы думаете, что это кажется слишком упрощенным, то вы правы. Java — это высокоструктурированный язык с такими понятиями, как области действия и блоки, а также с более сложными механизмами управления потоками. Чтобы иметь дело с такими конструкциями, как блоки и циклы if/else , нам необходимо выполнить более тщательный анализ кода, уделяя особое внимание различным путям, которые могут быть использованы. Это называется анализом потока управления .
Мы начинаем с разбивки нашего кода на непрерывные блоки, которые гарантированно будут выполняться от начала до конца. Они называются базовыми блоками , и мы строим их, разбивая наш список инструкций по местам, где мы можем перейти к другому блоку, а также любые инструкции, которые могут быть самими объектами прыжка.
Затем мы строим график потока управления (CFG), создавая ребра между блоками, чтобы представить все возможные ветви. Обратите внимание, что эти ребра не могут быть явными ветвями; блоки, содержащие инструкции, которые могут генерировать исключения, будут связаны с их соответствующими обработчиками исключений. Мы не будем вдаваться в подробности о построении CFG, но для понимания того, как мы используем эти графики для обнаружения конструкций кода, таких как циклы, требуются определенные знания высокого уровня.
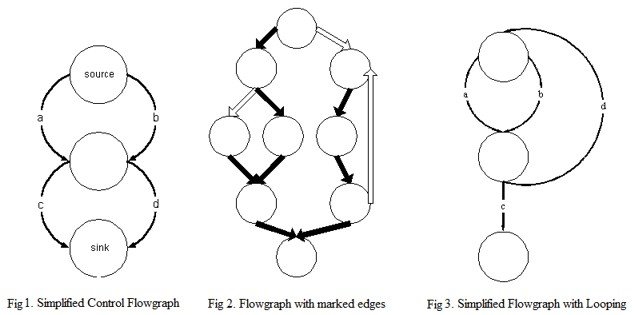
Примеры управляющих потоковых графиков.
Наиболее интересными аспектами потоковых графов управления являются отношения доминирования :
- Говорят, что узел
Dдоминирует над другим узломNесли все пути кNпроходят черезDВсе узлы доминируют сами по себе; еслиDиN— разные узлы, то говорят, чтоDстрого доминирует надN - Если
Dстрого доминирует надNи не строго доминирует над любым другим узлом, который строго доминирует надN, то можно сказать, чтоDнемедленно доминирует надN - Доминирующее дерево — это дерево узлов, в котором дочерние элементы каждого узла являются узлами, в которых он непосредственно доминирует.
- Граница доминирования
D— это совокупность всех узловN, так чтоDдоминирует в непосредственном предшественникеNно не строго доминирует вNДругими словами, это множество узлов, где доминированиеDзаканчивается.
Основные циклы и поток управления
Рассмотрим следующий метод Java:
|
1
2
3
4
5
|
public static void fn(int n) { for (int i = 0; i < n; ++i) { System.out.println(i); }} |
… И его разборка:
|
01
02
03
04
05
06
07
08
09
10
11
|
0: iconst_0 1: istore_1 2: iload_1 3: iload_0 4: if_icmpge 20 7: getstatic #2 // System.out:PrintStream10: iload_111: invokevirtual #3 // PrintStream.println:(I)V14: iinc 1, 117: goto 220: return |
Давайте применим то, что мы обсуждали выше, чтобы преобразовать это в более читаемую форму, сначала введя переменные стека, а затем выполняя копирование.
| Bytecode | Переменные стека | После распространения копии | |
|---|---|---|---|
| 0 1 2 3 4 7 10 11 14 17 20 |
iconst_0 istore_1 iload_1 iload_0 if_icmpge 20 gettatic # 2 iload_1 invokevirtual # 3 Iinc 1, 1 перейти к 2 возвращение |
s0 = 0 v1 = s0 s2 = v1 s3 = v0 если (s2> = s3) перейти к 20 s4 = System.out s5 = v1 s4.println (s5) v1 = v1 + 1 перейти к 2 возвращение |
v1 = 0, если (v1> = v0) перейти к 20 System.out.println (v1) |
Обратите внимание, как условная ветвь в #4 и goto в #17 создают логический цикл. Мы можем увидеть это легче, посмотрев на график потока управления:
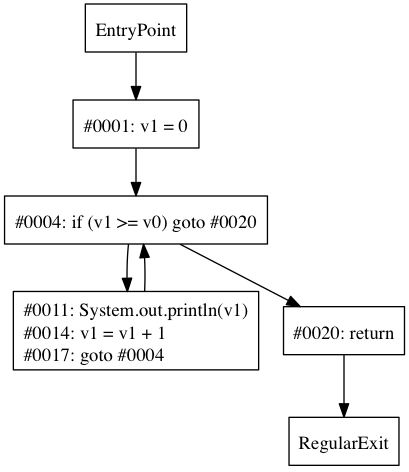
Из графика видно, что у нас есть аккуратный цикл с ребром от goto к условной ветви. В этом случае условная ветвь упоминается как заголовок цикла , который может быть определен как доминирующий элемент с обратным краем, образующим цикл. Заголовок цикла доминирует над всеми узлами в теле цикла.
Мы можем определить, является ли условие заголовком цикла, посмотрев на задний край, формирующий цикл, но как нам это сделать? Простое решение состоит в том, чтобы проверить, находится ли узел условия в своей собственной границе доминирования. Как только мы узнаем, что у нас есть заголовок цикла, мы должны выяснить, какие узлы нужно вставить в тело цикла; мы можем сделать это, найдя все узлы, в которых доминирует заголовок. В псевдокоде наш алгоритм будет выглядеть примерно так:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
findDominatedNodes(header) q := new Queue() r := new Set() q.enqueue(header) while (not q.empty()) n := q.dequeue() if (header.dominates(n)) r.add(n) for (s in n.successors()) q.enqueue(n) return r |
Как только мы выяснили тело цикла, мы можем преобразовать наш код в цикл. Имейте в виду, что наш заголовок цикла может быть условным переходом из цикла, и в этом случае нам нужно отменить условие.
|
1
2
3
4
5
6
|
v1 = 0while (v1 < v0) { System.out.println(v1) v1 = v1 + 1}return |
И вуаля, у нас есть простой цикл предварительных условий! Большинство циклов, включая while , for и for-each , компилируются в один и тот же базовый шаблон, который мы обнаруживаем как простой цикл while. Нет никакого способа узнать наверняка, какой цикл изначально написал программист, но for и for-each следуют довольно специфические шаблоны, которые мы можем искать. Мы не будем вдаваться в подробности, но если вы посмотрите на цикл while выше, вы увидите, как оригинал инициализатора цикла ( v1 = 0 ) предшествует циклу, и его итератор ( v1 = v1 + 1 ) был вставлен в конце тела цикла. Мы оставим это в качестве упражнения, чтобы подумать о том, когда и как можно преобразовать циклы в for или for-each . Также интересно подумать о том, как нам, возможно, придется настроить нашу логику для обнаружения постусловных циклов ( do/while ).
Мы можем применить подобную технику для декомпиляции операторов if/else . Шаблон байт-кода довольно прост:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
begin: iftrue(!condition) goto #else // `if` block begins here ... goto #endelse: // `else` block begins here ...end: // end of `if/else` |
Здесь мы используем iftrue в качестве псевдоинструкции для представления любой условной ветви: проверяем условие, и если оно проходит, то ветвь; в противном случае продолжайте. Мы знаем, что блок if начинается с инструкции, следующей за условием, а блок else начинается с цели перехода условия. Найти содержимое этих блоков так же просто, как найти узлы, в которых доминируют эти начальные узлы, что мы можем сделать, используя тот же алгоритм, который мы описали выше.
Теперь мы рассмотрели основные механизмы управления потоком, и хотя есть и другие (например, обработчики исключений и подпрограммы), они выходят за рамки этой вводной статьи.
Заворачивать
Написание декомпилятора — непростая задача, и этот опыт легко превращается в материал, достойный книги — возможно, даже серии книг! Очевидно, что мы не смогли бы охватить все в одном посте в блоге, и вы, вероятно, не захотели бы прочитать его, если бы мы попробовали. Мы надеемся, что, коснувшись наиболее распространенных конструкций — логических операторов, условных выражений и базового потока управления — мы дадим вам интересное представление о мире разработки декомпиляторов.
Ли Бенфилд — автор декомпилятора CFR Java.
Майк Штробель — автор Procyon , декомпилятора Java и инфраструктуры метапрограммирования.
А теперь иди написать свой собственный! 🙂