Apache Mahout — это «масштабируемая библиотека машинного обучения», которая, помимо прочего, содержит реализации различных одноузловых и распределенных алгоритмов рекомендаций. В своем последнем сообщении в блоге я описал, как внедрить систему онлайновой рекомендации для обработки данных на одном узле. Что делать, если данные слишком велики, чтобы поместиться в память (> 100 миллионов точек данных предпочтения)? Тогда у нас нет выбора, кроме как взглянуть на реализацию распределенных рекомендаций Mahout!
Распределенный рекомендатель основан на Apache Hadoop; это задание, которое принимает в качестве входных данных список пользовательских настроек, вычисляет матрицу сопутствующих элементов и выводит рекомендации top-K для каждого пользователя. Вводный блог о том, как это работает и как его запускать локально, см., Например, в этом блоге .
Конечно, мы можем запустить это задание на пользовательском кластере Hadoop, но гораздо быстрее (и менее болезненно) просто использовать предварительно настроенный кластер, такой как EMR. Однако есть небольшая проблема. Последняя версия Hadoop, доступная на EMR, — это 1.0.3, и она содержит файлы jar для Apache Lucene 2.9.4. Однако задание рекомендации зависит от Lucene 4.3.0, что приводит к следующей красивой трассировке стека:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
2013-10-04 11:05:03,921 FATAL org.apache.hadoop.mapred.Child (main): Error running child : java.lang.NoSuchMethodError: org.apache.lucene.util.PriorityQueue.<init>(I)V at org.apache.mahout.math.hadoop.similarity.cooccurrence.TopElementsQueue.<init>(TopElementsQueue.java:33) at org.apache.mahout.math.hadoop.similarity.cooccurrence.RowSimilarityJob$UnsymmetrifyMapper.map(RowSimilarityJob.java:405) at org.apache.mahout.math.hadoop.similarity.cooccurrence.RowSimilarityJob$UnsymmetrifyMapper.map(RowSimilarityJob.java:389) at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:144) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:771) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:375) at org.apache.hadoop.mapred.Child$4.run(Child.java:255) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1132) at org.apache.hadoop.mapred.Child.main(Child.java:249) |
Как это решить? Что ж, нам «просто» нужно обновить Lucene в установке EMR Hadoop. Для этого мы можем использовать действие начальной загрузки . Вот точные шаги:
- Загрузите lucene-4.3.0.tgz (например, отсюда ) и загрузите его в корзину S3; сделать файл общедоступным.
- Загрузите этот скрипт в корзину; назовите это, например,
update-lucene.sh:123456789#!/bin/bashcd/home/hadoopwget https://s3.amazonaws.com/bucket_name/bucket_path/lucene-4.3.0.tgztar-xzf lucene-4.3.0.tgzcdlibrmlucene-*.jarcd..cdlucene-4.3.0find. |greplucene- |grepjar$ |xargs-I {}cp{} ../libЭтот скрипт будет выполняться на узлах Hadoop и обновит версию Lucene. Обязательно измените сценарий и введите правильное имя сегмента и путь сегмента, чтобы он указывал на общедоступный архив Lucene.
- mahout-core-0.8-job.jar в ведро
- Наконец, нам нужно загрузить входные данные в S3. Выходные данные также будут сохранены на S3.
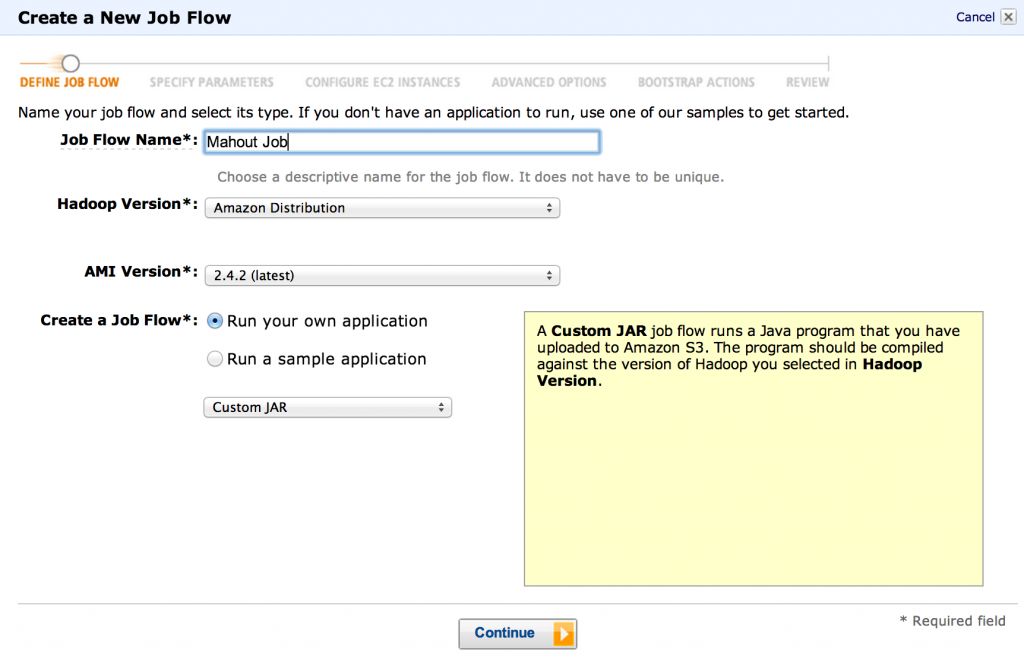
- Теперь мы можем начать настройку потока работ EMR. Перейдите на страницу EMR в консоли Amazon и начните создавать новый поток работ. Мы будем использовать версию Hadoop «Amazon Distribution» и использовать «Custom JAR» в качестве типа задания.

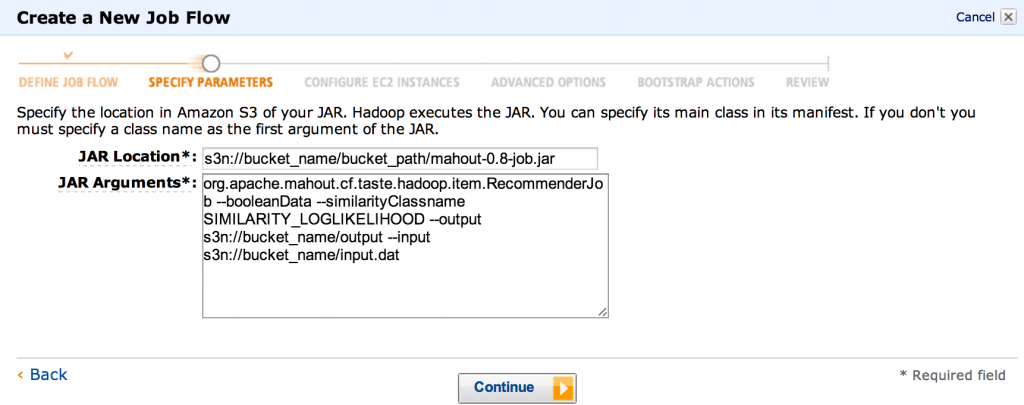
- «Расположение JAR» должно указывать на место, куда мы загрузили банку Mahout, например,
s3n://bucket_name/bucket_path/mahout-0.8-job.jar(убедитесь, что изменили это, чтобы указать на реальное ведро!). Что касается аргументов jar, мы будем запускатьRecommenderJobи использовать логарифмическое подобие:12345org.apache.mahout.cf.taste.hadoop.item.RecommenderJob--booleanData--similarityClassname SIMILARITY_LOGLIKELIHOOD--output s3n://bucket_name/output--input s3n://bucket_name/input.datЗдесь также указывается, где находятся входные данные на S3 и куда должны записываться выходные данные.

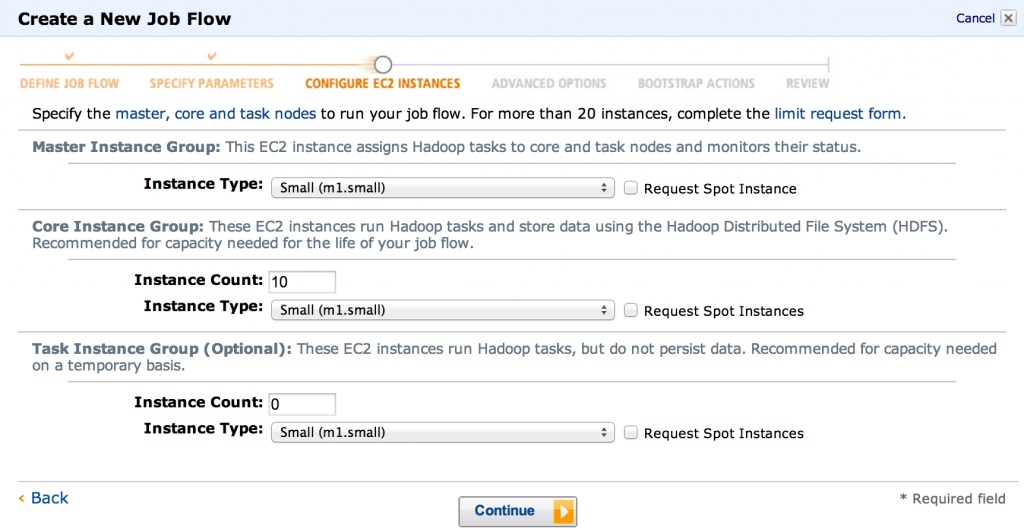
- Затем мы можем выбрать, сколько машин мы хотим использовать. Это, конечно, зависит от размера входных данных и от того, насколько быстро вы хотите получить результаты. Главное, что здесь нужно изменить, это количество «основной группы экземпляров». 2 — разумное значение по умолчанию для тестирования.

- Мы можем оставить дополнительные параметры как есть
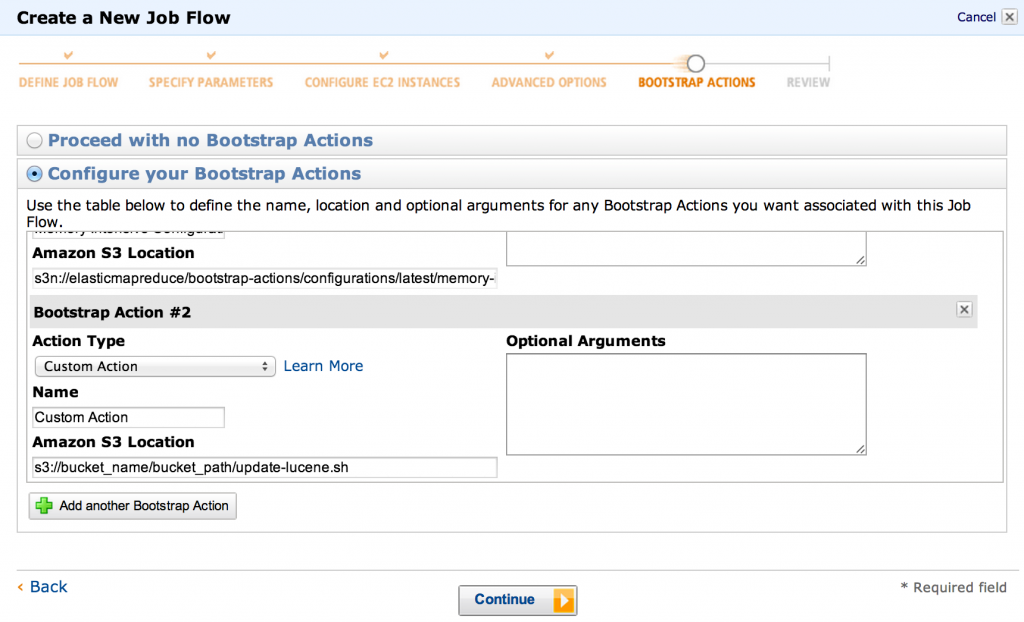
- Теперь мы переходим к одному из наиболее важных шагов: настройке действий начальной загрузки. Нам нужно настроить два:
- конфигурация с интенсивным использованием памяти (иначе вы быстро увидите OOM)
- наше пользовательское действие update-lucene (путь должен указывать на S3, например
s3://bucket_name/bucket_path/update-lucene.sh)

Вот и все! Теперь вы можете создать и запустить поток работ, и через пару минут / часов / дней вы получите результаты, ожидающие на S3.