1. Введение
С использованием микросервисов стало легко создавать стабильные распределенные приложения и избавляться от многих унаследованных проблем. Но использование микросервисов также создало несколько проблем, и управление распределенным журналом является одной из них. Поскольку микросервисы изолированы, следовательно, они не разделяют базу данных и файлы журналов, поэтому становится сложно искать, анализировать и просматривать данные журналов в режиме реального времени. Здесь на помощь приходит стек ELK.
2. ELK
Это коллекция из трех продуктов с открытым исходным кодом:
- Эластичный поиск — база данных NoSQL на основе JSON
- Logstash — инструмент конвейерного журнала, который получает входные данные из различных источников, выполняет различные преобразования и экспортирует данные в различные цели (здесь для упругого поиска).
- Kibana — это слой визуализации, который работает поверх упругого поиска.
Обратитесь к архитектуре, приведенной ниже:
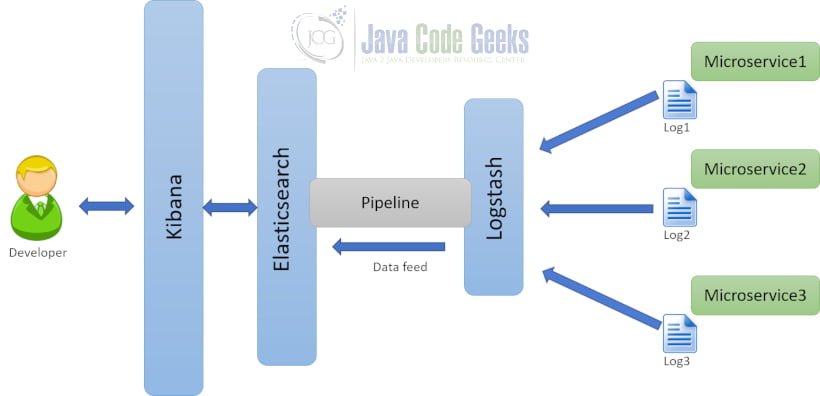
Тайник журналов извлекает журналы с микросервисов. Извлеченные журналы преобразуются в JSON и передаются для упругого поиска. Журналы, присутствующие в упругом поиске, просматриваются разработчиком с помощью Kibana.
3. Установка ELK
ELK основан на Java. Перед установкой ELK необходимо убедиться, что JAVA_HOME и PATH настроены, а установка выполнена с использованием JDK 1.8.
3.1 Elasticsearch
- Последнюю версию Elasticsearch можно загрузить со страницы загрузки, и ее можно извлечь в любую папку
- Это может быть выполнено из командной строки с помощью
bin\elasticsearch.bat - По умолчанию он начинается с http: // localhost: 9200
3.2 Кибана
- Последнюю версию Kibana можно загрузить со страницы загрузки, и ее можно извлечь в любую папку.
- Это может быть выполнено из командной строки, используя
bin\kibana.bat - После успешного запуска Kibana запустится через порт
5601по умолчанию, а пользовательский интерфейс Kibana будет доступен по адресу http: // localhost: 5601.
3.3 Logstash
- Последняя версия Logstash может быть загружена со страницы загрузки и может быть извлечена в любую папку
- Создайте один файл cst_logstash.conf согласно инструкциям по настройке
- Его можно выполнить из командной строки, используя
bin/logstash -f cst_logstash.confдля запуска logstash
4. Создание образца микросервисного компонента
Необходимо создать микросервис, чтобы logstash мог указывать на журнал API. Ниже в листинге приведен код для примера микросервиса.
pom.xml
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <modelVersion>4.0.0</modelVersion> <groupId>com.xyz.app</groupId> <artifactId>ArtDemo1001_Rest_Controller_Full_Deployment_Logging</artifactId> <version>0.0.1-SNAPSHOT</version> <!-- Add Spring repositories --> <!-- (you don't need this if you are using a .RELEASE version) --> <repositories> <repository> <id>spring-snapshots</id> <snapshots> <enabled>true</enabled> </snapshots> </repository> <repository> <id>spring-milestones</id> </repository> </repositories> <pluginRepositories> <pluginRepository> <id>spring-snapshots</id> </pluginRepository> <pluginRepository> <id>spring-milestones</id> </pluginRepository> </pluginRepositories> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.5.2.RELEASE</version> </parent> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <java.version>1.8</java.version> <spring-cloud.version>Dalston.SR3</spring-cloud.version> </properties> <!-- Add typical dependencies for a web application --> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> </dependencies> <!-- Package as an executable jar --> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>${spring-cloud.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement></project> |
В приведенном выше коде файла pom.xml настроены зависимости, необходимые для проекта, основанного на весенней загрузке.
EmployeeDAO.java
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
package com.xyz.app.dao;import java.util.Collection;import java.util.LinkedHashMap;import java.util.Map;import org.springframework.stereotype.Repository;import com.xyz.app.model.Employee;@Repositorypublic class EmployeeDAO { /** * Map is used to Replace the Database * */ static public Map<Integer,Employee> mapOfEmloyees = new LinkedHashMap<Integer,Employee>(); static int count=10004; static { mapOfEmloyees.put(10001, new Employee("Jack",10001,12345.6,1001)); mapOfEmloyees.put(10002, new Employee("Justin",10002,12355.6,1002)); mapOfEmloyees.put(10003, new Employee("Eric",10003,12445.6,1003)); } /** * Returns all the Existing Employees * */ public Collection getAllEmployee(){ return mapOfEmloyees.values(); } /**Get Employee details using EmployeeId . * Returns an Employee object response with Data if Employee is Found * Else returns a null * */ public Employee getEmployeeDetailsById(int id){ return mapOfEmloyees.get(id); } /**Create Employee details. * Returns auto-generated Id * */ public Integer addEmployee(Employee employee){ count++; employee.setEmployeeId(count); mapOfEmloyees.put(count, employee); return count; } /**Update the Employee details, * Receives the Employee Object and returns the updated Details * */ public Employee updateEmployee (Employee employee){ mapOfEmloyees.put(employee.getEmployeeId(), employee); return employee; } /**Delete the Employee details, * Receives the EmployeeID and returns the deleted employee's Details * */ public Employee removeEmployee (int id){ Employee emp= mapOfEmloyees.remove(id); return emp; } } |
Выше код представляет уровень DAO приложения. Операции CRUD выполняются в коллекции Map, содержащей объекты Employee, чтобы избежать зависимости от базы данных и сохранить свет приложения.
EmployeeController.java
|
001
002
003
004
005
006
007
008
009
010
011
012
013
014
015
016
017
018
019
020
021
022
023
024
025
026
027
028
029
030
031
032
033
034
035
036
037
038
039
040
041
042
043
044
045
046
047
048
049
050
051
052
053
054
055
056
057
058
059
060
061
062
063
064
065
066
067
068
069
070
071
072
073
074
075
076
077
078
079
080
081
082
083
084
085
086
087
088
089
090
091
092
093
094
095
096
097
098
099
100
101
102
103
104
105
106
107
108
109
110
111
112
|
package com.xyz.app.controller;import java.util.Collection;import org.apache.log4j.Logger;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.http.HttpStatus;import org.springframework.http.MediaType;import org.springframework.http.ResponseEntity;import org.springframework.web.bind.annotation.PathVariable;import org.springframework.web.bind.annotation.RequestBody;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestMethod;import org.springframework.web.bind.annotation.RestController;import com.xyz.app.dao.EmployeeDAO;import com.xyz.app.model.Employee;@RestControllerpublic class EmployeeController { @Autowired private EmployeeDAO employeeDAO; public static Logger logger = Logger.getLogger(EmployeeController.class); /** Method is used to get all the employee details and return the same */ @RequestMapping(value="emp/controller/getDetails",method=RequestMethod.GET,produces=MediaType.APPLICATION_JSON_VALUE) public ResponseEntity<Collection> getEmployeeDetails(){ logger.info("From Producer method[getEmployeeDetails] start"); logger.debug("From Producer method[getEmployeeDetails] start"); Collection listEmployee =employeeDAO.getAllEmployee(); logger.debug("From Producer method[getEmployeeDetails] start"); logger.info("From Producer method[getEmployeeDetails] end"); return new ResponseEntity<Collection>(listEmployee, HttpStatus.OK); } /** Method finds an employee using employeeId and returns the found Employee If no employee is not existing corresponding to the employeeId, then null is returned with HttpStatus.INTERNAL_SERVER_ERROR as status */ @RequestMapping(value="emp/controller/getDetailsById/{id}",method=RequestMethod.GET,produces=MediaType.APPLICATION_JSON_VALUE) public ResponseEntity getEmployeeDetailByEmployeeId(@PathVariable("id") int myId){ logger.info("From Producer method[getEmployeeDetailByEmployeeId] start"); Employee employee = employeeDAO.getEmployeeDetailsById(myId); if(employee!=null) { logger.info("From Producer method[getEmployeeDetailByEmployeeId] end"); return new ResponseEntity(employee,HttpStatus.OK); } else { logger.info("From Producer method[getEmployeeDetailByEmployeeId] end"); return new ResponseEntity(HttpStatus.NOT_FOUND); } } /** Method creates an employee and returns the auto-generated employeeId */ @RequestMapping(value="/emp/controller/addEmp", method=RequestMethod.POST, consumes=MediaType.APPLICATION_JSON_VALUE, produces=MediaType.TEXT_HTML_VALUE) public ResponseEntity addEmployee(@RequestBody Employee employee){ logger.info("From Producer method[addEmployee] start"); logger.debug("From Producer method[addEmployee] start"); int empId= employeeDAO.addEmployee(employee); logger.debug("From Producer method[addEmployee] start"); logger.info("From Producer method[addEmployee] end"); return new ResponseEntity("Employee added successfully with id:"+empId,HttpStatus.CREATED); } /** Method updates an employee and returns the updated Employee If Employee to be updated is not existing, then null is returned with HttpStatus.INTERNAL_SERVER_ERROR as status */ @RequestMapping(value="/emp/controller/updateEmp", method=RequestMethod.PUT, consumes=MediaType.APPLICATION_JSON_VALUE, produces=MediaType.APPLICATION_JSON_VALUE) public ResponseEntity updateEmployee(@RequestBody Employee employee){ logger.info("From Producer method[updateEmployee] start"); if(employeeDAO.getEmployeeDetailsById(employee.getEmployeeId())==null){ Employee employee2=null; return new ResponseEntity(employee2,HttpStatus.INTERNAL_SERVER_ERROR); } System.out.println(employee); employeeDAO.updateEmployee(employee); logger.info("From Producer method[updateEmployee] end"); return new ResponseEntity(employee,HttpStatus.OK); } /** Method deletes an employee using employeeId and returns the deleted Employee If Employee to be deleted is not existing, then null is returned with HttpStatus.INTERNAL_SERVER_ERROR as status */ @RequestMapping(value="/emp/controller/deleteEmp/{id}", method=RequestMethod.DELETE, produces=MediaType.APPLICATION_JSON_VALUE) public ResponseEntity deleteEmployee(@PathVariable("id") int myId){ logger.info("From Producer method[deleteEmployee] start"); if(employeeDAO.getEmployeeDetailsById(myId)==null){ Employee employee2=null; return new ResponseEntity(employee2,HttpStatus.INTERNAL_SERVER_ERROR); } Employee employee = employeeDAO.removeEmployee(myId); System.out.println("Removed: "+employee); logger.info("From Producer method[deleteEmployee] end"); return new ResponseEntity(employee,HttpStatus.OK); }} |
Выше код представляет уровень контроллера приложения с обработчиками запросов. Обработчики запросов вызывают функции уровня DAO и выполняют операции CRUD. application.properties
|
1
2
3
4
5
6
|
server.port = 8090logging.level.com.xyz.app.controller.EmployeeController=DEBUG#name of the log file to be created#same file will be given as input to logstashlogging.file=app.logspring.application.name = producer |
Код выше представляет свойства, настроенные для приложения на основе весенней загрузки.
5. Конфигурация Logstash
Как обсуждалось в разделе 3.3, необходимо создать файл конфигурации для logstash. Этот файл конфигурации будет использоваться logstash для получения данных из журналов микросервиса. Журналы преобразуются в JSON и передаются в эластичный поиск.
cst_logstash.conf
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
input { file { # If more than one log files from different microservices have to be tracked then a comma-separated list of log files can # be provided path => ["PATH-TO-UPDATE/app.log"] codec => multiline { pattern => "^%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{TIME}.*" negate => "true" what => "previous" } }}output { stdout { codec => rubydebug } # Sending properly parsed log events to elasticsearch elasticsearch { hosts => ["localhost:9200"] }} |
Приведенный выше файл конфигурации logstash прослушивает файл журнала и переводит сообщения журнала в режим упругого поиска.
Примечание . Измените путь журнала в соответствии с настройками.
6. Исполнение и вывод
6.1 Выполнение микросервиса для журналов
Приложение Spring Boot может быть развернуто с помощью clean install spring-boot:run и следующий URL может быть получен из браузера или почтового клиента: http: // localhost: 8090 / emp / controller / getDetails . Это ударит по микросервису и приведет к появлению журналов на стороне микросервиса. Эти журналы будут прочитаны logstash и отправлены на эластичный поиск, и далее эти журналы можно просмотреть с помощью Kibana, выполнив следующие шаги.
6.2 Шаги для просмотра вывода на Кибане
- Настройте индекс в консоли управления. Используйте значение индекса как
logstash-*в качестве конфигурации по умолчанию. Откройте ссылку: http: // localhost: 5601 / app / kibana # / management / kibana / index? _G = (), и появится экран, как показано ниже:
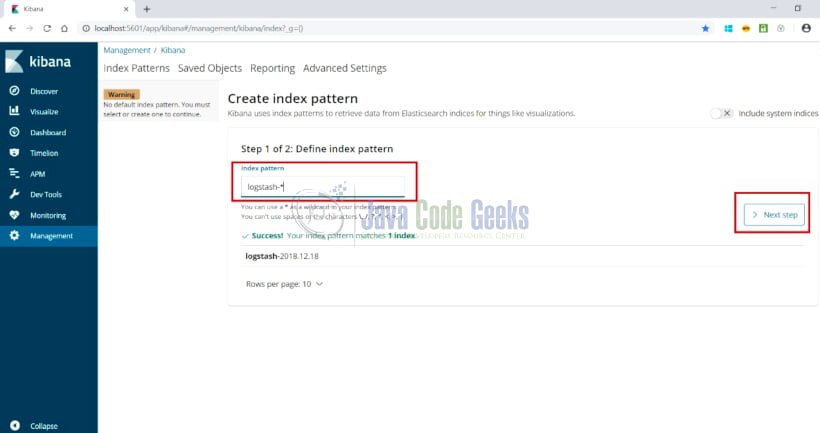
- Нажмите на следующий шаг, и появится следующий экран
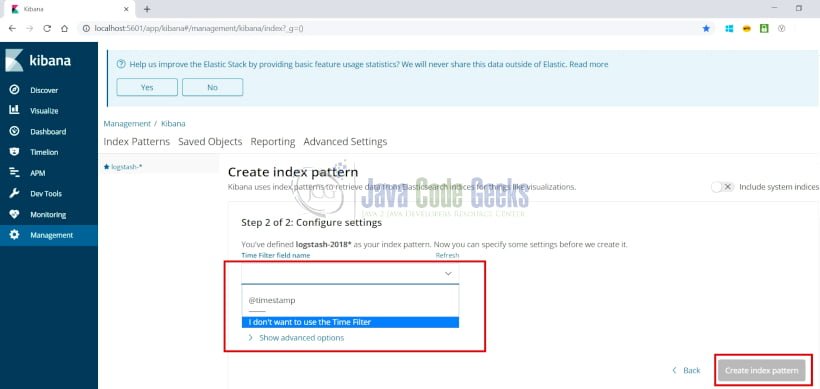
Выберите опцию, как указано выше, и нажмите «Создать шаблон индекса».
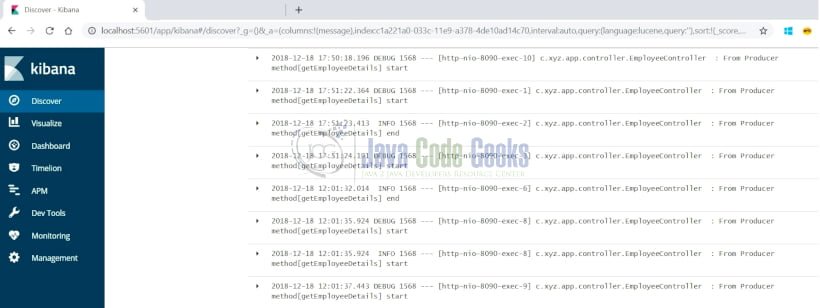
- При выборе параметра «Обнаружение» в боковом меню слева отображается страница, как показано ниже:
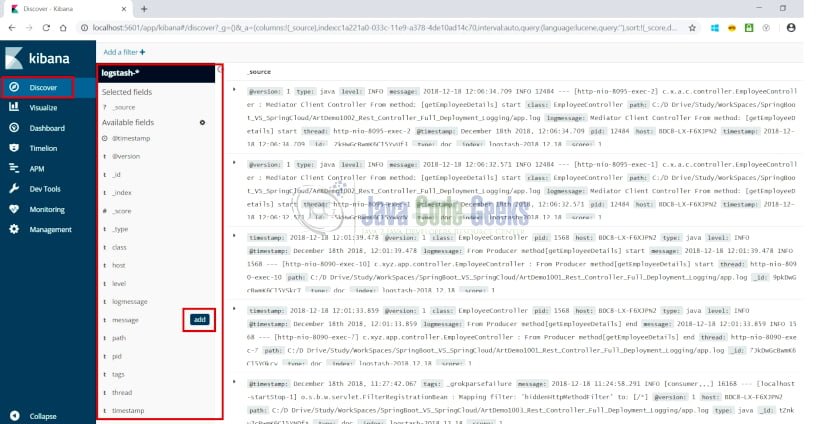
- Журналы могут быть визуализированы и отфильтрованы на основе свойств, выделенных выше. При наведении на любое из свойств отображается кнопка «Добавить» для свойства. Здесь при выборе свойства сообщения отображается, как показано ниже:
7. Ссылки
- https://logz.io/learn/complete-guide-elk-stack/
- https://howtodoinjava.com/microservices/elk-stack-tutorial-example/
- https://dzone.com/articles/logging-with-elastic-stack