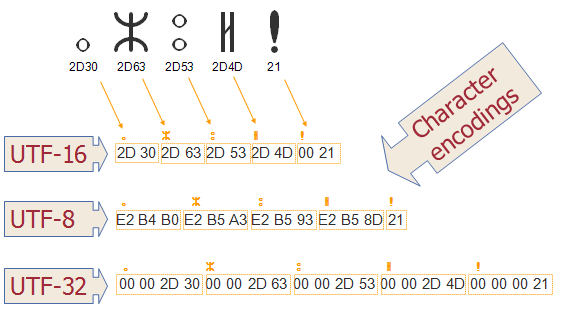
Преобразование байтового массива в String кажется простым, но трудно сделать это правильно. Многие программисты делают ошибку, игнорируя кодировку символов всякий раз, когда байты преобразуются в String или char или наоборот. Как программист, мы все знаем, что компьютер понимает только двоичные данные, то есть 0 и 1. Все, что мы видим и используем, например изображения, текстовые файлы, фильмы или любые другие мультимедийные файлы, хранится в виде байтов, но что более важно это процесс кодирования или декодирования байтов в символ. Преобразование данных является важной темой на любом собеседовании по программированию, и из-за хитрости кодирования символов эти вопросы являются одним из самых популярных вопросов о интервью в формате String в интервью Java. При чтении строки из входного источника, например, файлов XML, HTTP-запроса, сетевого порта или базы данных, вы должны обратить внимание на то, какую кодировку символов (например, UTF-8, UTF-16 и ISO 8859-1) они кодируют. Если вы не будете использовать ту же кодировку символов при преобразовании байтов в строку , вы получите поврежденную строку, которая может содержать совершенно неправильные значения. Вы могли видеть ?, квадратные скобки после преобразования byte [] в String, это из-за значений, которые ваша текущая кодировка символов не поддерживает, и просто показывает некоторые значения мусора.
Я пытался понять, почему программы делают ошибки кодирования символов чаще, чем нет, и мои небольшие исследования и собственный опыт позволяют предположить, что это может быть вызвано двумя причинами: во-первых, недостаточно для интернационализации и кодировки символов, а во-вторых, потому что символы ASCII поддерживаются почти все популярные схемы кодирования и имеют одинаковые значения. Поскольку мы в основном имеем дело с кодировкой, такой как UTF-8, Cp1252 и Windows-1252, которая отображает символы ASCII (в основном алфавиты и цифры) без сбоев, даже если вы используете другую схему кодирования. Настоящая проблема возникает, когда ваш текст содержит специальные символы, например «é» , который часто используется во французских именах. Если кодировка символов вашей платформы не распознает этот символ, то либо вы увидите другой символ, либо что-то в этом роде, и, к сожалению, пока вы не обожгете руки, вы вряд ли будете осторожны с кодировкой символов. В Java все немного сложнее, потому что многие классы ввода-вывода, например InputStreamReader, по умолчанию используют кодировку символов платформы. Это означает, что если вы запустите свою программу на другом компьютере, вы, скорее всего, получите другой вывод из-за разного кодирования символов, используемого на этом компьютере. В этой статье мы узнаем, как преобразовать byte [] в String в Java как с помощью JDK API, так и с помощью общих утилит Guava и Apache.
Как преобразовать byte [] в строку в Java
Есть несколько способов изменить байтовый массив на String в Java, вы можете использовать методы из JDK или использовать бесплатные API с открытым исходным кодом, такие как Apache commons и Google Guava. Этот API предоставляет как минимум два набора методов для создания байтового массива формы String; один, который использует кодировку платформы по умолчанию, а другой — кодировку символов. Вы всегда должны использовать позже, не полагайтесь на кодировку платформы. Я знаю, что это может быть то же самое, или вы, возможно, не сталкивались с какими-либо проблемами, но лучше быть в безопасности, чем потом сожалеть. Как я указывал в своем последнем посте о печати байтового массива в виде шестнадцатеричной строки , это также один из лучших способов указания кодировки символов при преобразовании байтов в символы на любом языке программирования. Возможно, ваш байтовый массив содержит непечатаемые символы ASCII. Давайте сначала посмотрим, как JDK преобразует byte [] в String:
- Вы можете использовать конструктор String, который принимает байтовый массив и кодировку символов:
1
String str =newString(bytes,"UTF-8");Это правильный способ преобразования байтов в строку, если вы точно знаете, что байты кодируются в кодировке символов, которую вы используете.
- Если вы читаете байтовый массив из любого текстового файла, например, XML-документа, HTML-файла или двоичного файла, вы можете использовать библиотеку Apache Commons IO для непосредственного преобразования FileInputStream в строку. Этот метод также буферизует входные данные для внутреннего использования, поэтому нет необходимости использовать другой BufferedInputStream .
1
String fromStream = IOUtils.toString(fileInputStream,"UTF-8");
Чтобы правильно преобразовать этот байтовый массив в строку, вы должны сначала обнаружить правильную кодировку символов, прочитав метаданные, например Content-Type, <? Xml encoding = ”…”> и т. Д., В зависимости от формата / протокола данных, которые вы читаете. , Это одна из причин, по которой я рекомендую использовать парсеры XML, например парсеры SAX или DOM, для чтения XML-файлов, они сами занимаются кодированием символов.
Некоторые программисты также рекомендуют использовать Charset over String для определения кодировки символов, например, вместо «UTF-8» используйте StandardCharsets.UTF_8, главным образом, чтобы избежать исключения UnsupportedEncodingException в худшем случае. Существует шесть стандартных реализаций Charset, которые гарантированно поддерживаются всеми реализациями платформы Java. Вы можете использовать их вместо указания схемы кодирования в String. Короче говоря, всегда предпочитайте StandardCharsets.ISO_8859_1 вместо «ISO_8859_1», как показано ниже:
|
1
|
String str = IOUtils.toString(fis,StandardCharsets.UTF_8); |
Другие стандартные кодировки, поддерживаемые платформой Java:
- StandardCharsets.ISO_8859_1
- StandardCharsets.US_ASCII
- StandardCharsets.UTF_16
- StandardCharsets.UTF_16BE
- StandardCharsets.UTF_16LE
Если вы читаете байты из входного потока, вы также можете проверить мой предыдущий пост о 5 способах преобразования InputStream в String в Java для получения подробной информации.
Оригинальный XML
Вот наш образец фрагмента XML, демонстрирующий проблемы с использованием кодировки символов по умолчанию. Этот файл содержит букву «é» , которая неправильно отображается в Eclipse, поскольку кодировка символов по умолчанию — Cp1252.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
xml version="1.0" encoding="UTF-8"?><banks> <bank> <name>Industrial & Commercial Bank of China </name> <headquarters> Beijing , China</headquarters> </bank> <bank> <name>Crédit Agricole SA</name> <headquarters>Montrouge, France</headquarters> </bank> <bank> <name>Société Générale</name> <headquarters>Paris, Île-de-France, France</headquarters> </bank></banks> |
И это то, что происходит, когда вы преобразуете байтовый массив в строку без указания кодировки символов, например:
|
1
|
String str = new String(filedata); |
При этом будет использоваться кодировка символов по умолчанию для платформы, в данном случае Cp1252 , потому что мы запускаем эту программу в Eclipse IDE. Вы можете видеть, что буква «é» отображается неправильно.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
xml version="1.0" encoding="UTF-8"?><banks> <bank> <name>Industrial & Commercial Bank of China </name> <headquarters> Beijing , China</headquarters> </bank> <bank> <name>Crédit Agricole SA</name> <headquarters>Montrouge, France</headquarters> </bank> <bank> <name>Société Générale</name> <headquarters>Paris, Île-de-France, France</headquarters> </bank></banks> |
Чтобы это исправить, укажите кодировку символов при создании строки из байтового массива, например
|
1
|
String str = new String(filedata, "UTF-8"); |
Кстати, позвольте мне прояснить, что, хотя я читал XML-файлы с использованием InputStream здесь, это не очень хорошая практика, на самом деле это плохая практика. Вы всегда должны использовать правильные парсеры XML для чтения документов XML. Если вы не знаете, как, пожалуйста, проверьте этот учебник . Поскольку этот пример в основном показывает, почему кодирование символов имеет значение, я выбрал пример, который был легко доступен и выглядит более практичным.
Программа Java для преобразования байтового массива в строку в Java
Вот наш пример программы, чтобы показать, почему полагаться на кодировку символов по умолчанию — плохая идея, и почему вы должны использовать кодировку символов при преобразовании байтового массива в строку в Java. В этой программе мы используем класс IOUtils Apache Commons для непосредственного чтения файла в байтовый массив. Он заботится об открытии / закрытии входного потока, поэтому вам не нужно беспокоиться об утечках файловых дескрипторов. Теперь то, как вы создаете String, используя этот массив , является ключевым. Если вы предоставите правильную кодировку символов, вы получите правильный вывод, в противном случае почти правильный, но неправильный вывод.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
import java.io.FileInputStream;import java.io.IOException;import org.apache.commons.io.IOUtils;/** * Java Program to convert byte array to String. In this example, we have first * read an XML file with character encoding "UTF-8" into byte array and then created * String from that. When you don't specify a character encoding, Java uses * platform's default encoding, which may not be the same if file is a XML document coming from another system, emails, or plain text files fetched from an * HTTP server etc. You must first discover correct character encoding * and then use them while converting byte array to String. * * @author Javin Paul */public class ByteArrayToString{ public static void main(String args[]) throws IOException { System.out.println("Platform Encoding : " + System.getProperty("file.encoding")); FileInputStream fis = new FileInputStream("info.xml"); // Using Apache Commons IOUtils to read file into byte array byte[] filedata = IOUtils.toByteArray(fis); String str = new String(filedata, "UTF-8"); System.out.println(str); }}Output :Platform Encoding : Cp1252<?xml version="1.0" encoding="UTF-8"?><banks> <bank> <name>Industrial & Commercial Bank of China </name> <headquarters> Beijing , China</headquarters> </bank> <bank> <name>Crédit Agricole SA</name> <headquarters>Montrouge, France</headquarters> </bank> <bank> <name>Société Générale</name> <headquarters>Paris, Île-de-France, France</headquarters> </bank></banks> |
Что нужно помнить и лучшие практики
Всегда помните, использование кодировки символов при преобразовании байтового массива в String — не лучшая практика, а обязательная вещь. Вы должны всегда использовать его независимо от языка программирования. Кстати, вы можете принять к сведению следующие вещи, которые помогут вам избежать пары неприятных вопросов:
- Используйте кодировку символов из источника, например Content-Type в файлах HTML, или <? Xml encoding = ”…”>.
- Используйте синтаксический анализатор XML для анализа XML-файлов вместо поиска кодировки символов и чтения ее через InputStream, некоторые вещи лучше оставить только для демонстрационного кода.
- Предпочитайте константы Charset, например, StandardCharsets.UTF_16 вместо строки «UTF-16»
- Никогда не полагайтесь на стандартную схему кодировки платформы
Эти правила также должны применяться при преобразовании символьных данных в байты, например, при преобразовании строки в массив байтов с использованием метода String.getBytes (). В этом случае будет использоваться кодировка символов по умолчанию платформы, вместо этого вам следует использовать перегруженную версию, которая принимает кодировку символов.
Это все о том, как преобразовать байтовый массив в строку в Java . Как вы можете видеть, Java API, в частности класс java.lang.String, предоставляет методы и конструктор, который принимает byte [] и возвращает String (или наоборот), но по умолчанию они полагаются на кодировку символов платформы, что может быть неверно , если байтовый массив создается из файлов XML, данных HTTP-запроса или из сетевых протоколов. Вы должны всегда получать правильную кодировку из самого источника. Если вы хотите узнать больше о том, что каждый программист должен знать о String, вы можете ознакомиться с этой статьей.
| Ссылка: | 2 Примеры преобразования массива Byte [] в String в Java от нашего партнера по JCG Явина Пола из блога Javarevisited . |