
Фото: Гвен
Чем больше сайт или услуга, тем больше запросов на поддержку. И чем длиннее список статей онлайн-справки.
Являются ли они простыми часто задаваемыми вопросами или более практическими инструкциями, как только список достаточно длинный, вы обычно хотите разбить эти элементы на группы для более удобной навигации.
Все идет нормально.
Но что происходит, когда эти группы начинают увеличиваться, и вам нужно сгруппировать элементы, которые содержатся в каждой? На практике вы не всегда хотите разбивать группы на подгруппы с заголовками.
Вот пример:
Читать электронную почту Создать электронное письмо Использовать проверку орфографии Включить смайлики Используйте форматирование, шрифты и цвета Изменить направление текста Добавить файлы как вложения Добавить изображения Добавить изображения в строке Добавить подпись электронной почты Сохранить черновик письма Отправить письмо Ответить на письмо Переслать письмо Получить квитанцию о прочтении
В течение многих лет нам говорили, что меню не должно содержать более семи элементов, но ожидается, что пользователи сети будут использовать длинные списки постоянно — в результатах поиска, в формах и на веб-страницах сайта с обычным контентом.


Столкнувшись с этой проблемой недавно — наряду с проблемой заказа большого количества справочных статей, я решил провести некоторое исследование, чтобы выяснить, могут ли быть лучшие или худшие способы заказа длинных списков справочных статей.
В чем проблема?
Приведенный выше список может показаться вам логичным. Действительно, в этом была вся идея. Это порядок процедурного списка, который я использовал в тесте.
Список начинается с составления электронного письма, затем проходит через все то, что вы могли бы сделать при составлении этого письма, и заканчивается тем, что вы, вероятно, сделаете после этого, например, отправка и пересылка.
Порядок довольно грубый — вы можете утверждать, что статья «Ответить на электронную почту» должна предшествовать статье о создании электронной почты — но вы поняли идею.
С точки зрения «точности» упорядочения, это почти так же хорошо, как и для большинства контент-менеджеров.
Потенциальная проблема с этим типом порядка состоит в том, что темы с одинаковым уровнем глубины (чтение, составление, ответ, пересылка) смешаны в статьях, которые имеют дело с гораздо более детальными задачами, такими как использование смайликов и прикрепление изображений.
Возможно, что пользователи захотят получить представление о параметрах более высокого уровня — более широкой картине возможностей сервиса — прежде чем углубляться в детали. Подобно процедурному списку, этот упорядоченный список также популярен в Интернете.
Этот подход позволяет нам размещать статьи, которые пользователи чаще всего используют, в верхней части списка, поэтому пользователям проще и быстрее получить к ним доступ.
Наш список справки по электронной почте выглядит так:
Читать электронную почту Создать электронное письмо Отправить письмо Ответить на письмо Переслать письмо Получить квитанцию о прочтении Сохранить черновик письма Использовать проверку орфографии Включить смайлики Используйте форматирование, шрифты и цвета Изменить направление текста Добавить файлы как вложения Добавить изображения Добавить изображения в строке Добавить подпись электронной почты
Два надежных и довольно стандартных подхода к упорядочению списков. Но что работает лучше всего?
Наша процедура испытаний
Чтобы быть более конкретным, я решил проверить, какой порядок списков позволяет людям быстрее успешно находить элемент. По сути, я хотел проверить сканируемость списков.
Мой тест проводился в режиме онлайн в виде простого теста одним щелчком мыши с базой данных пользователей, которые прошли обучение на справочном веб-сайте моей организации за последние три месяца.
Я взял приведенные выше элементы списка со страницы справки Google по gmail (см. Более новую и улучшенную версию этого документа ), но упростил их, чтобы было меньше вариантов, и они были более четкими и простыми для чтения.
Я использовал заголовки статей справки по электронной почте в тесте, потому что моя целевая аудитория работает в офисах, и я полагал, что электронная почта была общепринятым инструментом. Я ожидал, что люди не поймут текст вопроса неправильно; единственная проблема — скорость, с которой они могут найти результат.
Вопросы, которые я задавал испытуемым, чтобы ответить с помощью их щелчка:
- Какой элемент в следующем списке расскажет вам, как принять полученное письмо и отправить его другу?
- Какой элемент в следующем списке расскажет вам, как добавить изображение в тело письма?
Если вы сравните вопросы со списками выше, вы увидите, что для каждого списка я задал вопрос, ответ на который был в середине списка, и вопрос, ответ на который был в конце списка. Я сделал это, чтобы увидеть, существенно ли изменилась позиция в списке по сравнению с тем, сколько времени потребовалось пользователям, чтобы найти нужную статью в различных типах списков.
Я задал оба вопроса обоим спискам — всего четыре теста. Тем не менее, каждый участник отвечал только на один вопрос, поэтому ни один пользователь не пользовался преимуществом предварительного знания пунктов списка. Я пригласил пользователей по электронной почте и оставил тест на неделю.
Несколько сюрпризов
Я буду честен: когда я разработал этот тест, я думал, что различия будут измеряться в миллисекундах. Они не были.
Мы видели большое количество кликов — до 44 секунд в некоторых случаях. Таким образом, мы решили, что если испытуемым потребовалось более пяти секунд, чтобы ответить, они прошли сканирование и проигнорировали свой ответ для первоначального анализа.
Другая вещь, которая поразила меня в результатах, было то, как много людей получили неправильные ответы — в одном тесте никто не получил правильный ответ за пять секунд или меньше. Это удивило меня даже больше, чем время щелчка, и означало, что мой анализ должен был учитывать точность и время.
Тем не менее, неправильные ответы дали мне представление о связывании контента, что мы делаем на нашем справочном сайте, как в самих справочных статьях, так и через область связанных статей в верхней части страниц справочных статей.
Например, вопрос о добавлении встроенных изображений побудил многих субъектов щелкнуть по элементу «Составить сообщение», поэтому кажется, что связать все более подробные инструкции с этим обзором более высокого уровня было бы хорошо — и логично — идея.
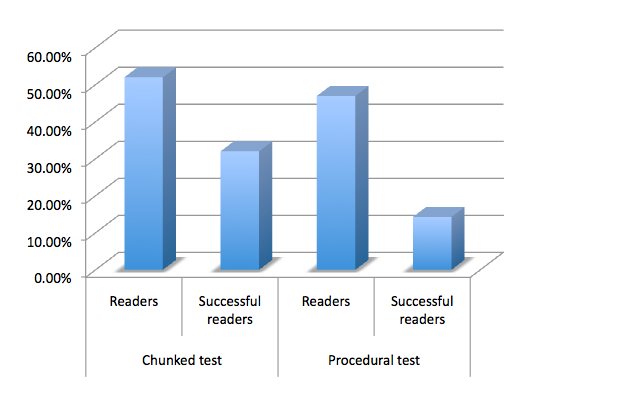
Данные: какой порядок списков работал лучше всего?
На этом графике показана доля субъектов, которые ответили в течение 5 секунд на оба списка (сканеры), и какая доля этих субъектов получила правильный ответ. Эти цифры усредняются для каждого типа теста, поэтому вы можете видеть, как они выполнялись в целом.

Как вы можете видеть здесь, в среднем, тест по частям получил большую долю точных кликов от сканеров.
Так что тесты на куски лучше?
Ну, есть загвоздка Эти цифры являются средними. На самом деле ни один пользователь не просканировал разделенный список, в котором ответ был ближе к концу. Вот цифры разбиты. В тестах с пометкой I ответ был ближе к середине теста, а в тестах с пометкой II — ближе к концу.

Эти результаты указывают на то, что чанкованные списки не работают для сканеров, когда ответ находится не в самом верху.
Мои коллеги по UX были удивлены этим результатом, но мне интересно, предоставляет ли процедурный список подсознательный контекст для элементов, которые он содержит. Я рассуждал, что группировку в тесте на куски было сложнее понять за короткий промежуток времени.
Таким образом, несмотря на то, что тест по частям имел больший успех в целом для сканеров, он полностью провалился для сканеров, которые нуждались в элементе внизу списка. Между тем, процедурный список, казалось, побуждал больше пользователей нажимать кнопку в течение пяти секунд или меньше, но имел сравнительно низкий уровень успеха.
Для меня, как для контент-менеджера, это не однозначный ответ. Должен ли я использовать процедурные списки, чтобы обслуживать пользователей, которым нужны элементы из любой точки списка? Стоит ли использовать списки в тех местах, где я знаю, что подавляющему большинству пользователей понадобятся элементы, которые появятся в верхней половине списка?
Чтобы получить более четкую картину, я решил расширить сферу и проанализировать данные для пользователей, которые ответили до 10 секунд. Я сам знаю, что после примерно 10 секунд сканирования страницы в поисках справочной статьи я готов сдаться, поэтому я подумал, что это щедрое количество времени. Я назвал эту группу читателей.
Результаты были очень интересными. В течение 10-секундного промежутка времени тестовые пользователи могли найти нужный элемент в конце списка. Мало того, но большая часть пользователей достигла успеха в конце списка, а не в процедурном.
Почему это может быть так? Опять же, трудно сказать без дополнительных исследований, но есть несколько возможностей. Возможно, когда пользователи поняли процедуру, они попытались предсказать ее, что снизило точность. Это также может объяснить, почему, хотя очень многие (30,6%) чувствовали себя уверенно, выбирая ответ в течение пяти секунд или менее, так мало из этих ответов были точными.
Или, возможно, те, кто использовал процедурный список, пытались запоминать процедуру в своих умах, что оставляло мало места для оценки пунктов к концу списков. В то же время, возможно, тестируемым пользователям по частям было легче отбрасывать куски в своем сознании, когда они перемещались по списку, что оставляло больше места для обработки оставшихся элементов списка.
В целом, тест по частям достиг точности 32% за 10 секунд, тогда как процедурный тест достиг точности всего 14,3% — результат, который равнялся успеху списка чанков за пятисекундный период.
Так что лучше?
Я думаю, что ответ на этот вопрос может зависеть от того, насколько увлечен ваш пользователь поиском нужного элемента в списке. Если вы не ожидаете, что ваши пользователи будут тратить больше пяти секунд на сканирование списка, вы можете не захотеть оставлять тех, чей ответ находится внизу списка, на холоде.
Но здесь сложно игнорировать статистику. Как на пяти-, так и на 10-секундных таймфреймах тест по частям имел в среднем значительно лучший показатель успеха, чем процедурный тест.
Советы по спискам чанкинга
Вкратце, я хотел объяснить обоснование разбиения списка на случай, если вы захотите попробовать его (или вариант) на своем сайте.
Во-первых, я взял «основные» предметы самого высокого уровня, которые охватывали широкие процедуры. С их помощью я попытался найти предметы, которые образовали естественные группы:
- справка о том, что вы можете сделать с электронной почтой (получить квитанцию о прочтении, сохранить ее)
- справка о том, что вы можете вставить в электронное письмо как контент из программы
- Справка о том, что вы можете прикрепить на электронную почту из другого источника.
Я закалил эти группы с помощью словесной логики, поэтому статьи об изображениях сгруппированы вместе, чтобы обеспечить прямое, параллельное сравнение и, надеюсь, помочь правильному выбору. Мне было бы интересно услышать ваши примеры и обоснование в комментариях.
Последнее замечание об успехе списка
Как я упоминал выше, в этих тестах меня больше всего удивило то, что пользователи успешно выбирают правильный ответ в каждом списке. В этих тестах не более трети пользователей выбрали правильный ответ из списка — и тема была электронная почта, которую мы все используем каждый день.
Конечно, не все раньше использовали встроенные изображения в электронном письме, но я не думал, что эти тесты будут такими же сложными для пользователей, как показывают результаты. На мой взгляд, это может иметь довольно существенные последствия для нашего использования списков в Интернете, в том числе в таких местах, как меню, выпадающие списки на формах, результаты поиска и так далее. 32% успеха при выборе списка по теме, с которой пользователь имеет ежедневный опыт работы? Это правда?
Решение вполне может заключаться в создании небольших списков, но опять же, мы не видим, чтобы это происходило постоянно в сети. Возможно, мы должны.