Фон
Amazon Web Services (AWS) представили свою функцию Elastic MapReduce (EMR) с сообщением об объявлении Amazon Elastic MapReduce, опубликованном Джеффом Барром 2 апреля 2009 года:
Сегодня мы представляем Amazon Elastic MapReduce , наш новый сервис обработки на основе Hadoop. Я потрачу несколько минут на обсуждение общей концепции MapReduce, а затем подробно расскажу об этом новом захватывающем сервисе.
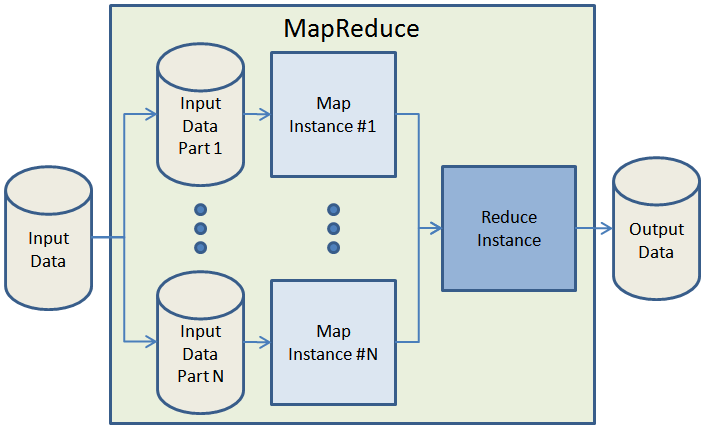
За последние 3 или 4 года ученые, исследователи и коммерческие разработчики признали и приняли модель программирования MapReduce . Изначально описанная в знаковой статье , модель MapReduce идеально подходит для обработки больших наборов данных на кластере процессоров. Легко масштабировать приложение MapReduce до заданий произвольного размера, просто добавляя больше вычислительной мощности. Вот очень простой обзор потока данных в типичном задании MapReduce:
Учитывая, что у вас достаточно вычислительного оборудования, MapReduce заботится о разбиении входных данных на куски более или менее одинакового размера, раскручивая несколько экземпляров обработки для фазы карты (которая по определению должна быть чем-то, что может быть нарушено). вплоть до независимых, распараллеливаемых рабочих блоков) распределение данных по каждому из картографов, отслеживание статуса каждого картографа, маршрутизация результатов карты в фазу сокращения и, наконец, отключение картографов и редукторов по завершении работы. MapReduce легко масштабировать для обработки больших заданий или получения результатов за более короткое время, просто запустив задание в более крупном кластере.
Hadoop — это реализация модели программирования MapReduce с открытым исходным кодом. Если у вас есть оборудование, вы можете следовать указаниям, приведенным в документации по установке кластера Hadoop, и, если повезет, вскоре начать работу. …
Следующие три более ранних публикации OakLeaf охватывают предварительный просмотр Apache Hadoop группы Microsoft SQL Server в Windows Azure (также известный как HadoopOnAzure):
- Импорт наборов данных DataMarket Marketplace Windows Azure в Apache Hadoop в базе данных кустов Windows Azure (4/2/2012)
- Использование данных из BLOB- объектов Windows Azure с Apache Hadoop в Windows Azure CTP (4/4/2012)
- Использование Excel 2010 и драйвера ODBC Hive для визуализации источников данных Hive в Apache Hadoop в Windows Azure (14.04.2012)
В этом руководстве предполагается, что у вас есть учетная запись AWS и вы знакомы с Консолью управления AWS, но не требуется предварительное знание Apache Hadoop, MapReduce или Hive.
Использование образца контекстной рекламы AWS для создания файла feature_index
Контекстная реклама — это название примера приложения AWS Apache Hive. Контекстная реклама Amazon с использованием Apache Hive и статьи Amazon EMR от 25.09.2009, последнее обновление от 15.02.2012, описывает пример сценария приложения следующим образом:
Компания, занимающаяся интернет-рекламой, управляет хранилищем данных, используя Hive и Amazon Elastic MapReduce. Эта компания использует в Amazon EC2 компьютеры, которые обслуживают показы рекламы и перенаправляют клики на рекламируемые сайты. Машины, работающие в Amazon EC2, сохраняют каждое впечатление и щелкают в файлах журналов, отправляемых в Amazon S3.
Хранение логов на Amazon S3
Машины для показа рекламы создают два типа файлов журналов: журналы показов и клики. Каждый раз, когда мы показываем рекламу покупателю, мы добавляем запись в журнал показов. Каждый раз, когда клиент нажимает на объявление, мы добавляем запись в журнал кликов.
Каждые пять минут рекламные автоматы отправляют файл журнала, содержащий последний набор журналов, на Amazon S3. Это позволяет нам производить своевременный анализ журналов. См. Следующую статью о мониторинге работоспособности программ показа объявлений: http://aws.amazon.com/articles/2854.
Машины рекламного сервера помещают свои журналы показов в Amazon S3. Например:
s3://elasticmapreduce/samples/hive-ads/tables/impressions/ dt=2009-04-13-08-05/ec2-12-64-12-12.amazon.com-2009-04-13-08-05.log We put the log data in the elasticmapreduce bucket and include it in a subdirectory called tables/impressions. The impressions directory contains additional directories named such that we can access the data as a partitioned table within Hive. The naming syntax is [Partition column]=[Partition value]. For example: dt=2009-04-13-05.Запуск процесса разработки
Наша первая задача — объединить журналы кликов и показов в одну таблицу, в которой указывается, был ли клик по конкретному объявлению, и информация об этом клике.
Прежде чем мы создадим таблицу, давайте запустим интерактивный поток работ, чтобы мы могли вводить наши команды Hive по одной за раз, чтобы проверить их работу. После проверки команд Hive мы можем использовать их для создания сценария, сохранения сценария в Amazon S3 и создания потока заданий, который выполняет сценарий.
Есть два способа запустить интерактивный поток работ. Вы можете использовать интерфейс командной строки Amazon Elastic MapReduce, доступный по адресу http://aws.amazon.com/developertools/2264, или использовать консоль управления AWS, доступную по адресу http://console.aws.amazon.com.
В этом руководстве используется консоль управления AWS.
Создание корзины S3 для хранения выходных файлов Feature_index приложения Hive
1. Перейдите по адресу http://console.aws.amazon.com , перейдите на вкладку S3 Консоли управления, чтобы открыть страницу Buckets, выберите Create Bucket в списке Actions, чтобы открыть форму с тем же именем, введите имя для bucket. и выберите ближайший к вам регион:

2. Нажмите Создать, чтобы создать корзину, закройте форму и перейдите на вкладку Elastic MapReduce.
Зарегистрируйте учетную запись EMR, если это необходимо
3. Если вы еще этого не сделали, вам будет предложено зарегистрировать учетную запись EMR:

4A. Нажмите кнопку «Зарегистрироваться в Elastic MapReduce», чтобы открыть страницу «Подтверждение личности по телефону», введите номер телефона, к которому у вас есть немедленный доступ, номер телефона и нажмите «Продолжить».
4В. Как правило, менее чем за минуту, робот-координатор попросит вас написать или сказать четырехзначный проверочный код, который отображается на шаге 2. Если он верен, шаг 3 будет отображаться так, как показано здесь:

4C. Нажмите «Продолжить», чтобы отобразить страницу «Обновление учетной записи»:

5. При получении электронного письма следуйте его инструкциям, чтобы вернуться на домашнюю страницу консоли управления EMR:

Добавьте файл feature_index в корзину с помощью запроса Hive
6. Выберите тот же регион, который вы выбрали для группы S3 для размещения проекта, и нажмите кнопку «Создать новый поток работ», чтобы открыть форму «Создать новый поток работ». Введите Имя потока работ, выберите «Запустить образец приложения» и выберите «Контекстная реклама» (скрипт Hive) из списка:

7. При желании нажмите ссылку «Подробнее», чтобы открыть контекстную рекламу с использованием учебника Apache Hive и Amazon EMR, упомянутого в начале этого раздела:

6. Нажмите «Продолжить», чтобы вернуться, чтобы открыть страницу формы «Задать параметры» с указанием местоположений для сценария Hive, входных файлов данных и дополнительных аргументов.

7. Замените заполнитель <yourbucket> на имя контейнера, указанное вами на шаге 1:

8. Нажмите «Продолжить», чтобы открыть страницу «Настройка экземпляров EC2» и принять значения по умолчанию для групп «Основной» (1), «Основной» (2) и «Задача» (0):

Примечание . Вам будет выставлен счет за использование не менее одного часа трех экземпляров EC2 Linux / UNIX = 0,27 долл. США за обработку плюс очень небольшую сумму за передачу данных. Ниже приведен отчет об использовании сеанса, описанного в этой статье:

Операции куста из консоли управления автоматически прекращаются после сохранения окончательных данных в S3.
9. Нажмите «Продолжить», чтобы открыть страницу «Дополнительные параметры». Если вы хотите настроить или запустить задания из командной строки, примите ваши стандартные (или другие) пары ключей и оставшиеся значения по умолчанию:

10. Нажмите «Продолжить», чтобы открыть страницу «Действия Bootstrap» и принять опцию «No Bootstrap Actions» по умолчанию:

11. Нажмите Продолжить, чтобы открыть страницу обзора:

Примечание . Префикс s3n DNS представляет собственный (а не блочный) формат файла S3, что важно, когда вы используете Amazon S3 в качестве источника данных для интерактивных операций Hive с предварительным просмотром Apache Hadoop в Windows Azure в Windows Azure, который будет представлен ниже в этом руководстве.
12. Нажмите Создать поток работ, чтобы закрыть форму и запустить рабочий процесс:

13. Примерно через 10 минут для подготовки экземпляров состояние меняется на RUNNING:

14. Еще через 8 минут для обработки рабочего процесса состояние изменяется на SHUTTING_DOWN:

15. Еще через пару минут состояние изменится на ЗАВЕРШЕНО, а аргументы для операции Hive появятся в столбце Args нижней панели:

16. Перейдите на вкладку S3, выберите <YourBucket> на панели навигации, дважды щелкните имена папок, чтобы перейти в папку <YourBucket> / hive -ads / output / <Date> / feature_index , нажмите кнопку «Свойства» и вкладку «Разрешения». нажмите «Добавить дополнительные разрешения», выберите «Все» в списке «Получатель гранта» и установите флажок «Список», чтобы предоставить общедоступное разрешение на просмотр файла [ов] в этой папке. Выберите файл 00000 , снова нажмите «Добавить дополнительные разрешения», выберите «Все» и установите флажок «Открыть / загрузить», чтобы предоставить общедоступный доступ к файлу:

17. Нажмите Сохранить, чтобы сохранить изменения. Если у вас есть редактор текстовых файлов, который хорошо работает с большими (~ 100 МБ) файлами, такими как TextPad, дважды щелкните имя файла, сохраните его в папке «Загрузки» и откройте его в текстовом редакторе:

Примечание . Формат документа — Apache Hadoop SequenceFile , стандартный формат таблиц Hive, в данном случае несжатый. Вы можете импортировать этот формат в таблицы Hive с помощью команды CREATE EXTERNAL TABLE с модификатором STORED AS SEQUENCEFILE , как описано далее в этом руководстве.
Создание интерактивного Hadoop в таблице кустов Azure из файла Amazon Feature_index
В моем руководстве « Использование данных из больших двоичных объектов Windows Azure с Apache Hadoop для Windows Azure CTP» , упомянутом ранее, описывается, как указать большой двоичный объект Windows Azure в качестве источника данных для интерактивного запроса Hive с помощью предварительного просмотра HadoopOnAzure команды SQL Server. В этом разделе описывается аналогичный процесс, который заменяет файл, созданный на предыдущих этапах, в качестве источника данных таблицы Hive.
В этом разделе предполагается, что вы получили приглашение протестировать Apache Hadoop в Windows Azure Preview. Если нет, перейдите на эту целевую страницу , нажмите на ссылку приглашения и заполните анкету, чтобы получить код приглашения по электронной почте:

Чтобы настроить источник данных S3 и выполнить запросы HiveQL в интерактивном режиме, выполните следующие действия:
1. Перейдите на целевую страницу HadoopOnAzure (HoA) , нажмите «Войти» и укажите свой Live ID и пароль, чтобы открыть главную страницу HoA (см. Шаг 2), если у вас есть активный кластер, или страницу «Запросить кластер», если вы нет. В этом случае введите глобально уникальный префикс DNS для кластера, выберите размер кластера, введите свой административный логин, пароль и подтверждение пароля:

Примечание . Пароли должны содержать заглавные и строчные буквы и цифры. Символы не допускаются. Когда ваш пароль и подтверждение пройдут проверку, кнопка «Запросить кластер» станет активной. Если большой кластер доступен, выберите его. В течение периода предварительного просмотра плата не взимается.
2. Нажмите кнопку «Запросить кластер», чтобы начать подготовку и отобразить ее статус. Через несколько минут открывается главная страница HoA:

Примечание : срок службы кластера составляет 48 часов; вы можете обновить кластер только в течение последних шести часов жизни. Счет истории заданий будет равен 0, если вы ранее не выполняли задания.
3. Нажмите плитку Управление кластером, чтобы открыть страницу с тем же именем:

4. Нажмите кнопку «Настроить S3», чтобы открыть страницу «Загрузить с Amazon S3», введите свой ключ доступа AWS и секретный ключ и примите стандартную файловую систему S3N по умолчанию:

5. Нажмите «Сохранить настройки», чтобы отобразить сообщение «Успешная загрузка Amazon S3», несмотря на то, что вы ничего не загрузили.
6. Дважды щелкните стрелку назад, чтобы вернуться на главную страницу HoA, щелкните плитку Interactive Console, чтобы открыть консоль, и нажмите кнопку Hive, чтобы выбрать функцию Interactive Hive.
7. Введите следующий запрос HiveQL DDL в текстовое поле внизу страницы, чтобы определить связанную таблицу:
CREATE EXTERNAL TABLE feature_index ( feature STRING, ad_id STRING, clicked_percent DOUBLE ) COMMENT 'Amazon EMR Hive Output' STORED AS SEQUENCEFILE LOCATION 's3n://oakleaf-emr/hive-ads/output/2012-05-29/feature_index';

8. Нажмите кнопку Evaluate, чтобы выполнить запрос и создать связанную таблицу Hive:

Примечание . Данные не загружаются, пока вы не выполните запрос, который возвращает строки. Выполнение SELECT COUNT (*) FROM feature_index указывает, что в таблице 1750 650 строк.
9. Откройте список таблиц, который отображает таблицу, которую вы только что создали, и hivesampletable HoA . Список столбцов отображает список имен столбцов выбранной таблицы.
10. Чтобы отобразить первые 20 строк таблицы, нажмите «Очистить экран», а затем введите и выполните следующий запрос HiveQL:
SELECT * FROM feature_index LIMIT 20

11. В разделе «Применение эвристики» контекстной рекламы AWS с использованием статей Apache Hive и Amazon EMR предлагается выполнить следующий пример запроса HiveQL к таблице feature_index «, чтобы увидеть, как он работает для функций« us: safari »и« ua: хром «»:
SELECT ad_id, -sum(log(if(0.0001 > clicked_percent, 0.0001, clicked_percent))) AS value FROM feature_index WHERE feature = 'ua:safari' OR feature = 'ua:chrome' GROUP BY ad_id ORDER BY value DESC LIMIT 100 ;
Согласно статье:
Результатом является реклама, упорядоченная по эвристической оценке вероятности клика. На этом этапе мы могли бы посмотреть рекламные объявления и, возможно, увидеть преобладание рекламных объявлений для продуктов Apple.
Примечание . Исходный запрос отсортирован по возрастанию; сортировка по убыванию сначала дает более интересные результаты (больше шансов на клик):

Вот существенное содержание скрытой истории улья:
2012-05-30 18:34:58,774 Stage-1 map = 0%, reduce = 0% 2012-05-30 18:35:13,836 Stage-1 map = 1%, reduce = 0% 2012-05-30 18:35:16,852 Stage-1 map = 63%, reduce = 0% 2012-05-30 18:35:19,883 Stage-1 map = 100%, reduce = 0% 2012-05-30 18:35:34,899 Stage-1 map = 100%, reduce = 33% 2012-05-30 18:35:37,930 Stage-1 map = 100%, reduce = 100% Ended Job = job_201205301808_0002 Launching Job 2 out of 2 Number of reduce tasks determined at compile time: 1 … 2012-05-30 18:36:05,649 Stage-2 map = 0%, reduce = 0% 2012-05-30 18:36:17,664 Stage-2 map = 50%, reduce = 0% 2012-05-30 18:36:20,680 Stage-2 map = 100%, reduce = 0% 2012-05-30 18:36:35,711 Stage-2 map = 100%, reduce = 100% Ended Job = job_201205301808_0003 OK Time taken: 133.969 seconds