Что такое писец?

Facebook использует Scribe в качестве основного сервиса агрегации журналов. , Описание Github гласит: «Scribe — это сервер для агрегирования данных журнала, передаваемых в реальном времени с большого количества серверов».
Сеть серверов Scribe формирует ориентированный граф. Каждый сервер является узлом, а направленные ребра представляют собой линии связи. Обычно Scribe устанавливается на каждом узле, а журналы собираются на одном гигантском узле-агрегаторе. Собранные журналы записываются в HDFS (распределенная файловая система Hadoop), а затем анализируются с помощью Hadoop MapReduce или Hive.
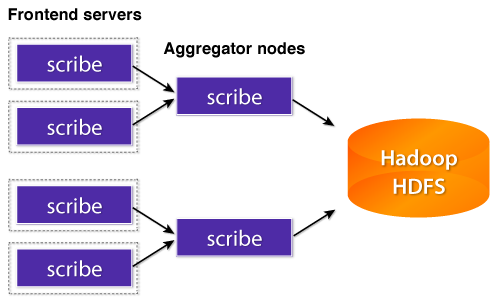
Писец довольно популярен. В дополнение к Facebook, Twitter и Zynga используют Scribe в производстве.
Почему Fluentd?
Писец твердый. Он был эффективно развернут на нескольких веб-узлах с серьезными проблемами масштабируемости. Итак, почему вы переключаетесь на Fluentd? Ответ тройной: 1) Простота управления, 2) Гибкость и 3) Совместимость.
1) Простота управления
Писец безумно сложно правильно установить . Вам не только нужно собирать Boost, Thrift и libhdfs из исходного кода, вы должны выбрать правильные версии программного обеспечения, иначе сборка не удастся. В сущности, установка и развертывание Fluentd очень просты. Он поставляется с пакетами rpm / deb, поддерживаемыми Treasure Data, Inc. (это мы!). Если вы используете Chef (интегрированную среду системной интеграции), вы также можете использовать поваренную книгу, которую мы создали.
2) Гибкость
Писец быстр, потому что он написан на C ++. Но волосатость C ++ делает Scribe трудным для изменения или расширения. С другой стороны, Fluentd написан в ~ 3000 строк Ruby, и вы можете легко настроить и расширить его поведение. С точки зрения производительности Scribe определенно превосходит Fluentd, но Fluentd достаточно компетентен: он поддерживает многопроцессорный режим и может обрабатывать до 20 000 сообщений в секунду на одном хосте. Если это не достаточно хорошо, продолжайте и выберите Scribe. Я надеюсь, что вы не застряли в аду версий ?
3) Совместимость
Благодаря расширяемой конструкции Fluentd уже имеет плагин Scribe, который поддерживает агрегирование журналов через Thrift. Этот плагин на 100% совместим с Scribe и может заменить существующий экземпляр Scribe из коробки.
Просто чтобы продемонстрировать универсальность Fluentd … Fluentd также имеет плагин, который может выводить в Hoop , REST HTTP-шлюз с полной поддержкой операций HDFS. Список всех официально поддерживаемых плагинов можно найти в репозитории Fluent Github .
Установка
Предполагается, что эти плагины устанавливаются вместе с Fluentd.
Пакеты deb / rpm — безусловно, самый простой способ установить все три . Вот соответствующие ссылки:
конфигурация
В этом разделе рассказывается, как заменить систему на основе Scribe системой на основе Fluentd. Не волнуйтесь, это действительно замена.
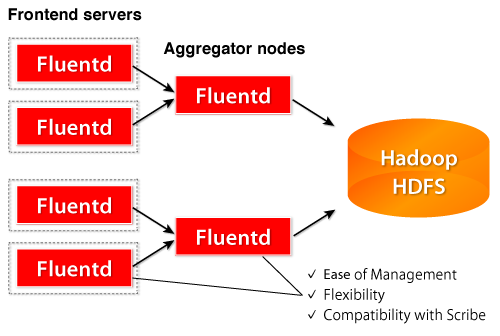
Настройка Fluentd на интерфейсных узлах
Для внешних узлов используется плагин Scribe Input и Output (см. Ниже). Если у вас есть несколько узлов агрегатора, вы можете использовать [Плагин копирования]. ( Http://fluentd.org/doc/plugin.html#copy )
# Scribe Input <source> type scribe port 1463 add_prefix scribe </source> # Scribe Output <match scribe.*> type scribe host log-aggregator-host port 1463 field_ref message </match>
Настройка Fluentd на узлах Log-Aggregator
Узлы агрегатора получают запросы от подключаемого модуля Scribe Input и выводят его в HDFS с помощью подключаемого модуля Hoop. Полученные журналы буферизуются и периодически добавляются к существующим файлам журналов в HDFS.
<source> type scribe port 14631 add_prefix scribe </source> <match scribe.*> type hoop hoop_server hoop-server:14000 path /hoop/%Y%m%d/scribe-%Y%m%d-%H.log username username time_slice_wait 30s flush_interval 5s output_include_time false output_include_tag true output_data_type attr:message add_newline false remove_prefix scribe default_tag unknown </match>
Вывод
Fluentd предоставляет Facebook-подобную инфраструктуру агрегации журналов для ваших серверов Разница лишь в том, что ваша система намного более гибкая и не требует поддержки армии инженеров.