Утверждение: в 2014 году технологии сборки должны быть вездесущими, непогрешимыми, всемогущими и мгновенными.
Контекст: эта статья о командах разработчиков предприятия, которые совместно выпускают сотни сотен сборок в день, работая над функциями или ошибками. Сторонние продукты, которые они используют (Tomcat, Apache. MySql), могут использовать любые технологии сборки, которые им нравятся — это не относится к ним. Речь идет о многомодульном, многоприложенном исходном коде, организованном в «один большой ствол», в котором разные команды сосредоточены на разных вещах из разных или перекрывающихся наборов или каталогов этого дерева исходных текстов. Речь идет о кратчайшем времени сборки из потенциально очень больших деревьев сборки.
Гипотетический пример двух приложений
Скажем, Myapp1 и Myapp2 поддерживаются разными проектными командами и запускаются в производство с разными темпами выпуска. Они оба зависят от одних и тех же библиотек: log4j (третья сторона) и «общие» (что-то сделанное собственными силами). Оба находятся в одной ветви (стволе) одного и того же репо.
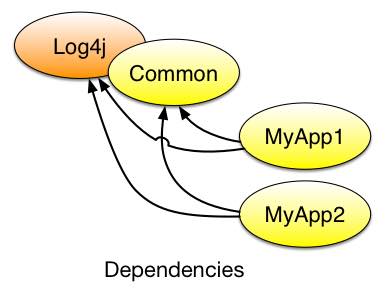
Что означает мой заголовок
Запуск второй сборки сразу после первой должен быть как можно ближе к мгновенному, если между двумя сборками ничего не изменилось.
Что касается хорошо известной тестовой пирамиды (запись в блоге Мартина Фаулера о публикации Майка Кона), мы считаем, что тесты — это одно из следующего:
- единица измерения (каждый тест составляет <1 мс)
- интеграция / сервис (каждый <1 секунда)
- прием / функционал (селен и т. д. и, возможно, длительностью более 1 секунды каждый)
Google также писал об этом с размерами тестов в 2010 году, и они внедрили их в свою инфраструктуру сборки как минимум с 2007 года (до публикации Mike Cohn).
В современных сборках, ориентированных на CD, как разработчики (или демоны CI), мы бы регулярно делали одну из них по выбору:
- компилировать только сборки
- компиляция с последующими тестами, которые не требуют развертывания приложения / службы
- компиляция с последующими тестами, включая функциональные / приемочные тесты, которые требуют развертывания приложения / сервиса
Можно выполнить полные тесты Selenium (приемочные / функциональные) для компонентов за пределами развертывания более крупного приложения, но большинство компаний еще этого не делают.
Для нашего надуманного примера с двумя приложениями мы должны проанализировать график дополнительных триггеров для этапов сборки:
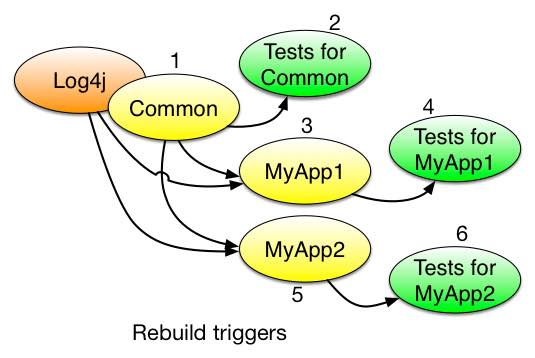
В дополнение к источнику для этого узла, конечно, меняется.
Как это бывает, 3 и 5 могут или должны происходить параллельно. Если это может произойти, то 4 и 6 также могут быть параллельны как следствие.
Пропуск компиляции, когда она не нужна
Если вы только что сделали сборку, и ничего больше не изменилось, вам не нужно перекомпилировать объектный код. Для этого вам нужно отследить, какой исходный код создан, какой объектный код. Чтобы сделать это, вам нужно сопоставить временные метки между первым, который создал второе. В качестве альтернативы, учитывая, что это наивно, было бы разумнее полагаться на хеш-функции источника и других входных данных, которые создали объектный код. В этом случае может быть лучше работать на уровне каталогов, чем на уровне исходного файла, хотя здесь есть некоторые компромиссы в скорости. Вы могли бы доказать, что версия для отслеживания исходного файла и метки времени не является непогрешимой (по крайней мере, для некоторых языков).
Компиляция артефактов, являющихся идемпотентами, является ключевой здесь. Безошибочный аспект здесь означает, что компиляция не должна быть пропущена, если компиляция не удалась — вы должны быть на 100% уверены, что она не потерпит неудачу, и ранее созданный двоичный файл — это то, что было бы сгенерировано им.
Пропуск тестов, когда они не нужны
Пропуск тестов — более сложное решение. Наивная реализация может пропустить тесты, если prod-source, test-source и все соответствующие входные данные не изменились с момента последнего запуска. О, И последний прогон дал 100% прохождения тестов. Зависимости (включая переходные) могут изменить это все же. Будь то бинарный или исходный код (из-за пределов рассматриваемого модуля), если они изменились, то тот факт, что предыдущая компиляция / сборка прошла 100% прохождение тестов, не имеет значения. Непогрешимый аспект здесь означает, что технология сборки не должна пропускать тесты (указывая, что они все должны пройти), когда некоторые из них не пройдут.
Еще более сложным является то, что тесты могут быть подгруппами. Возможно, вы выполняли только модульные тесты в предыдущем запуске (пропуская интеграцию / обслуживание и приемку / функционирование). Если вы не выполняете подобный набор аналогичным образом в этом запуске, система сборки должна знать, как оптимизировать какие тесты нужно запускать или можно / нужно пропустить в следующей сборке.
Использование коллег последних сборок.
Скажем, вы и «Джимми» оба вернулись из отпуска, но Джимми работает на 30 минут раньше вас. Все, что он делает, ты тоже собираешься делать, но через 30 минут. Он догоняет источник контроля ( svn вверх или git pull). Он выпускает сборку, которая из-за того, что он некоторое время отсутствовал, занимает 15 минут — много нового для последней сборки, которую он сделал перед отпуском.
Когда вы входите, вы делаете то же самое в управлении исходным кодом, но ваша сборка занимает 2 минуты. Зачем? Ваша сборка должна иметь возможность извлекать скомпилированные артефакты из системы Джимми (при условии, что та же версия компилятора). Конечно, он, возможно, уже очистил свои артефакты сборки, но технология сборки должна была поместить их в общий кеш для использования ближайшими людьми или демонами. Очевидно, что в кэше могут быть некоторые аспекты LRU, поэтому я сделал этот очень надуманный случай с точки зрения времени. Как это случается, худший сценарий Джимми (15 минут), вероятно, также не был реализован, если в команде было больше людей, которые недавно строили HEAD.
У меня тоже есть потребности.
Для каждого конвейера сборки подчиненные узлы CI должны будут использовать артефакты сборки друг друга и результаты тестирования. В промежутке между назначенными сборками они должны приложить усилия, чтобы наверстать упущенное в последней известной редакции проходящей сборки И артефактах и результатах испытаний (все проходящие явно).
Buck от Facebookers (и бывших Googlers)
Buck — это попытка нацелить многоязычную исходную реальность на крупные компании и сократить время сборки до абсолютного минимума. Саймон Стюарт (Mr WebDriver) — один из техников Facebook, возглавляющий усилия. Он бывший Google и ThoughtWorks тоже. Он хорошо помнит легендарную систему сборки Blaze от Google , которая раньше была Googler. Он также сделал CrazyFun для сборки Selenium2 по его образу (в то время как Гуглер). Я писал о Баке, когда он был запущен . В тот же день Томас Бройер пошел глубже .
Перед этапами фактической компиляции и тестирования контролирующий процесс просматривает график источника для проверки:
1. все ли зависимые модули доступны в проверке
2. есть ли циклические зависимости в вышеприведенном
3. какие производственные исходные наборы нужно перестроить
4. какие тестовые исходные наборы нужно перестроить
5. есть ли ранее созданный объектный код, доступный в общий кеш
6. есть ли предыдущие общие результаты теста в общем кеше
Саймон говорит мне, что удаление кеша не обязательно должно быть LRU, и что продвинутые системы могут вычислять стоимость артефакта и сохранять самые дорогие. Он также отмечает, что каждая цель рассматривается как чистая функция. В частности, если входные данные не изменились, ожидается, что выходные данные будут идентичными.
Maven: последние улучшения
Maven является доминирующей системой сборки Java-экосистемы. Это было в течение десяти или более лет. Jason van Zyl является его создателем, и хотя сейчас он обычно размещается в Apache, его архитектура плагинов очень открыта, и легко добавлять модифицированные или альтернативные плагины издалека. Раньше Maven был чисто итеративным в прохождении деревьев модулей для сборки.
Новая бутик-консалтинговая компания Jason, расположенная рядом с Maven, называется takari.io . Из многих навыков, которыми обладает Джейсон, стоит отметить упорство. Мэйвен периодически подвергается критике на протяжении многих лет, но он продолжает продвигаться вперед — Джейсон продолжает настаивать на этом — никогда не стоит недооценивать свою готовность продолжать продвигаться вперед.
Maven Smart builder — это новейшая инициатива, которую Джейсон возглавляет и руководит ею, руководствуясь потребностями своего клиента. Он пропускает этапы, если может, из-за идемпотентных артефактов сборки. Более новый Maven теперь гораздо эффективнее многопоточный. Это в значительной степени путь миграции для существующих команд Maven, который проталкивается на территорию «повторяющихся сборок». С этой инициативой приходит сфокусированный API инкрементной сборки, элемент «умного компоновщика» и, возможно, даже новый демон CI, настроенный на потребности предприятия для сборок Maven.
Различия между Maven и Buck.
Бак пытается быть гораздо более нейтральным языком. Python (включая тестовый вызов и создание двоичного файла / библиотеки) покрыт. Java тоже (Android и J2SE), а также C и C ++. Пока нет ни Ruby, ни DotNet, но материалы приветствуются. Buck также Unix только пока — без возможности Windows — хотя команда хочет туда попасть.
Maven представляет экосистему Java, которая включает в себя языки Groovy, Clojure и Scala. Тем не менее, он также обрабатывает проекты C ++. Он также имеет первоклассную поддержку для извлечения зависимостей из ‘Maven Central’ и публикации там опубликованных артефактов. Maven работает на Windows, Linux и Mac.
У Buck есть демон, развернутый на вашей рабочей станции — «buckd», который следит за тем, что происходит с исходными файлами, и передает их в сборку для правильной оптимизации. Подобный «mavend» готовится к выходу.
Исходный макет
Рассмотрим исходные деревья для гипотетического примера:
Исходный макет Maven (файл сборки pom.xml):
<root>
pom.xml
common/
pom.xml
src/
main/
java/
com/
mycompany/
common/
(*.java source as expected)
webapp/
(perhaps JavaScript is in here)
test/
java/
com/
mycompany/
common/
(*.java test source as expected)
myapp1/
pom.xml
src/
(*.java prod and test source as expected, at deeper packages)
myapp2/
pom.xml
src/
(*.java prod and test source as expected, at deeper packages)
Исходный макет Бака (файлы BUCK указывают на грамматику сборки):
<root>
BUCK
java/
src/
com/
mycompany/
common/
BUCK
(*.java source as expected)
myapp1/
BUCK
(*.java source as expected)
myapp2/
BUCK
(*.java source as expected)
test/
com/
mycompany/
common/
BUCK
(*.java test source as expected)
myapp1/
BUCK
(*.java test source as expected)
myapp2/
BUCK
(*.java test source as expected)
javascript/
(showing a hypothetical two-language situation)
third_party/
log4j.jar
Поддержка SCM для редких проверок
Subversion, естественно, позволяет вам извлекать из подкаталога, если это имеет смысл для вас. Git и Mercurial разрешают извлечения только из корневого каталога. Perforce позволяет вам определить спецификацию клиента, которая может эффективно скрывать корневой узел (то есть он похож на Subversion).
Subversion позволяет вам выполнять «разреженную проверку» из корня нерекурсивным способом, а затем указывать подмножество каталогов для дальнейшей проверки (и отслеживать дальнейшие действия). Git также имеет «разреженную проверку», но связанный клон не является разреженным. У Mercurial также есть что-то, что входит в этот дизайн. Perforce, используя ту же спецификацию клиента, позволяет включать или исключать каталоги в любом месте глубже, чем root. Бак полностью придерживается такого способа работы, как и Блейз до него. Вот так вы управляете большим набором ревизий HEAD для модели «один большой ствол» вплоть до интересующих вас кусочков.
Бак и новый Maven будут работать с частичной проверкой, но только если критический модуль не пропущен. Разработчик предпочитает извлекать каталоги common и myapp1 (но не myapp2)… Buck и Maven по-прежнему будут создавать для него правильные артефакты из root и запускать для них тесты. Только если это возможно, хотя, как я уже сказал, вы не сможете оформить заказ myapp1 без общего (для моего надуманного примера).
Maven также позволяет использовать подмножество. Вы можете извлекать из любого подкаталога с pom.xml в них, и строить оттуда. В этом случае Maven будет извлекать зависимые артефакты из репозитория Maven, который он настроен для использования. Если родительский модуль предлагает выполнить возврат в myapp2, но его нет в редкой проверке, то последний Maven не завершится с ошибкой.
Сторонние библиотеки
Естественная склонность Maven — извлекать сторонние зависимости из локального репозитория Maven (который, в свою очередь, мог прийти из «Центрального»). До Maven даже сообщество Java привыкло проверять бинарные зависимости. Экосистема Maven настолько доминирует в технологиях сборки Java, что даже конкурирующие технологии сборки (Gradle и т. Д.) Сбивают с толку «Maven Central». Maven естественно помещает их в папку .m2 / в вашем домашнем каталоге. Примером является «тестовая» зависимость «junit-4.12.jar». Обратите внимание, что он находится в репозитории с 4.12 в имени файла, что означает, что некоторые модули могут зависеть от разных версий. Последнее означает, что обновления на этапе блокировки не нужны, и конфликты должны обнаруживаться самим Maven во время сборки, прежде чем они вызовут сложные проблемы во время выполнения.
Бак, как и Blaze до этого, извлекает зависимости относительно извлеченного каталога. Классически это третий каталог / root в корневом каталоге. Это не подстановочный знак, включенный в пути сборки. Вместо этого каждая зависимость указана в грамматике сборки BUCK как зависимость. Что касается тестовой зависимости от junit — в имени файла это будет в third_party / без 4.12, то есть никакие модули вообще не могут зависеть от разных версий. Последнее означает, что обновления с блокировкой по ступенькам — это нормально.
Гипотетически для Maven, вы могли бы вытащить зависимости относительно (той трети_каталога / каталога) из той же проверки, но никто этого не делает. Я хотел бы видеть, что исследуется больше. Особенно, когда Git решает проблемы с бинарными файлами.
Построить заказ
И Maven, и Buck будут строить модули по порядку. По ходу дела они вырабатывают, какие строить, чтобы вступить и когда предварительные условия способствуют этому. Если бы MyApp1 и MyApp2 были в кассе, то сначала были бы созданы общие, MyApp1 и MyApp2 (возможно, параллельно с учетом улучшений Takari).
Бак выберет быстрый сбой, если с самого начала отсутствуют зависимости. Maven может потерпеть неудачу частично, если отсутствуют зависимости, потому что он методично повторяется. Однако Maven быстро потерпит неудачу, если между самими модулями существует круговая зависимость.
Maven также сначала быстро создает крошечный родительский модуль — точно так же, как повторно используемая памятка об отношениях родитель / потомок и любые данные, которые могут быть использованы во время выполнения, которые были общими для всех.
Maven еще не совсем вездесущ в отношении пропуска тестового выполнения, но Джейсон говорит, что это произойдет.
Этапы 4 и 6 (и 5 и 7) распараллелены как Maven, так и Buck.
Один большой багажник.
В наши дни мы сталкиваемся с множеством компаний, у которых «много стволов». Возможно, они пьют из SOA или MicroServices, и у них есть много репозиториев Subversion — по одному для каждой службы. Они сами сообщают, что на самом деле занимаются разработкой на основе магистрали. Это действительно никогда не то, что мы имели в виду, когда мы выступали за развитие на основе магистральных сетей — особенно для предприятий. Мы имели в виду «один большой багажник». Один, а не много. Возможно, нам придется по-настоящему сосредоточиться на названии «Один большой ствол» в будущем, чтобы дифференцироваться.
Саймон писал об этом раньше . Я тоже написал несколько.
Минималистичное выполнение теста через хаки
Я не предоставляю программное обеспечение здесь, просто то, что вам нужно, рецепт:
- В задании сборки CI, которое, возможно, всегда выполняется с HEAD, запустите один тест изолированно, чтобы вы могли определить, какие исходные файлы использовались во время его выполнения. Запишите строку «ProdSourceFileName» в файл, который заканчивается в текстовом файле TestSourceFileName.sourcesUsed рядом с фактическим исходным файлом теста. Может быть, это скрытый файл. Может быть, это скрытая папка (сохраните пути тоже). Проверьте этот файл в репо. Да, тот же репо. Да, отметьте это. Да, люди получат это, если они «svn up» (или эквивалентный).
- Возьмите все эти файлы (возможно, ежедневно), переверните информацию и напишите новый текстовый файл (или JSON или XML). Строки в нем будут «SourcePathAndFileName (пробел) TestFilePathAndName (возврат каретки). Проверьте это тоже — возможно, в корне — попробуйте убедиться, что файл отсортирован последовательно (для облегчения сравнения).
- Создайте режим работы для своего тестового организатора, который использует новый метафайл, чтобы сократить всю вашу базу тестов до тех, на которые влияют модификации, с которыми вы имеете дело (через «svn status» или эквивалентный).
Было бы неплохо, если бы это было связано с методами, а не с источниками, но собрать их гораздо сложнее. Обратите внимание, что охват кода не является одинаковым для всех языков, равно как и отношения между исходным файлом и объектным кодом.