Это никогда по-настоящему приятно просыпаться с чем-то вроде этого:
Это был я был pwned? (HIBP) первым делом мое субботнее утро. Отключение сопровождалось большим количеством автоматических уведомлений по электронной почте и ручными напоминаниями от заинтересованных граждан о том, что мой сайт действительно не работает. Закрытие моего демонстрационного сайта Azure в тот же момент, когда был запущен мой курс Pluralsight по Azure — Модернизация веб-сайтов с помощью платформы Azure как службы, — только повредило рану.
Но, как я уже писал ранее, облако на самом деле идет вниз . Если кто-то скажет вам, что это не так, они в корне неправильно понимают механику, которая лежит в основе того, что в конечном итоге все еще представляет собой группу компьютеров, работающих [что-то] в качестве службы. Хотя вы, безусловно, можете получить гораздо более высокую степень устойчивости к сбоям, вы не получаете 100% времени безотказной работы, и именно поэтому существуют SLA в вышеупомянутом сообщении в блоге.
В этом случае облако хорошо и по-настоящему опустилось, и достаточно взглянуть на страницу состояния Azure, чтобы увидеть, в чем проблема:

Теперь, когда я говорю «облако может спуститься», давайте просто уточним эту позицию немного точнее, посмотрев, что именно там, где было:
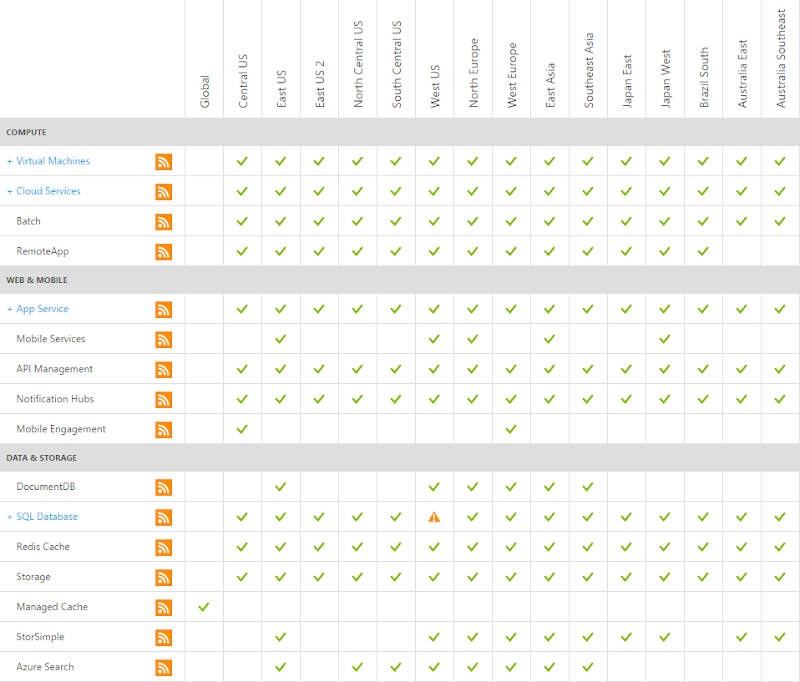
Одно дело в одном месте, и я тоже сократил этот список, чтобы вы не видели десятки других сервисов (например, медиа-сервисы, Active Directory, Backup). На самом деле, это было даже лучше (хуже?), Чем это, потому что согласно более раннему объяснению с портала, это затронуло только часть клиентов в дата-центре в Западной Америке. Я обнаружил, что мой пример уязвимого веб-сайта Hack Yourself First работает прекрасно и находится в том же месте. Как бы я ни был недоволен ситуацией, «облако спускается» будет сильно преувеличивать то, что в конечном итоге составило очень небольшую долю неправильного поведения экосистемы. Несмотря на это, это означало, что HIBP был кактусом.
Слабый медленный
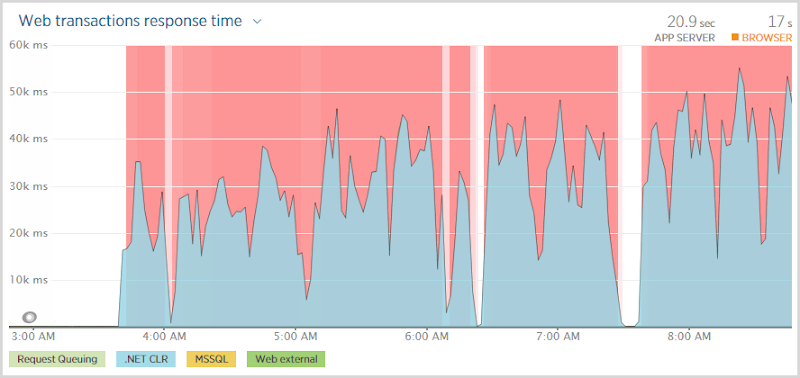
Отключение означало, что любой, кто заходил на сайт, сталкивался с этим:
And they waited. And waited. And waited. In fact if you look at that first graph above, they were waiting somewhere between 30 and 50 seconds before being told that hey, you’re not going to get anything. Now this isn’t a particularly positive user experience and it’s also not great news for the site to have all these threads sitting there taking ages to establish that something which normally should happen in milliseconds is not happening at all. (Not the site was going to be doing much else without a database anyway…)
This is the problem with timeouts; you want them configured at a comfortable threshold to allow things that might genuinely take a bit of time to process successfully but then when fast things go wrong, you’re waiting ages to find out about it. The question, of course, was which timeout was eventually being hit – the DB command? The connection? The web request? You need visibility to the internal exception for that.
Understanding SQL Azure Execution Strategies
As I’ve written before, I use Raygun extensively for logging those pesky unhandled exceptions and it was very clearly telling me where the problem was:

I did indeed have an execution strategy with 5 retries, it looks just like this:
SetExecutionStrategy("System.Data.SqlClient", () => new SqlAzureExecutionStrategy(5, TimeSpan.FromSeconds(3)));
Now SqlAzureExecutionStrategy can be both a blessing and a curse. It can be great for resiliency insofar as it can retry database transactions without you needing to code it yourself but it can also be downright stubborn and keep trying things it probably shouldn’t thus leading to the problem we see here now. So I disabled it entirely, just an immediate term approach, and saw this:
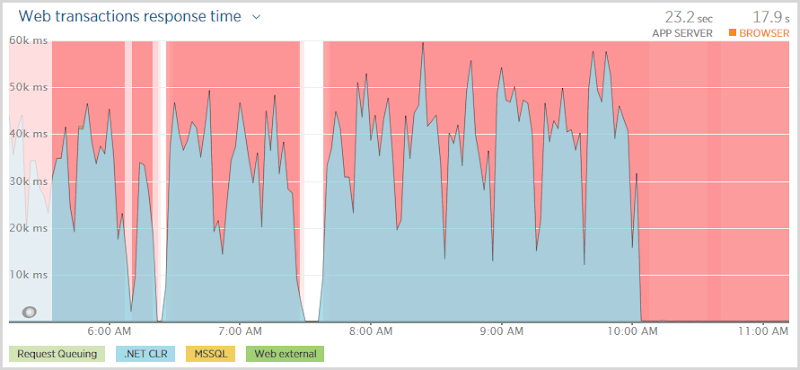
Of course none of this means that the site isn’t totally stuffed, but what it does mean is that rather than having people sitting around thinking “I wonder if this thing is stuffed?”, they immediately get this:

Which all begs the question – what was going wrong with the execution strategy? I mean if having no execution caused the system to immediately recognise that it couldn’t connect to the database and return an appropriate response, shouldn’t the execution strategy merely cause 5 immediate consecutive failures resulting in a response almost as quickly?
Confused, I reached out to good friend and Entity Framework extraordinaire Julie Lerman. In that earlier code snippet, there was a max retry count of 5 (which was exceeded) and a max delay of 3 seconds between those retries. Julie explained that the actual delay is calculated based on a variety of factors including what other processes experiencing the same problem are doing and a formula which also takes into account the retries. There’s a clip in her Pluralsight course Entity Framework 6: Ninja Edition — What’s New in EF6 called “Digging into the connection resiliency feature” which explains all this very elegantly and shows the internal implementation within EF. She also shows how to fake a transient failure which then causes the execution strategy to retry so I dropped that into the site, just to confirm suspicions…
And I confirmed very little. With my execution strategy, I consistently saw a 10 second response time which was enough to retry 5 times but well under the 30 seconds plus I was seeing on the transactions. I reverted the execution strategy to the default and now I was constantly seeing 27 seconds, all locally of course so no network latency or other requests being queued. Under these circumstances I could envisage 30 seconds plus, particularly as requests got backed up whilst sitting there waiting to execute. So my only conclusion at this point is that I screwed up the execution strategy somewhere along the line and it was the default one being implemented. Next step would probably be to hook into the ReaderExecuting event within IDbCommandInterceptor (another takeaway from Julie’s course) and figure out exactly when those connections are being made and if indeed there is something else causing delays before, after or within each execution.
It’s not easy testing unpredictable failures like this because, well, they’re kinda unpredictable. However I love Julie’s approach of causing a transient failure to see how the app behaves when things go wrong. One conclusion I did reach with her is that in a scenario like this, you ideally want multiple data contexts as the execution strategy applies to the whole thing. The front page of HIBP only needs to make a tiny DB hit which pulls back a few dozen records (and even that is cached for 5 mins), so it’s highly unlikely to fail due to any sort of organic timeout or race condition or other sort of DB scenario you might legitimately hit under normal usage. The execution strategy should be different and it should fail early so that’s now well and truly on the “to do” list because sooner or later, it’ll happen again. I mentioned the cloud can go down, right?
The cloud can go down – plan for it
Lastly, on that outage – it was a big one. There’s no way to sugar coat the fact that it took HIBP down for 11 hours so for this incident alone, my availability is going to be at about 98.5% for the month which is way down on the Azure SQL Database SLA of 99.99% for a standard DB. I know I said it before, but the cloud goes down and not just within the outage the SLA implies. The SLA isn’t a guarantee of availability, but rather a promise that you’ll get some cash back if it’s not met. Regardless of the cloud provider, you need to expect downtime and all of them have had periods of many hours where one or more things just simply don’t work. Expect that. Plan for that and if it’s going to cause significant business impact then prepare in advance and build out more resiliency. A geo-redundant replication of my database and website, for example, would have avoided extended downtime. It’s not worth it for a free service like HIBP, but you’d seriously consider it if it was a revenue generating site where downtime translated directly into dollars.
Learn more about Azure on Pluralsight

As I mentioned earlier, I’ve just launched a new Pluralsight course and it’s actually the first one I’ve done that isn’t about security! Modernizing Your Websites with Azure Platform as a Service contains a heap of practical lessons on using Azure Websites and Azure SQL Databases (both are Microsoft’s PaaS offerings) and a significant amount of the content in that course has come from real world experiences like this ones learned while building and managing HIBP. It’s very practical, very hands on and a great resource if you want to learn more about the mechanics of how to use Azure websites and databases in the real world.