Docker SDN ( Software Defined Network ) уже существует довольно давно. Начиная с выпуска 1.11 нововведением является добавление циклического распределения нагрузки DNS . Это и повод для праздника, и возможность изучить сеть Docker и DNS . Мы рассмотрим внутреннюю и внешнюю сеть, посмотрим, как DNS вписывается в картину, обсудим варианты использования, которые могли бы подойти, и закончим с плюсами и минусами.
Начнем с самого начала. Поскольку я не знаю, являетесь ли вы пользователем Mac, Windows или Linux, мы создадим несколько виртуальных машин под управлением Ubuntu и будем использовать их для имитации кластера Docker Swarm.
Настройка кластера
Единственные требования к приведенным ниже примерам — это Vagrant и Git . Я выбрал Vagrant вместо Docker Machine, чтобы каждый мог использовать одни и те же команды независимо от того, является ли ОС хоста Linux, OS X или Windows. Описанные здесь принципы одинаковы, независимо от того, как вы настраиваете хосты Docker.
Пожалуйста, убедитесь, что Vagrant и Git установлены на вашем ноутбуке. Все остальное будет предоставлено автоматически.
Давайте идти. Команды, которые будут создавать и предоставлять виртуальные машины, следующие.
|
1
2
3
4
5
6
7
|
git clone https://github.com/vfarcic/docker-flow-proxy.gitcd docker-flowvagrant plugin install vagrant-cachiervagrant up swarm-master swarm-node-1 swarm-node-2 proxy |
Когда выполнение команды vagrant up закончится, у нас будет обычно используемая конфигурация кластера Docker Swarm. На прокси- узле размещается Консул, который будет служить в качестве реестра служб. На данный момент прокси сервис отсутствует (подробнее об этом позже). На сервере swarm-master будет работать Swarm в режиме master . Наконец, два узла кластера ( swarm-node-1 и swarm-node-2 ) также работают под управлением Swarm, но на этот раз в режиме узлов . Узлы кластера также содержат регистратор, который будет следить за тем, чтобы все контейнеры, работающие в кластере, были зарегистрированы в Consul . Я не буду углубляться в объяснение настройки кластера, а сосредоточусь на сетевых возможностях Docker и функциях DNS.
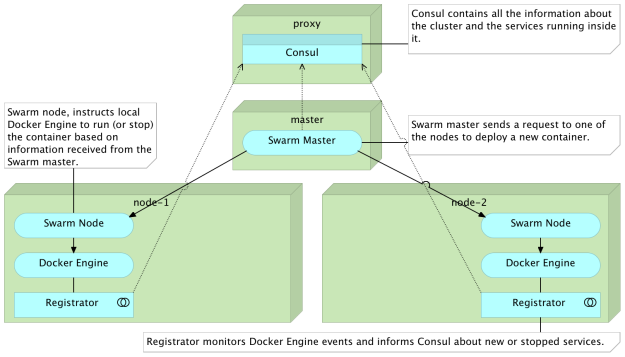
Настройка роевого кластера через Vagrant
Давайте войдем в виртуальную машину-посредник и начнем изучать различные сетевые варианты.
|
1
2
3
|
vagrant ssh proxycd /vagrant/articles/dns |
Каталог dns содержит весь код, который нам понадобится в этой статье.
Автоматическое создание Docker Network
Давайте посмотрим, как работает Docker. Мы запустим простой сервис, состоящий из двух контейнеров. Они определены как цели app и db внутри файла docker-compose-internal.yml . Его содержание заключается в следующем.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
version: '2'services: app: image: vfarcic/books-ms ports: - 8080 environment: - DB_HOST=books-ms-db depends_on: - db db: container_name: books-ms-db image: mongo environment: - SERVICE_NAME=books-ms-db |
Это определение не содержит ничего, связанного с сетью, поэтому мы пропустим объяснение и запустим контейнеры.
|
1
2
3
4
5
|
export DOCKER_HOST=tcp://swarm-master:2375docker-compose \ -f docker-compose-internal.yml \ up -d app |
Мы указали, что переменная DOCKER_HOST должна указывать на мастер Swarm и запускать целевое app Docker Compose. Поскольку в определении цели app указано, что она зависит от db , также был запущен контейнер books-ms-db .
Вывод команды up выглядит следующим образом.
|
1
2
3
4
5
|
Creating network "dns_default" with the default driver...Creating books-ms-db...Creating dns_app_1 |
Если не указано иное, Docker Compose всегда создает сеть по умолчанию для всех контейнеров, принадлежащих проекту. Если не указано с помощью аргумента -p , проект эквивалентен каталогу, в котором находится файл Compose (в данном случае dns ). Поэтому, как видно из вывода, Docker Compose создал новую сеть с именем dns_default .
Давайте подтвердим, что только что запущенные контейнеры действительно находятся во вновь созданной сети. Мы можем, например, попытаться пропинговать контейнер books-ms-db из контейнера dns_app_1 .
|
1
|
docker exec -it dns_app_1 ping -c 1 books-ms-db |
Вывод команды exec выглядит следующим образом.
|
1
2
3
4
5
|
PING books-ms-db (10.0.0.2): 56 data bytes64 bytes from 10.0.0.2: icmp_seq=0 ttl=64 time=0.055 ms--- books-ms-db ping statistics ---1 packets transmitted, 1 packets received, 0% packet lossround-trip min/avg/max/stddev = 0.055/0.055/0.055/0.000 ms |
Мы можем видеть, что оба контейнера находятся в одной сети и что IP 10.0.0.2 был назначен для books-ms-db . Поскольку эти два контейнера были развернуты с помощью Swarm, они работают на разных серверах. Мы даже не знаем (без перечисления процессов или запросов к Консулу), где работает каждый из этих контейнеров. Дело в том, что в этом случае нам не нужно знать IP-адрес сервера, на котором работает контейнер. Пока он принадлежит к той же сети, он доступен по его имени.
Мы можем инвертировать ситуацию и dns_app_1 контейнер dns_app_1 из контейнера books-ms-db .
|
1
|
docker exec -it books-ms-db ping -c 1 dns_app_1 |
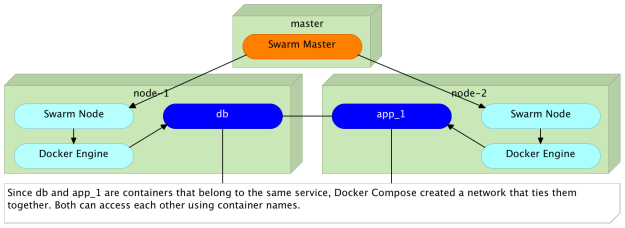
Все контейнеры, которые формируют один и тот же сервис (определенный в одном файле docker-compose.yml), находятся в одной сети
Давайте посмотрим, что произойдет, если мы дадим команду Swarm развернуть дополнительный экземпляр цели приложения .
|
1
|
docker-compose -f docker-compose-internal.yml scale app=2 |
На этот раз цель приложения масштабируется до двух экземпляров, и мы можем повторить команды ping для всех контейнеров.
|
1
2
3
4
5
|
docker exec -it dns_app_1 ping -c 1 dns_app_2docker exec -it dns_app_2 ping -c 1 dns_app_1docker exec -it dns_app_2 ping -c 1 books-ms-db |
Как и ожидалось, все три контейнера могут быть доступны друг от друга. Поскольку они принадлежат одному и тому же проекту (одному и тому же файлу Docker Compose), Docker поместил их все в одну сеть и назначил разные IP-адреса каждому. Результат один и тот же, независимо от того, созданы ли все контейнеры одновременно или запущены позже.
Что произойдет, если мы запустим новый контейнер, который на этот раз не принадлежит одному и тому же проекту Compose?
|
1
|
docker run -it --rm alpine ping books-ms-db |
Вывод команды run выглядит следующим образом.
|
1
|
ping: bad address 'books-ms-db' |
Поскольку мы запускаем контейнер, который не был определен в том же проекте Docker Compose, он не был добавлен в ту же сеть и, следовательно, он не мог получить доступ к другим контейнерам.
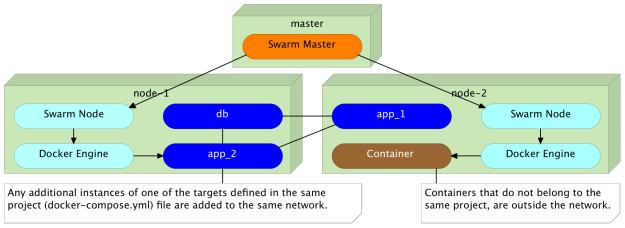
Любые дополнительные экземпляры одной из целей, определенных в том же файле docker-compose.yml, добавляются в ту же сеть.
Означает ли это, что контейнеры могут связываться друг с другом, только если они принадлежат одному и тому же проекту Compose?
Прежде чем мы попытаемся ответить на этот вопрос, давайте уничтожим контейнеры и начнем все сначала.
|
1
2
3
|
docker-compose \ -f docker-compose-internal.yml \ down |
Напомним, что когда Docker Compose удаляет последний контейнер внутри сети, он также удаляет и эту сеть.
Добавление контейнеров во внешнюю сеть
Другой способ определения сети — это внешний (если смотреть с точки зрения Docker Compose).
Мы можем использовать команду docker network для создания новой сети, а затем сказать Compose, что некоторые контейнеры должны принадлежать ей.
|
1
|
docker network create backend |
Поскольку переменная DOCKER_HOST прежнему указывает на IP и порт мастера Swarm , вновь созданная сеть охватывает все серверы кластера.
Мы можем подтвердить, что backend сеть действительно была создана, выполнив следующую команду.
|
1
|
docker network ls |
Вывод команды network должен быть аналогичен следующему.
|
1
2
3
4
5
6
7
8
|
NETWORK ID NAME DRIVERcd2675aa63cf backend overlay2f77d6dd68f7 swarm-node-1/bridge bridgece249d5e9344 swarm-node-1/host hostf65bb111c121 swarm-node-1/none null59b0f8b1f82a swarm-node-2/bridge bridge021455cd81ae swarm-node-2/host hostbd944b062d59 swarm-node-2/none null |
Как видите, кроме сетей, созданных во время настройки Swarm, также доступен бэкэнд . Мы можем использовать его через Compose или выполнив команду docker run с аргументом --net . Содержимое файла docker-compose.yml выглядит следующим образом.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
version: '2'networks: be: external: name: backendservices: app: image: vfarcic/books-ms${BOOKS_MS_VERSION} ports: - 8080 environment: - SERVICE_NAME=books-ms - DB_HOST=books-ms-db networks: default: {} be: aliases: - books-ms depends_on: - db db: container_name: books-ms-db image: mongo environment: - SERVICE_NAME=books-ms-db |
Этот файл Compose почти такой же, как тот, который мы использовали ранее. Разница лишь в добавлении разделов networks .
Мы не будем вдаваться в подробности всего определения, а сосредоточимся на networks . Первый раздел networks (вверху) внутренне называется be . Он установлен как external и относится к сетевому backend . Внутреннее имя — это ссылка, которую мы будем использовать внутри сервисов. Если сеть external , это означает, что ее необходимо создать вручную вне Docker Compose . Мы уже сделали это, выполнив команду docker network create backend . Наконец, имя сети должно совпадать с именем, которое мы указали в команде.
Раздел networks представляет общее определение сети. Само по себе оно не имеет цели, пока не будет определено внутри сервисов. Следовательно, у нас есть сеть, указанная внутри службы app . Мы рассмотрим aliases чуть позже.
Мы начнем с вызова двух экземпляров целевого app и, вместе с ними, db они зависят.
|
1
2
3
|
docker-compose up -d appdocker-compose scale app=2 |
Как и раньше, Docker Compose создал сеть для всех контейнеров, определенных в файле docker-compose.yml . Однако мы указали, что цель приложения должна также принадлежать внутренней сети. В результате у нас есть контейнеры dns_app_1 и dns_app_2, принадлежащие обоим, и books-ms-db, находящиеся только внутри сети dns_default . Это само по себе не дает ничего нового. Все три контейнера могут «общаться» друг с другом с или без внутренней сети.
Давайте посмотрим, что произойдет, если мы запустим новый контейнер, но на этот раз используем аргумент --net чтобы указать, что он должен принадлежать бэкэнд- сети.
|
1
2
3
|
docker run -it --rm --net backend alpine ping -c 1 dns_app_1docker run -it --rm --net backend alpine ping -c 1 books-ms-db |
Вывод двух команд выглядит следующим образом.
|
1
2
3
|
PING dns_app_1 (10.0.0.2): 56 data bytesping: bad address 'books-ms-db' |
Поскольку dns_app_1 принадлежит к той же сети, проверка связи прошла успешно. С другой стороны, второй эхо-запрос не прошел, поскольку контейнер books-ms-db не принадлежит бэкэнду внешней сети.
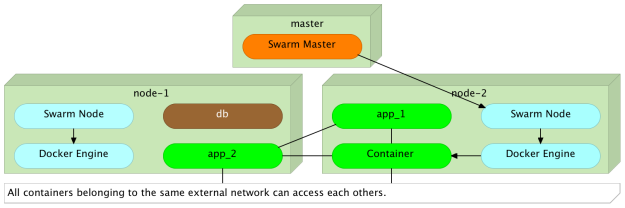
Все контейнеры, принадлежащие одной внешней сети, могут иметь доступ друг к другу.
Мы хотим отправить запросы конкретному экземпляру цели (например, dns_app_1 )?
Запросы балансировки нагрузки для нескольких экземпляров
Отправка запросов конкретному экземпляру цели не соответствует цели масштабирования. Мы масштабируемся, потому что хотим повысить производительность и обеспечить аварийное переключение на случай, если один из экземпляров перестанет работать. Поэтому мы хотим, чтобы запросы были сбалансированы по нагрузке между всеми экземплярами цели. Мы можем сделать это легко с балансировкой нагрузки DNS и псевдонимами .
Если вы вернетесь к файлу docker-compose.yml, который мы использовали ранее, вы заметите, что внутренняя сеть, определенная внутри цели приложения, имеет псевдоним book-ms . Посылая запрос псевдониму вместо определенного имени контейнера, Docker выполнит циклическое распределение нагрузки и перенаправит его в один из экземпляров.
Чтобы проверить это, мы отправим три псевдонима псевдоним books-ms .
|
1
2
3
4
5
|
docker run -it --rm --net backend alpine ping -c 1 books-msdocker run -it --rm --net backend alpine ping -c 1 books-msdocker run -it --rm --net backend alpine ping -c 1 books-ms |
Комбинированный вывод команд выглядит следующим образом.
|
1
2
3
4
5
|
PING books-ms (10.0.1.3): 56 data bytesPING books-ms (10.0.1.3): 56 data bytesPING books-ms (10.0.1.2): 56 data bytes |
Первые два запроса были отправлены экземпляру с IP- адресом 10.0.1.3, а третий был отправлен на 10.0.1.2 . Псевдоним Docker упрощает связь между различными сервисами. Выбор, какой экземпляр запроса должен быть перенаправлен, может быть перемещен за пределы службы, отправляющей запрос. Все, что сервис должен знать, это то, что сервис назначения доступен через псевдоним books-ms . Докер позаботится о том, чтобы он достиг одного из экземпляров этой службы. Если в вашем случае результат мог быть другим. Не отчаивайся. Объяснение придет чуть позже.
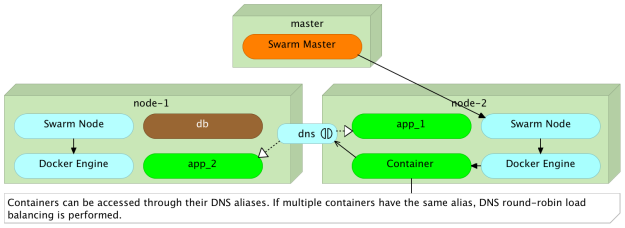
Балансировка нагрузки DNS через псевдонимы
Варианты использования сети
При работе с Docker и SDN (Software Defined Networking) появляются некоторые шаблоны, и мы можем наблюдать различные варианты использования.
Сети, созданные автоматически Docker Compose, следует использовать для внутренней связи между контейнерами, которые образуют один и тот же проект или одну и ту же службу. Это полезно, потому что эти контейнеры должны иметь возможность «говорить» друг с другом. В нашем примере цель приложения сохраняет и извлекает данные из базы данных, работающей в отдельном контейнере. Никто за пределами этой сети не может получить доступ к этим контейнерам. Мы можем назвать этот тип внутренней связью .
С другой стороны, цель приложения предоставляет HTTP API. Нам нужны другие сервисы, чтобы иметь возможность вызывать его. По этой причине мы создали вторую (внешнюю) сеть, которая называется backend . Поскольку другие службы не должны обращаться к базам данных друг друга, они исключаются из сети. Другими словами, связь между различными сервисами доступна только через их API. Мы можем назвать этот тип внешней связью .
Предоставление публичного доступа к услугам
Те, кто обратил внимание, заметят, что мы не упомянули третий случай. Мы не исследовали способы доступа к службам вне кластера. В конце концов, в большинстве случаев мы хотим, чтобы наши услуги были общедоступными. Мы хотим, чтобы наши пользователи могли их использовать. Причина этого упущения заключается в необходимости использовать различные инструменты для этого типа доступа. Хотя технически возможно и относительно легко реализовать этот вариант использования с балансировкой нагрузки Docker DNS, решение будет неоптимальным.
Прокси-сервисы, такие как HAProxy и nginx, являются проверенными в бою решениями для балансировки нагрузки, обратного прокси-сервера и некоторых других вещей. Широкомасштабный доступ к масштабируемым сервисам с потенциально огромной нагрузкой может быть не лучшим образом реализован с использованием методов, которые мы исследовали С другой стороны, для непрерывного развертывания, поддерживаемого контейнерами, требуется постоянная реконфигурация этих служб вместе с обнаружением служб, которые будут предоставлять необходимую информацию о кластере и всем, что работает внутри него. Динамическая реконфигурация прокси-сервера и обнаружение служб выходят за рамки данной статьи, и существует множество инструментов, которые позволят вам создать собственное решение. Мы будем использовать один из них только в качестве примера результата, который мы хотим достичь с помощью прокси.
Поскольку у нас пока нет прокси-сервера, служба, с которой мы экспериментировали, в настоящее время недоступна из общедоступной сети. Мы можем подтвердить это, отправив запрос HTTP.
|
1
|
curl -I proxy/api/v1/books |
Вывод команды curl выглядит следующим образом.
|
1
2
3
4
|
HTTP/1.0 503 Service UnavailableCache-Control: no-cacheConnection: closeContent-Type: text/html |
Как и ожидалось, мы получили ответ 503 Service Unavailable .
Мы можем легко изменить это, запустив прокси-сервер и настроив его для балансировки нагрузки между двумя экземплярами службы. Мы запустим контейнер vfarcic / docker-flow-proxy, определенный в файле docker-compose-proxy.yml . Определение следующее.
|
01
02
03
04
05
06
07
08
09
10
11
12
|
version: '2'services: proxy: container_name: docker-flow-proxy image: vfarcic/docker-flow-proxy environment: CONSUL_ADDRESS: 10.100.198.200:8500 ports: - 80:80 - 443:443 - 8080:8080 |
Часть процесса, который создал виртуальные машины, заключалась в том, чтобы запустить прокси-сервер, поэтому все, что нам нужно сделать, — это перенастроить его для загрузки запросов баланса в службу books-ms .
|
1
|
curl "proxy:8080/v1/docker-flow-proxy/reconfigure?serviceName=books-ms&servicePath=/api/v1/books" |
Теперь, когда прокси настроен, мы можем использовать его как ретранслятор для нашего сервиса.
|
1
|
curl -I proxy/api/v1/books |
Этот вывод команды curl выглядит следующим образом.
|
1
2
3
4
5
6
|
HTTP/1.1 200 OKServer: spray-can/1.3.1Date: Sat, 23 Apr 2016 17:47:20 GMTAccess-Control-Allow-Origin: *Content-Type: application/json; charset=UTF-8Content-Length: 2 |
На этот раз ответ — 200 OK, что означает, что услуга действительно доступна через прокси.
В результате объединения прокси с сетями Docker и DNS мы решили обеспечить общий доступ к службам, распределение нагрузки и внутреннюю связь между контейнерами.
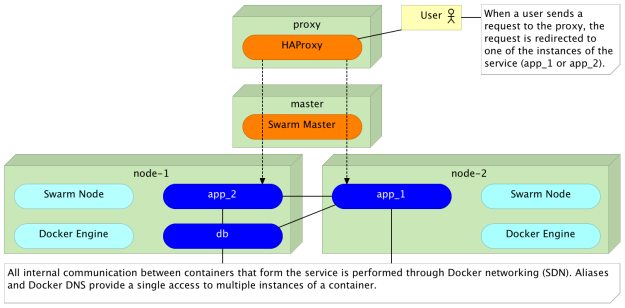
Прокси в сочетании с сетью Docker и DSN
Если вас интересуют более подробные сведения о используемом нами прокси-сервере, прочтите статью Docker Flow: Proxy — По требованию HAProxy Service Discovery и Reconfiguration или перейдите непосредственно к проекту Docker Flow: Proxy .
Хороший, плохой, злой
Давайте быстро оценим методы и технологии, которые мы изучили в этой статье.
Хорошая (перенимать сейчас)
Сеть Docker существует для нескольких версий, и она стабильна. Эксплуатация контейнеров внутри кластера была болезненной и сложной без нее. Ссылки не могут охватывать несколько контейнеров без использования обходных путей, уловок и «колдовства». Это был главный этап, который сделал Swarm жизнеспособным и, во многих случаях, лучшим решением для запуска контейнеров внутри кластера.
DNS round robin очень прост в определении и использовании. Большое спасибо Docker за эту функцию. Здорово, когда нам нужно разрешить внутреннюю связь между  разные контейнеры. Без этого Docker-сеть действительно полезна только при наличии единственного экземпляра службы назначения. С DNS мы можем начать размышлять об использовании Docker SDN в более широком масштабе.
разные контейнеры. Без этого Docker-сеть действительно полезна только при наличии единственного экземпляра службы назначения. С DNS мы можем начать размышлять об использовании Docker SDN в более широком масштабе.
Плохое (потенциально полезное, но все еще в зачаточном состоянии)
Хотя распознаватель DNS в Engine 1.11 будет рандомизировать записи (т.е. возвращать их в различном порядке при каждом запросе), большинство распознавателей DNS будет сортировать записи. В результате циклический перебор не будет работать должным образом. Вы видели пример, когда мы сделали три эхо-запроса через DNS к целевому приложению назначения. Даже если никто не обращался к сервису, первые два запроса были переданы первому экземпляру, а третий — второму (в вашем случае порядок мог быть другим). Истинный циклический перебор сделал бы первый запрос к первому экземпляру, второй запрос ко второму экземпляру и третий запрос к первому экземпляру снова. Проблема не в реализации Docker, а в самом DNS. Хотя во многих случаях это отклонение не должно вызывать проблем, все же существуют более эффективные решения, которые мы можем применить. С другой стороны, это дополнение является очень важной вехой, и нам еще предстоит увидеть улучшения, которые принесут следующие выпуски.
Уродливый (не используйте его)
DNS докера в сочетании с псевдонимами имеет много применений, но публичная балансировка нагрузки большого трафика не входит в их число. Не поддавайтесь искушению заменить ваш прокси на него. HAProxy и nginx, и это лишь некоторые из них, прошли боевые испытания и доказали свою эффективность практически при любой нагрузке. Благодаря проверкам работоспособности, обратному прокси-серверу, перезаписи URL-адресов и многим другим функциям они намного больше, чем простые балансировщики нагрузки. Сложность при использовании прокси-серверов заключается в динамической реконфигурации, основанной на обнаружении службы, но это не уменьшает их ценность и не оправдывает переход на DNS-докер. С другой стороны, прокси не уменьшают значение, которое мы получили в выпуске 1.11. Это еще один инструмент в наборе инструментов, и наша работа — знать, когда использовать один поверх другого. Пожалуйста, прочитайте Docker Flow: Proxy — Обнаружение и изменение конфигурации службы HAProxy по требованию для получения дополнительной информации. Даже если вы не решите использовать Docker Flow: Proxy , он дает представление о том, что мы ожидаем от прокси внутри кластера, заполненного контейнерами.
 Если вам понравилась эта статья, вас может заинтересовать книга Среди многих других тем более подробно рассматривается кластеризация и работа в сети Docker.
Если вам понравилась эта статья, вас может заинтересовать книга Среди многих других тем более подробно рассматривается кластеризация и работа в сети Docker.
Книга посвящена различным методам, которые помогают нам лучше и эффективнее разрабатывать программное обеспечение с помощью микросервисов, упакованных в неизменяемые контейнеры , тестируемых и постоянно развертываемых на серверах, которые автоматически снабжаются инструментами управления конфигурацией . Это быстрое, надежное и непрерывное развертывание с нулевым временем простоя и возможностью отката . Речь идет о масштабировании до любого количества серверов, разработке самовосстанавливающихся систем, способных к восстановлению после сбоев оборудования и программного обеспечения, а также о централизованном ведении журналов и мониторинге кластера.
Другими словами, эта книга охватывает весь жизненный цикл разработки и развертывания микросервисов с использованием самых последних и лучших практик и инструментов. Мы будем использовать Docker, Ansible, Ubuntu, Docker Swarm и Docker Compose, Consul, etcd, Registrator, confd, Jenkins, nginx и так далее. Мы пройдем через множество практик и даже больше инструментов.
Книга доступна от Amazon ( Amazon.com и других сайтов по всему миру) и LeanPub .
| Ссылка: | Сеть Docker и DNS: «Хорошо, плохо и безобразно» от нашего партнера по JCG Виктора Фарчича в блоге « Технологии» . |