Цель этого поста — показать, насколько мощным и гибким может быть Docker Swarm в сочетании со стандартными инструментами UNIX для распределенного анализа данных. Для этого напишем простую реализацию MapReduce в bash/sh которая использует Docker Swarm для планирования заданий Map на узлах в кластере.
MapReduce обычно реализуется, когда для обработки требуется большой набор данных. Для простоты и воспроизводимости читателем мы используем очень маленький набор данных, состоящий из нескольких мегабайт текстовых файлов.
Этот пост не о том, как написать программу MapReduce. Это также не значит, что MapReduce лучше всего делать таким образом. Вместо этого эта статья рассказывает о том, что простые старые инструменты UNIX, такие как sort , awk , netcat , pv , uniq , xargs , pipe , join , time и cat могут быть полезны для распределенной обработки данных при запуске поверх Докер Рой кластер.
Поскольку это только пример, предстоит проделать большую работу, чтобы добиться отказоустойчивости, устойчивости и избыточности. Такое решение, как предложенное здесь, может быть полезно, если у вас есть случай одноразового использования, и вы не хотите тратить время на что-то более сложное, например Hadoop . Если у вас есть частые случаи использования, я рекомендую вам использовать Hadoop.
Требования к нашей реализации MapReduce с Docker Swarm
Чтобы воспроизвести примеры в этом посте, вам понадобится несколько вещей:
- Docker установлен на вашем локальном компьютере
- Работающий кластер Swarm (если у вас его нет, не волнуйтесь. Я объясню, как получить его для этой цели быстро и легко)
- Docker Machine установлен на вашем локальном компьютере (для настройки кластера Swarm, если у вас его еще нет)
MapReduce — это парадигма программирования с целью распределенной обработки больших наборов данных в кластере (в нашем случае кластер Swarm). Как следует из названия, MapReduce состоит из двух основных этапов:
- Карта: мастер-узел берет большой набор данных и распределяет его для вычисления узлов для выполнения анализа. Каждый узел возвращает результат.
- Сократить: собрать результаты каждой карты и объединить их, чтобы получить окончательный ответ.
Настройка кластера Swarm
Если у вас уже есть кластер Swarm, вы можете пропустить этот раздел. Просто убедитесь, что вы подключаетесь к кластеру Swarm при использовании клиента Docker. Для этого вы можете проверить переменную окружения
DOCKER_HOST.
Я написал скрипт установки, чтобы мы могли легко создать кластер Swarm на DigitalOcean. Чтобы использовать его, вам нужна учетная запись DigitalOcean и ключ API, чтобы позволить Docker Machine управлять вашими экземплярами. Вы можете получить ключ API здесь .
Когда вы закончите с ключом API, экспортируйте его, чтобы его можно было использовать в скрипте установки:
|
1
|
export DO_ACCESS_TOKEN=aa9399a2175a93b17b1c86c807e08d3fc4b79876545432a629602f61cf6ccd6b |
Теперь мы готовы написать скрипт create-cluster.sh :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
#!/bin/bash# configurationagents="agent1 agent2"token=$(docker run --rm swarm create)# Swarm manager machineecho "Create swarm manager"docker-machine create \ -d digitalocean \ --digitalocean-access-token=$DO_ACCESS_TOKEN \ --swarm --swarm-master \ --swarm-discovery token://$token \ manager# Swarm agentsfor agent in $agents; do ( echo "Creating ${agent}" docker-machine create \ -d digitalocean \ --digitalocean-access-token=$DO_ACCESS_TOKEN \ --swarm \ --swarm-discovery token://$token \ $agent ) &donewait# Informationecho ""echo "CLUSTER INFORMATION"echo "discovery token: ${token}"echo "Environment variables to connect trough docker cli"docker-machine env --swarm manager |
Как вы можете заметить, этот скрипт состоит из трех частей:
- конфигурация: здесь у вас есть две переменные, используемые для настройки всего кластера. Переменная
agentsопределяет, сколько агентов Swarm нужно поместить в кластер, когда переменнаяtokenзаполняется командойswarm createкоторая генерирует токен Docker Hub, используемый вашим кластером для обнаружения службы. Если вам не нравится использование токенов, вы можете использовать свой собственный сервис обнаружения, такой как Consul, ZooKeeper или Etcd . - Создание главной машины Swarm: эта машина будет предоставлять удаленный API Docker через tcp.
- Создание машин-агентов Swarm. В соответствии с конфигурацией, в DigitalOcean для каждого указанного имени
agent1 agent2будет созданagent1 agent2настроенный для присоединения к кластеру ранее созданного менеджера Swarm. - Распечатать информацию о сгенерированном кластере: когда машины работают, скрипт просто печатает информацию о сгенерированном кластере и о том, как подключиться к нему с помощью Docker-клиента.
Теперь мы можем наконец выполнить скрипт create-cluster.sh :
|
1
2
|
chmod +x create_cluster.sh./create_cluster.sh |
Через несколько минут и несколько строк вывода, и если ничего не пошло не так, мы должны увидеть что-то вроде этого:
|
1
2
3
4
5
6
7
8
9
|
CLUSTER INFORMATIONdiscovery token: 9effe6d53fdec36e6237459313bf2eaaEnvironment variables to connect trough docker cliexport DOCKER_TLS_VERIFY="1"export DOCKER_HOST="tcp://104.236.46.188:3376"export DOCKER_CERT_PATH="/home/fntlnz/.docker/machine/machines/manager"export DOCKER_MACHINE_NAME="manager"# Run this command to configure your shell: # eval $(docker-machine env --swarm manager) |
Как и предполагалось, вам нужно выполнить команду для настройки вашей оболочки, чтобы подключиться к демону Docker кластера Swarm.
|
1
|
eval $(docker-machine env --swarm manager) |
Чтобы убедиться, что кластер запущен и работает, вы можете использовать:
|
1
|
docker-machine ls |
который должен напечатать:
|
1
2
3
4
|
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORSagent1 - digitalocean Running tcp://104.236.26.148:2376 manager v1.10.3 agent2 - digitalocean Running tcp://104.236.21.118:2376 manager v1.10.3 manager * (swarm) digitalocean Running tcp://104.236.46.188:2376 manager (master) v1.10.3 |
Обратите внимание, что в столбце ACTIVE есть только один ACTIVE master. Это потому, что вы выполнили эту команду eval для настройки вашей оболочки ранее.
Сбор данных для анализа
Анализ данных был бы ничем без данных для анализа. Мы собираемся использовать несколько стенограмм последних сезонов популярного британского научно-фантастического сериала « Доктор Кто» . Для этой цели я создал Gist, некоторые из которых взяты из The Doctor Who Transcripts .
На самом деле я добавил в «Гист» только самые последние эпизоды «Девятого доктора» (начиная с 2005 года). Вы можете получить стенограммы, клонируя мой Gist:
|
1
|
git clone https://gist.github.com/fa9ed1ad11ba09bd87b2d25a14f65636.git who-transcripts |
После того, как вы клонировали Gist, у вас должна получиться папка who-transcripts содержащая 130 стенограмм.
Поскольку одним из наших требований для этого поста является то, что анализ данных должен выполняться с помощью инструментов UNIX, мы можем использовать AWK для программы карты.
Для того, чтобы быть полезным для шага сокращения, наша картографическая программа должна иметь возможность преобразовывать расшифровку следующим образом:
|
1
2
3
4
5
6
7
8
9
|
[Albion hospital](The patients are almost within touching distance.) DOCTOR: Go to your room. (The patients in the ward and the child in the house stand still.) DOCTOR: Go to your room. I mean it. I'm very, very angry with you. I am very, very cross. Go to your room! (The child and the patients hang their heads in shame and shuffle away. The child leaves the Lloyd's house and the patients get back into bed.) DOCTOR: I'm really glad that worked. Those would have been terrible last words.[The Lloyd's dining room] |
В ключе значение пары выглядит так:
|
1
2
3
4
5
6
7
8
|
DOCTOR goDOCTOR toDOCTOR yourDOCTOR roomDOCTOR ImDOCTOR reallyDOCTOR glad... |
Для этого Map должна пропустить строки, которые не в формате <speaker>: <phrase> , а затем для каждого слова она должна напечатать имя говорящего и само слово.
Для этого мы можем написать простую программу на AWK например map.awk :
|
01
02
03
04
05
06
07
08
09
10
11
12
|
#!/usr/bin/awk -f{ if ($0 ~ /^(\w+)(.\[\w+\])?:/) { split ($0, line, ":"); character=line[1]; phrase=tolower(gensub(/[^a-zA-Z0-9 ]/, "", "g", line[2])); count=split(phrase, words, " "); for (i = 0; ++i <= count;) { print character " " words[i] } }} |
На вашем локальном компьютере вы можете легко попробовать программу карты с:
|
1
|
cat who-transcripts/27-1.txt | ./map.awk |
Планирование заданий на карте
Теперь, когда у нас есть программа Map, мы можем подумать о том, как начать планирование заданий карты в нашем кластере. Наш планировщик будет отвечать за:
- Управление количеством заданий одновременно
- Копирование картографической программы в исполнителей
- Указание исполнителю запускать картографические программы
- Копирование данных исполнителям
- Запуск программы карты и объединение результатов каждого отдельного исполнителя с другими
- Контейнеры для сбора мусора больше не нужны
Для этого мы можем написать сценарий bash, который читает все стенограммы из папки who-transcripts . Он также будет использовать Docker-клиент для подключения к Swarm-кластеру и делать всю магию!
Сценарий, подобный приведенному ниже, может решить эту важную задачу:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
#!/bin/bashfunction usage { echo "USAGE: " echo " ./scheduler.sh <transcripts folder> <max concurrent jobs>"}# Argument checkingtranscripts_folder=$1if [ -z "$1" ]; then echo "Please provide a folder from which take transcripts" echo "" usage exit 1fiif [ ! -d "$transcripts_folder" ]; then echo "Please provide a valid folder from which take transcripts" echo "" usage exit 1fimaxprocs=$2if [ -z "$2" ]; then maxprocs=5fi# Schedulingproc=0seed=`uuidgen`# Cycle trough transcripts and start jobsfor transcript in $transcripts_folder/*; do (container=`docker run --name "${seed}.$proc" -d alpine sh -c "while true; do sleep 5; done"` > /dev/null echo "[MAP] transcript: ${transcript} => container: ${container}" docker cp map.awk $container:/map cat $transcript | docker exec -i $container ./map >> result.txt docker rm -f $container > /dev/null) & (( proc++%maxprocs==0 )) && wait;done# Remove containersdocker ps -aq --filter "name=$1" | xargs docker rm -f |
Сценарий состоит из трех важных частей:
- Проверка аргументов . Единственная цель этой части — получить и проверить необходимые аргументы для выполнения заданий.
- Выполнение заданий : эта часть состоит из цикла
forкоторый выполняет итерацию по всем текстовым файлам в предоставленной папке. На каждой итерации запускается контейнер, и сценарийmap.awkкопируется в него непосредственно перед выполнением. Выходные данные сопоставления перенаправляются в файлresult.txtкоторый собирает все выходные данные сопоставления. Циклforуправляется переменнойmaxprocsкоторая определяет максимальное количество одновременных заданий. - Удаление контейнеров : Использованные контейнеры должны быть удалены во время цикла
for; если этого не происходит, они удаляются после окончания цикла.
Сценарий планировщика можно упростить, запустив контейнер с параметром -rm , но для этого потребуется, чтобы скрипт map.awk уже находился внутри изображения перед запуском.
Поскольку планировщик способен передавать необходимые данные исполнителям, нам больше ничего не нужно, и мы можем запустить планировщик. Но перед запуском планировщика мы должны указать клиенту Docker подключиться к кластеру Swarm, а не к локальному движку.
|
1
|
eval $(docker-machine env --swarm manager) |
Это запустит планировщик, используя папку who-transcripts с 40 как максимальное количество одновременных заданий.
|
1
|
./scheduler.sh who-transcripts 40 |
При выполнении планировщик должен вывести что-то похожее:
|
1
2
3
4
5
6
7
|
[MAP] transcript: who-transcripts/27-10.txt => container: f1b4bdf37b327d6d3c288cc1e6ce1b7f274b3712bc54e4315d24a9524801b230[MAP] transcript: who-transcripts/27-12.txt => container: 03e18bf08f923c0b52121a61f1871761bf516fe5bc53140da7fa08a9bcb9294c[MAP] transcript: who-transcripts/27-11.txt => container: dadfb0e2cccf737198e354d2468bdf3eb8419ec131ed8a3852eca53f1e57314b[MAP] transcript: who-transcripts/27-2.txt => container: 69bb0eb07df7a356d10add9d466f7d6e2c8b7ed246ed9922dc938c0f7b4ee238[MAP] transcript: who-transcripts/28-1.txt => container: 3f56522aac45fd76f88a190611fb6e3f96f4a65e79e8862f7817be104f648737[MAP] transcript: who-transcripts/28-6.txt => container: 05048e807996b63231c59942a23f8504eab39ece32e616644ccef2de7cb01d5c[MAP] transcript: who-transcripts/28-0.txt => container: a0199b5d64ca012e411da09d85081a604f87500f01e193395828e7911f045075 |
Когда планировщик завершит работу, мы можем проверить файл result.txt . Вот первые 20 строк:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
DOCTOR goDOCTOR toDOCTOR yourDOCTOR roomDOCTOR goDOCTOR toDOCTOR yourDOCTOR roomDOCTOR iDOCTOR meanMICKEY itROSE imDOCTOR veryDOCTOR veryDOCTOR angryDOCTOR withMICKEY youDOCTOR iDOCTOR amROSE very |
Большой! Это ключ, значение <name> <sentence> . Итак, давайте посмотрим, сможем ли мы уменьшить эти данные до чего-то полезного с этими данными с помощью команды UNIX:
|
1
|
cat result.txt | sort | uniq -c | sort -fr |
Приведенная выше команда сокращения сортирует файл, фильтрует уникальные строки, а затем снова сортирует их в обратном порядке, так что наиболее распространенные слова по динамику отображаются первыми. Выходные данные первых 20 строк этой команды:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
9271 DOCTOR the 7728 DOCTOR you 5290 DOCTOR a 5219 DOCTOR i 4928 DOCTOR to 3959 DOCTOR it 3501 DOCTOR and 3476 DOCTOR of 2595 DOCTOR that 2457 DOCTOR in 2316 DOCTOR no 2309 DOCTOR its 2235 DOCTOR is 2150 DOCTOR what 2088 DOCTOR this 2009 DOCTOR me 1865 DOCTOR on 1681 DOCTOR not 1580 DOCTOR just 1531 DOCTOR im |
Это означает, что самое распространенное слово, сказанное Доктором, — the . Вот график распределения 50 наиболее часто используемых слов:
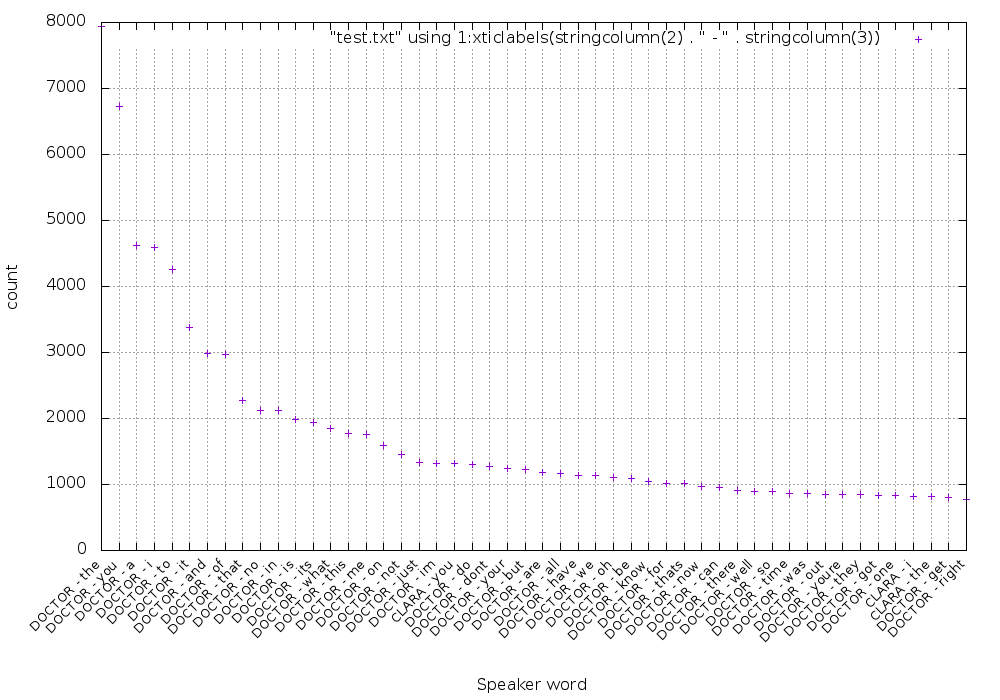
Если вам интересно, я сгенерировал этот график, используя скрипт gnuplot:
|
01
02
03
04
05
06
07
08
09
10
11
|
resetset term png truecolor size 1000,700set output "dist.png"set xlabel "Speaker word"set ylabel "count"set gridset boxwidth 0.95 relativeset style fill transparent solid 0.5 noborderset xtics rotate by 45 rightset xtics font ", 10"plot "result.txt" using 1:xticlabels(stringcolumn(2) . " - " . stringcolumn(3)) |
Давайте попробуем что-то более осмысленное — давайте посмотрим, как часто слово « tardis » было сказано:
|
1
|
cat result.txt | sort | uniq -c | sort -fr | grep 'tardis' |
Как и ожидалось, это показывает, что Доктор — это тот, кто больше всего говорит о «ТАРДИС»:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
335 DOCTOR tardis 43 CLARA tardis 22 ROSE tardis 22 AMY tardis 18 RIVER tardis 16 RORY tardis 10 DOCTOR [OC] tardis 9 MICKEY tardis 8 MARTHA tardis 6 IDRIS tardis 6 DOCTOR tardises 5 JACK tardis 5 DONNA tardis 4 MASTER tardis 4 DALEK tardis 3 TASHA tardis 3 MARTHA [OC] tardis 3 KATE tardis 3 DOCTOR [memory] tardis 2 RIVER [OC] tardis 2 MOMENT tardis 2 MISSY tardis 2 DALEKS [OC] tardis 1 YVONNE tardis 1 WHITE tardis 1 VICTORIA tardis 1 VASTRA tardis 1 UNCLE tardises 1 SUSAN [OC] tardis 1 SEC tardis 1 SARAH tardis 1 ROSITA tardis 1 RORY [OC] tardis 1 ROBIN tardis 1 OSGOOD tardis 1 MOTHER tardis 1 MACE tardis 1 LAKE tardis 1 KATE tardisproofed 1 K9 tardis 1 JENNY tardis 1 JACKIE tardis 1 IDRIS tardises 1 HOWIE tardis 1 HOUSE [OC] tardises 1 HOUSE [OC] tardis 1 HANDLES tardis 1 GREGOR tardis 1 FABIAN tardis 1 EDITOR tardis 1 DOCTOR tardisll 1 DAVROS tardis 1 DANNY tardis 1 DALEK [OC] tardis 1 CRAIG tardis 1 CLARK tardis 1 CLARA [OC] tardis 1 BORS tardis 1 BOB [OC] tardis 1 BLUE tardis 1 AUNTIE tardis 1 ASHILDR tardis |
Вывод
Docker Swarm — очень гибкий инструмент, и философия UNIX как никогда актуальна при выполнении анализа данных. Здесь мы показали, как простая задача может быть распределена по кластеру путем смешивания Swarm с несколькими командами — возможное развитие этого подхода — использование более понятного подхода.
Несколько возможных улучшений могут быть:
- Используйте настоящий язык программирования вместо скриптов AWK и Bash.
- Создайте и вставьте образ Docker, показывающий все необходимые программы (вместо копирования их в Alpine при запуске Docker).
- Поместите данные ближе к месту их обработки (в этом примере мы загрузили данные в кластер во время выполнения с помощью планировщика).
- И последнее, но не менее важное: имейте в виду, что если у вас начнутся частые и более сложные случаи использования, Hadoop станет вашим другом.
| Ссылка: | Анализ распределенных данных с помощью Docker Swarm от нашего партнера по JCG Лоренцо Фонтана в блоге Codeship Blog . |