Почему ВИМ?
Рано или поздно наступает день, когда ваша простая в использовании IDE становится бесполезной для обработки больших файлов. Существует не так много редакторов, способных работать с очень большими файлами, например, с производственными журналами.
Недавно мне пришлось проанализировать однострочный файл JSON размером 100 МБ, и VIM еще раз спас день. VIM, как и многие другие утилиты Unix, является одновременно жестким и блестящим. Интерактивная перебазировка Git требует, чтобы вы знали это, и если вы все еще не уверены, возможно, эта замечательная статья заставит вас передумать.
Давайте посмотрим, как легко вы можете распечатать JSON-файл с помощью VIM. Сначала мы загрузим однострочный файл JSON из Reddit.
|
01
02
03
04
05
06
07
08
09
10
11
|
$ wget http://www.reddit.com/r/programming.json--2014-01-24 12:21:04-- http://www.reddit.com/r/programming.jsonResolving www.reddit.com (www.reddit.com)... 77.232.217.122, 77.232.217.113Connecting to www.reddit.com (www.reddit.com)|77.232.217.122|:80... connected.HTTP request sent, awaiting response... 200 OKLength: 28733 (28K) [application/json]Saving to: `programming.json'100%[======================================>] 28,733 --.-K/s in 0.03s2014-01-24 12:21:04 (1021 KB/s) - `programming.json' saved [28733/28733] |
Вот как это выглядит:
Красивая печать
Python поставляется вместе с большинством дистрибутивов Unix, поэтому выполнение следующей команды VIM позволяет добиться цели:
|
1
|
%!python -m json.tool |
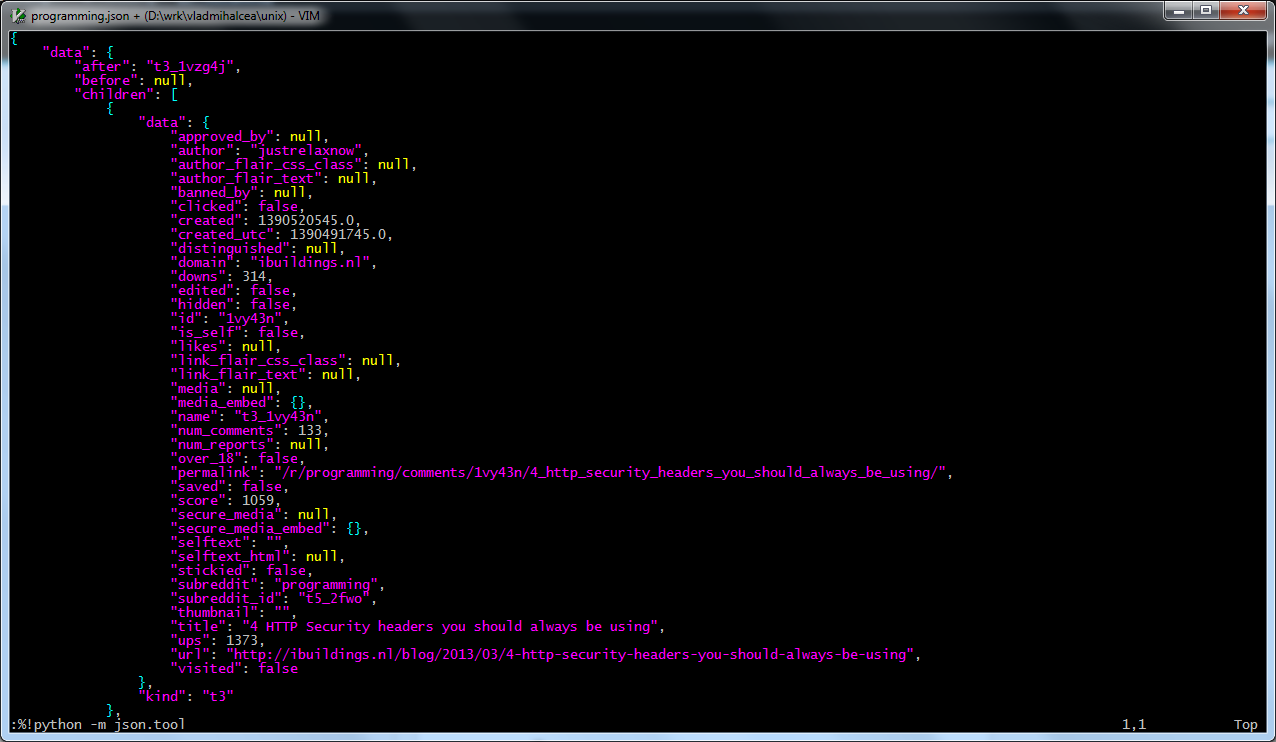
Давайте сохраним распечатанный файл JSON и применим другие инструменты Unix.
|
1
|
:w programming_pretty.json |
Время совпадения
Допустим, мы хотим извлечь все значения, относящиеся к домену:
|
1
|
"domain": "mameworld.info" |
Sed на помощь
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
$ sed -nr 's/^.*"domain":\s*"(.*?)".*$/\1/p' <programming_pretty.json | sort -ublog.safaribooksonline.comchadfowler.comcyrille.rossant.netdot.kde.orgevanmiller.orgfabiensanglard.netgalileo.phys.virginia.edugithub.comhalffull.orgibuildings.nljaxenter.comjobtipsforgeeks.comkilncode.comlibtins.github.iomameworld.infomiguelcamba.comminuum.comnotes.tweakblogs.netperfect-pentago.netperiscope.ioreuters.comtech.blog.box.comtmm1.netvocalbit.comyoutube.com |
Многострочное сопоставление
Sed ориентирован на строки, и хотя он предлагает поддержку нескольких строк, он не подходит для Perl. Допустим, я хочу сопоставить всех авторов в следующем шаблоне JSON:
|
1
2
3
|
"data": { "author": "justrelaxnow", } |
Вот как я это делаю:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
$ perl -0777 -n -e 'print "$2\n" while (m/("data":\s*\{.*?"author":\s*"(.*?)"[,|\s*\}].*?\},)/sgmp)' programming_pretty.json | sort -uAmericanXer0azthbionicseraphbit_shiftrcharles_the_hardGexosjakubgarfieldjohnwaterwoodjoukoojustrelaxnowKingvashkretsmariuzmopatchesnyphrexpseudomindrluecke3sltkrsolidus-fluxsteveklabnik1sumstozeroswizecvocalbitWolfspaw |
Вывод
Инструменты Unix — это старая школа, некоторые из которых написаны сорок лет назад. Кривая обучения может быть крутой, но изучение их — большая инвестиция. Отличная библиотека программного обеспечения выдерживает испытание временем, а инструменты Unix являются хорошим напоминанием о том, что тяжелые работы требуют сложных инструментов.