Распространенный сценарий интеграции — это когда одно сообщение необходимо отправить несколькими маршрутами.
Возьмем, к примеру, случай, когда вы получаете сообщение о регистрации нового клиента. Сообщение должно быть направлено через CRM для создания клиента, маркетингу, который захочет узнать, как клиент узнал о компании, и, наконец, перейти к системам обеспечения и хранения, чтобы они могли творить свое волшебство.
В этом случае сообщение передается в режиме «запусти и забудь», что означает, что вам не требуется ответ от любой из этих систем для продолжения обработки. Каждая из этих систем отвечает за обработку своей собственной логики и собственных ошибок. В Mule ESB вы можете сделать это следующим образом:
<async> <flow-ref name="crmSystemRoute" /> <flow-ref name="marketingSystemRoute" /> <flow-ref name="provisioningSystemRoute" /> <flow-ref name="stockSystemRoute" /> </async>
Есть и другие случаи, в которых вы делаете нужен ответ от маршрутов. Предположим, вы используете приложение для бронирования билетов, и кто-то хочет получить прямой рейс из Буэнос-Айреса в Сан-Франциско. Ваше приложение должно связаться со всеми известными брокерами авиакомпании, получить доступ к этим рейсам и выбрать самый дешевый. Область <async> недостаточна для вас в этом случае, потому что вы хотите, чтобы поток, обрабатывающий запрос, действительно ожидал поступления ответов. Похоже, работа для многоадресного маршрутизатора!
Когда <все> просто недостаточно
Mule ESB уже имеет многоадресный маршрутизатор <all>, который направляет сообщение по нескольким маршрутам, а затем продолжает обработку после того, как все маршруты отвечают. Хотя это работает, у этого маршрутизатора есть ряд ограничений:
- Он использует последовательную обработку! Это означает, что все маршруты выполняются по порядку, один за другим в одном потоке. Это означает, что общее количество времени, которое мы должны ждать, пока мы не сможем достать все ответы, является суммой времени выполнения всех маршрутов.
- Он не очень хорошо справляется с обработкой ошибок: предположим, у вас есть 4 маршрута, как в примере выше. В случае сбоя второго маршрута маршруты 3 и 4 никогда не будут выполнены. Кроме того, вы получаете информацию только о сбое маршрута № 2, информация о маршруте 1 недоступна.
- Это не очень настраиваемый . В случае успеха многоадресный маршрутизатор всегда возвращает MuleMessageCollection. Итак, возвращаясь к примеру с бронированием поездки, у вас не может быть настроенного <all> маршрутизатора, который просто возвращает самый дешевый рейс вместо всей MuleMessageCollection.
Чтобы преодолеть это ограничение, в выпуске раннего доступа Mule 3.5 появился новый ребёнок: маршрутизатор <scatter-collect>.
Представляем Scatter-Gather
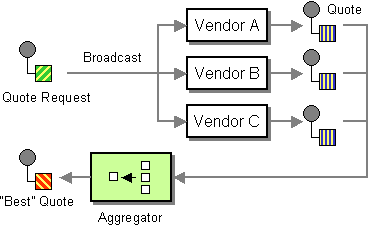
Шаблоны Enterprise Integration Patterns Scatter-Gather определяют: «
Scatter-Gather
направляет сообщение-запрос нескольким получателям. Затем он использует
агрегатор т
о собирать ответы и перегонять их в одно ответное сообщение. »
Мне бы хотелось описать это простым и более кратким способом, но я не могу, поэтому давайте просто сделаем краткий список различий с маршрутизатором <all> и перейдем к примеру:
- Параллельная обработка: Scatter-Gather использует пул потоков для одновременного выполнения всех маршрутов. Это означает, что общее время, в течение которого поток вызывающего абонента должен ждать маршрутов для ответа, больше не является суммой времени всего маршрута, а является только самым длинным из них.
- Лучшая обработка ошибок: поскольку все маршруты выполняются параллельно, один (или несколько) сбойных маршрутов не препятствуют выполнению других маршрутов. Кроме того, в случае исключения вы получите исключение CompositeRoutingException, которое содержит не только информацию обо всех неудачных маршрутах, но и ответы от успешных.
- Конфигурируемость: как говорится в определении EIP, для объединения ответов используется агрегатор. По умолчанию реализация Mule scatter-collect возвращает MuleMessageCollection, так что он соответствует маршрутизатору ye olde <all>, что упрощает миграцию для существующих пользователей и позволяет использовать улучшенную производительность. Тем не менее, вы можете заменить это своей собственной стратегией агрегации, но скоро доберетесь до этого…
Рассеяние в действии!
Чтобы упростить этот пример и проиллюстрировать повышение производительности за счет использования <scatter-collect> над <all>, я приведу старый пример, который я сделал более года назад в этом посте . В этом примере (который в основном рассматривает Google Connectors Suite и DataMapper ) мы берем электронную таблицу Google с контактной информацией о супергероях и используем ее для создания учетных записей Salesforce , контактов Google, встреч Google Calendar и задач Google . Подробности этого примера доступны в исходном сообщении, поэтому я просто сосредоточусь на той части, которая транслирует исходное сообщение (каждого супергероя, найденного в электронной таблице) на несколько маршрутов (salesforce и приложения Google). На уровне XML это, наконец, сводится к следующему:
<set-variable variableName="startTime" value="#[System.currentTimeMillis()]" doc:name="Variable" /> <all> <flow-ref name="to-salesforce" doc:name="to salesforce"/> <flow-ref name="to-google" doc:name="to google"/> </all> <set-payload value="Elapsed time: #[(System.currentTimeMillis() - flowVars['startTime']) /1000] seconds" />
При выполнении этого на моем локальном ПК полная интеграция занимает 9 секунд (это число может варьироваться в зависимости от вашего географического местоположения, пропускной способности и мощности процессора ноутбука). Теперь давайте посмотрим на тот же пример с новым маршрутизатором:
<set-variable variableName="startTime" value="#[System.currentTimeMillis()]" doc:name="Variable" /> <scatter-gather> <flow-ref name="to-salesforce" doc:name="to salesforce"/> <flow-ref name="to-google" doc:name="to google"/> </scatter-gather> <set-payload value="Elapsed time: #[(System.currentTimeMillis() - flowVars['startTime']) /1000] seconds" />
В этом случае время сократилось до 5 секунд: на 45% быстрее .
Custom AggregationStrategy
Давайте на секунду вернемся к примеру с самым дешевым рейсом. Предположим, что после того, как все маршруты ответили, вы хотите отфильтровать те, которые имели ошибки (если есть), а затем выбрать самый дешевый. Вы можете сделать это в Mule, используя потоки, но рассмотрите это более простое решение:
public class CheapeastFlightAggregationStrategy implements AggregationStrategy {
@Override
public MuleEvent aggregate(AggregationContext context) throws MuleException {
MuleEvent result;
long value = Long.MAX_VALUE;
for (MuleEvent event : context.collectEventsWithoutExceptions()) {
Flight flight = (Flight) event.getMessage().getPayload();
if (flight.getCost() < value) {
result = event;
value = flight.getCost();
}
}
return event;
}
}
Это классно! Я могу легко настроить агрегацию событий ответа, не беспокоясь о самой сложности агрегации! Но как мне использовать этот класс? Проверьте это:
<scatter-gather timeout="5000">
<custom-aggregation-strategy class="org.myproject.CheapestFlightAggregationStrategy" />
<flow-ref name="flightBroker1" />
<flow-ref name="flightBroker2" />
<flow-ref name="flightBroker3" />
</scatter-gather>
Убери прочь
- Новый маршрутизатор рассеяния-сбора обеспечит функциональность многоадресной рассылки более производительным способом, чем маршрутизатор <all>.
- Он также более настраиваемый и обеспечивает лучшую обработку ошибок.
- В большинстве сценариев вы должны предпочитать <scatter-collect>, а не <all>, за исключением тех случаев, когда сбой на одном из маршрутов должен остановить выполнение следующих действий. Есть сценарии, где такое поведение желательно, поэтому мы будем хранить <all> в качестве шаблона.
- Scatter-Gather доступен начиная с версии 3.5 раннего доступа Mule
Спасибо за чтение и с нетерпением ждем ваших отзывов!
Нет похожих сообщений.