Мир программного обеспечения движется быстрее, чем когда-либо. Чтобы оставаться конкурентоспособными, новые версии программного обеспечения должны быть развернуты как можно скорее, не мешая активным пользователям. Многие предприятия перенесли свою рабочую нагрузку в Кубернетес, которая была построена с учетом готовности к производству. Тем не менее, чтобы достичь реального времени простоя с Kubernetes, не прерывая и не теряя ни одного запроса в полете, нам нужно сделать еще несколько шагов.
Это первая часть серии из двух статей о том, как добиться (реального) времени простоя с нулевым временем простоя с использованием ресурсов входа Kubernetes и шлюза Istio. Эта часть охватывает простые Kubernetes.
Роллинг Обновления
По умолчанию Kubernetes внедряет обновления версии выкатного модуля с использованием стратегии непрерывного обновления. Эта стратегия направлена на предотвращение простоев приложений путем поддержания в рабочем состоянии по крайней мере некоторых экземпляров в любой момент времени при выполнении обновлений. Старые модули отключаются только после запуска новых модулей новой версии развертывания и их готовности обрабатывать трафик.
Инженеры могут также указать точный способ, которым Kubernetes манипулирует несколькими репликами во время обновления. В зависимости от рабочей нагрузки и доступных вычислительных ресурсов, которые мы можем захотеть настроить, сколько экземпляров мы хотим переоценить или предоставить недостаточно в любое время. Например, с учетом трех желаемых реплик, должны ли мы немедленно создать три новых модуля и дождаться запуска всех из них, следует ли завершить работу всех старых модулей, кроме одного, или выполнить переход по одному? В следующих фрагментах кода показано определение развертывания Kubernetes для приложения кафе, в котором используется стратегия обновления RollingUpdate по умолчанию и максимум один maxSurge предоставлением ( maxSurge ) и отсутствие недоступных модулей во время обновлений.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
kind: DeploymentapiVersion: apps/v1beta1metadata: name: coffee-shopspec: replicas: 3 template: # with image docker.example.com/coffee-shop:1 # ... strategy: type: RollingUpdate rollingUpdate: maxSurge: 1 maxUnavailable: 0 |
Развертывание coffee-shop приведет к созданию трех копий coffee-shop:1 изображение.
Эта конфигурация развертывания будет выполнять обновления версии следующим образом: она будет создавать один модуль с новой версией за раз, ждать, пока модуль запустится и станет готовым, вызвать завершение одного из старых модулей и продолжить с следующий новый модуль, пока все реплики не будут перенесены. Чтобы сообщить Kubernetes, когда наши модули работают и готовы обрабатывать трафик, нам нужно настроить датчики живучести и готовности .
Ниже показано, как выводятся kubectl get pods а также старые и новые pods со временем:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
$ kubectl get podsNAME READY STATUS RESTARTS AGEzero-downtime-5444dd6d45-hbvql 1/1 Running 0 3mzero-downtime-5444dd6d45-31f9a 1/1 Running 0 3mzero-downtime-5444dd6d45-fa1bc 1/1 Running 0 3m...zero-downtime-5444dd6d45-hbvql 1/1 Running 0 3mzero-downtime-5444dd6d45-31f9a 1/1 Running 0 3mzero-downtime-5444dd6d45-fa1bc 1/1 Running 0 3mzero-downtime-8dca50f432-bd431 0/1 ContainerCreating 0 12s...zero-downtime-5444dd6d45-hbvql 1/1 Running 0 4mzero-downtime-5444dd6d45-31f9a 1/1 Running 0 4mzero-downtime-5444dd6d45-fa1bc 0/1 Terminating 0 4mzero-downtime-8dca50f432-bd431 1/1 Running 0 1m...zero-downtime-5444dd6d45-hbvql 1/1 Running 0 5mzero-downtime-5444dd6d45-31f9a 1/1 Running 0 5mzero-downtime-8dca50f432-bd431 1/1 Running 0 1mzero-downtime-8dca50f432-ce9f1 0/1 ContainerCreating 0 10s......zero-downtime-8dca50f432-bd431 1/1 Running 0 2mzero-downtime-8dca50f432-ce9f1 1/1 Running 0 1mzero-downtime-8dca50f432-491fa 1/1 Running 0 30s |
Обнаружение пробелов в доступности
Если мы выполняем непрерывное обновление от старой версии до новой и следим за выводом, какие модули активны и готовы, поведение в первую очередь кажется правильным. Однако, как мы можем видеть, переход от старой к новой версии не всегда происходит идеально, то есть приложение может потерять некоторые запросы клиентов.
Чтобы проверить, потеряны ли запросы в полете, особенно те, которые были направлены к экземпляру, который выводится из эксплуатации, мы можем использовать инструменты нагрузочного тестирования, которые подключаются к нашему приложению. Основной вопрос, который нас интересует, заключается в том, правильно ли обрабатываются все HTTP-запросы, включая HTTP-соединения keep-alive. Для этого мы используем инструмент нагрузочного тестирования, например Apache Bench или Fortio .
Мы подключаемся к нашему запущенному приложению через HTTP одновременно, используя несколько потоков, то есть несколько подключений. Вместо того чтобы обращать внимание на задержку или пропускную способность, нас интересуют статусы ответа и потенциальные сбои соединения.
В примере Fortio вызов с 500 запросами в секунду и 50 одновременными соединениями keep-alive выглядит следующим образом:
|
1
|
|
Опция -a заставляет Fortio сохранять отчет, чтобы мы могли просматривать его с помощью HTML GUI. Если мы запустим этот тест, когда происходит развертывание обновлений, мы, скорее всего, увидим, что несколько запросов не могут соединиться:
|
1
2
3
4
5
6
7
8
9
|
Fortio 1.1.0 running at 500 queries per second, 4->4 procs, for 20sStarting at 500 qps with 50 thread(s) [gomax 4] for 20s : 200 calls each (total 10000)08:49:55 W http_client.go:673> Parsed non ok code 502 (HTTP/1.1 502)[...]Code 200 : 9933 (99.3 %)Code 502 : 67 (0.7 %)Response Header Sizes : count 10000 avg 158.469 +/- 13.03 min 0 max 160 sum 1584692Response Body/Total Sizes : count 10000 avg 169.786 +/- 12.1 min 161 max 314 sum 1697861[...] |
Вывод указывает, что не все запросы могут быть успешно обработаны. Мы можем запустить несколько тестовых сценариев, которые подключаются к приложению различными способами, например, через вход Kubernetes или напрямую через сервис изнутри кластера. Мы увидим, что поведение во время непрерывного обновления может варьироваться в зависимости от того, как подключается наша тестовая установка. Клиенты, которые подключаются к службе из кластера, могут не испытывать столько неудачных подключений, сколько подключение через вход.
Понимание того, что происходит
Теперь вопрос в том, что именно происходит, когда Kubernetes перенаправляет трафик во время непрерывного обновления со старой версии на новую версию модуля. Давайте посмотрим, как Kubernetes управляет соединениями с рабочей нагрузкой.
Если наш клиент, то есть тест с нулевым временем простоя, подключается к службе coffee-shop непосредственно из кластера, он обычно использует VIP службы, разрешенный через DNS кластера, и в конечном итоге оказывается в экземпляре Pod. Это реализуется с помощью kube-proxy, который работает на каждом узле Kubernetes и обновляет iptables, которые маршрутизируют на IP-адреса модулей.
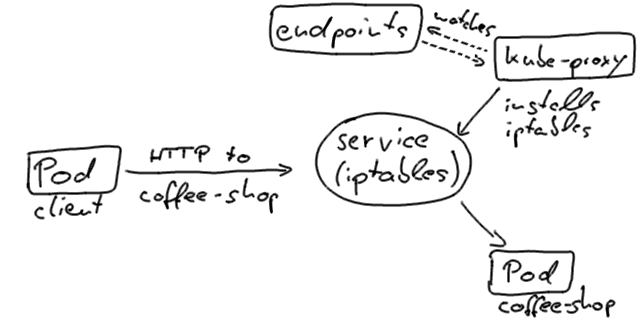
Kubernetes обновит объекты конечных точек в состояниях модулей так, чтобы он содержал только те модули, которые готовы обрабатывать трафик.
Входы Kubernetes, однако, соединяются с экземплярами немного по-другому. По этой причине вы заметите различное поведение простоев при обновлении, когда ваш клиент подключается к приложению через входной ресурс.
Вход NGINX напрямую включает адреса модулей в своей исходящей конфигурации. Он независимо наблюдает за изменениями объектов конечных точек.
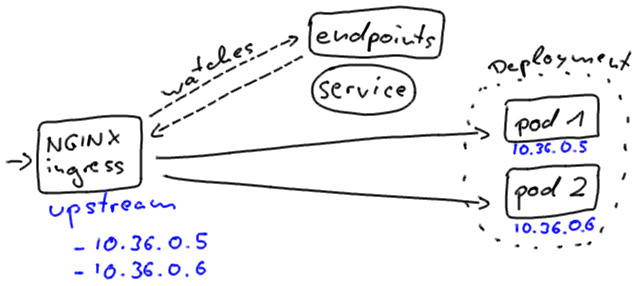
Независимо от того, как мы подключаемся к нашему приложению, Kubernetes стремится минимизировать сбои в работе службы в процессе непрерывного обновления.
Как только новый модуль будет активен и готов, Kubernetes выведет из эксплуатации старый модуль и, таким образом, изменит статус модуля на « Terminating , удалит его из объекта конечных точек и отправит SIGTERM . SIGTERM заставляет контейнер корректно завершать работу (надеюсь) и не принимать никаких новых соединений. После того, как модуль был удален из объекта конечных точек, балансировщики нагрузки перенаправят трафик на оставшиеся (новые). Это то, что вызывает наш разрыв в доступности в нашем развертывании; модуль деактивируется сигналом завершения до или, скорее, когда балансировщик нагрузки замечает изменение и может обновить свою конфигурацию. Эта переконфигурация происходит асинхронно, таким образом, не дает никаких гарантий правильного упорядочения, и может и приведет к тому, что несколько неудачных запросов будут направлены в завершающий модуль.
На пути к нулевому времени простоя
Как улучшить наши приложения для реализации (реальной) миграции без простоев?
Прежде всего, необходимым условием для достижения этой цели является то, что наши контейнеры правильно обрабатывают сигналы завершения, то есть процесс будет корректно остановлен на Unix SIGTERM . Посмотрите лучшие практики Google по созданию контейнеров, как этого добиться. Все основные серверы приложений Java Enterprise обрабатывают сигналы завершения; Мы, разработчики, должны правильно их докеризировать .
Следующим шагом является включение зондов готовности, которые проверяют, готово ли наше приложение для обработки трафика. В идеале зонды уже проверяют состояние функциональности, которая требует прогревов, таких как кеши или инициализация сервлета.
Датчики готовности являются нашей отправной точкой для сглаживания обновлений. Чтобы решить проблему, preStop в том, что завершения модуля в настоящее время не блокируются, и подождать, пока балансировщики нагрузки не будут перенастроены, мы добавим preStop жизненного цикла preStop . Этот хук вызывается до завершения контейнера.
Хук жизненного цикла является синхронным, поэтому должен завершиться до отправки окончательного сигнала завершения в контейнер. В нашем случае мы используем этот хук только для отключения готовности, пока приложение остается полностью функциональным. После сбоя проверки готовности модуль будет исключен из объекта конечных точек службы независимо от текущей попытки завершения и, следовательно, также исключен из наших балансировщиков нагрузки. Чтобы убедиться, что наши балансировщики нагрузки переконфигурированы, мы включим период ожидания, прежде чем вернется ловушка жизненного цикла и контейнер все равно будет завершен.
Чтобы реализовать это поведение, мы определяем preStop в нашем развертывании coffee-shop :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
kind: DeploymentapiVersion: apps/v1beta1metadata: name: coffee-shopspec: replicas: 3 template: spec: containers: - name: zero-downtime image: docker.example.com/coffee-shop:1 livenessProbe: # ... readinessProbe: # ... lifecycle: preStop: exec: command: ["/bin/bash", "-c", "/deactivate-health-check.sh && sleep 20"] strategy: # ... |
От выбранной вами технологии зависит, как реализовать тесты готовности и живучести, а также поведение ловушки жизненного цикла; последний указывается как сценарий deactivate-health-check.sh с синхронным льготным периодом 20 секунд. Сценарий немедленно вызовет сбой датчика готовности, в то время как процесс выключения продолжается только после 20 секунд ожидания.
В случае Java Enterprise мы обычно реализуем зонды как HTTP-ресурсы, например, с использованием JAX-RS или MicroProfile Health. Хук жизненного цикла должен был бы деактивировать ресурс проверки работоспособности с помощью другого метода или некоторых внутренних ресурсов контейнера.
Теперь, когда мы будем наблюдать за поведением наших модулей во время развертывания, мы увидим, что завершающий модуль будет в состоянии Terminating и медленно изменит свою готовность на false прежде чем он будет окончательно завершен. Если мы повторно протестируем наш подход с Apache Bench, мы увидим желаемое поведение нулевых неудачных запросов:
|
1
2
3
4
5
6
7
|
Fortio 1.1.0 running at 500 queries per second, 4->4 procs, for 20sStarting at 500 qps with 50 thread(s) [gomax 4] for 20s : 200 calls each (total 10000)[...]Code 200 : 10000 (100.0 %)Response Header Sizes : count 10000 avg 159.530 +/- 0.706 min 154 max 160 sum 1595305Response Body/Total Sizes : count 10000 avg 168.852 +/- 2.52 min 161 max 171 sum 1688525[...] |
Вывод
Kubernetes отлично справляется с управлением приложениями с учетом готовности к производству. Однако для того, чтобы наши корпоративные системы работали в производственном режиме, важно, чтобы мы, инженеры, знали как о том, как Kubernetes работает под капотом, так и о том, как наши приложения ведут себя при запуске и завершении работы.
Во второй части серии статей мы увидим, как достичь той же цели обновлений без простоев, когда мы запускаем Istio поверх Kubernetes. Мы также узнаем, как объединить эти подходы со средами непрерывной доставки.
Дополнительные ресурсы
- Пример проекта GitHub (входная версия Kubernetes)
- Услуги — Kubernetes документация
- Прекращение стручков — Kubernetes документация
- Нулевое время простоя в Куберне Криса Мооса — спасибо автору за вдохновляющие статьи
- Лучшие практики для построения контейнеров — Google Cloud
| Опубликовано на Java Code Geeks с разрешения Себастьяна Дашнера, партнера нашей программы JCG. Смотрите оригинальную статью здесь: Обновления с нулевым временем простоя с Kubernetes
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |