Вступление
В предыдущих статьях мы показали архитектуру NuoDB NewSQL , ее ключевые компоненты и способы ее легкого масштабирования по уровням транзакций и хранения. Мы также продемонстрировали JDBC и Hibernate с NuoDB. В этом последнем посте из трех статей мы продемонстрируем Spring и Hibernate с NuoDB в облачном масштабе с использованием возможностей AWS (AWS EC2 и CloudFormation).
Весна и зимняя спячка с NuoDB
Spring PetClinic — это пример приложения, распространяемого со средой Spring. Он предназначен для того, чтобы показать, как среды разработки Spring можно использовать для создания простых, но мощных приложений, ориентированных на базы данных. В этом году он был подвергнут рефакторингу для новой архитектуры, и исходный код можно загрузить с GitHub . Spring PetClinic из коробки поддерживает базы данных HSQL и MySQL, и в этом посте мы перенесем его на использование NuoDB.
Чтобы получить код, нам нужно запустить:
$ git clone https://github.com/SpringSource/spring-petclinic.git
Приложение можно собрать и запустить с помощью команды maven. Но сначала нам нужно реализовать изменения, связанные с NuoDB, все из которых связаны с настройкой базы данных и обновлением конфигураций Hibernate и Spring. Другими словами, ни один источник приложения не нуждается в модификации.
Сценарии для слоя DB можно найти в каталоге ~ / spring / spring-petclinic / src / main / resources / db . Там мы создали новый каталог nuodb и создали два сценария SQL: initDB.sql и populateDB.sql.
$ cd ~/spring/spring-petclinic/src/main/resources/db $ mkdir nuodb $ vi initDB.sql # edit initDB.sql DROP TABLE vet_specialties IF EXISTS; DROP TABLE vets IF EXISTS; DROP TABLE specialties IF EXISTS; DROP TABLE visits IF EXISTS; DROP TABLE pets IF EXISTS; DROP TABLE types IF EXISTS; DROP TABLE owners IF EXISTS; CREATE TABLE vets ( id INTEGER primary key generated always as identity, first_name VARCHAR(30), last_name VARCHAR(30) ); CREATE INDEX vets_last_name ON vets (last_name); CREATE TABLE specialties ( id INTEGER primary key generated always as identity, name VARCHAR(80) ); CREATE INDEX specialties_name ON specialties (name); CREATE TABLE vet_specialties ( vet_id INTEGER NOT NULL, specialty_id INTEGER NOT NULL ); ALTER TABLE vet_specialties ADD CONSTRAINT fk_vet_specialties_vets FOREIGN KEY (vet_id) REFERENCES vets (id); ALTER TABLE vet_specialties ADD CONSTRAINT fk_vet_specialties_specialties FOREIGN KEY (specialty_id) REFERENCES specialties (id); CREATE TABLE types ( id INTEGER primary key generated always as identity, name VARCHAR(80) ); CREATE INDEX types_name ON types (name); CREATE TABLE owners ( id INTEGER primary key generated always as identity, first_name VARCHAR(30), last_name VARCHAR(30), address VARCHAR(255), city VARCHAR(80), telephone VARCHAR(20) ); CREATE INDEX owners_last_name ON owners (last_name); CREATE TABLE pets ( id INTEGER primary key generated always as identity, name VARCHAR(30), birth_date DATE, type_id INTEGER NOT NULL, owner_id INTEGER NOT NULL ); ALTER TABLE pets ADD CONSTRAINT fk_pets_owners FOREIGN KEY (owner_id) REFERENCES owners (id); ALTER TABLE pets ADD CONSTRAINT fk_pets_types FOREIGN KEY (type_id) REFERENCES types (id); CREATE INDEX pets_name ON pets (name); CREATE TABLE visits ( id INTEGER primary key generated always as identity, pet_id INTEGER NOT NULL, visit_date DATE, description VARCHAR(255) ); ALTER TABLE visits ADD CONSTRAINT fk_visits_pets FOREIGN KEY (pet_id) REFERENCES pets (id); CREATE INDEX visits_pet_id ON visits (pet_id); $ vi populateDB.qsl # edit populateDB.sql INSERT INTO vets VALUES (NULL, 'James', 'Carter'); INSERT INTO vets VALUES (NULL, 'Helen', 'Leary'); INSERT INTO vets VALUES (NULL, 'Linda', 'Douglas'); INSERT INTO vets VALUES (NULL, 'Rafael', 'Ortega'); INSERT INTO vets VALUES (NULL, 'Henry', 'Stevens'); INSERT INTO vets VALUES (NULL, 'Sharon', 'Jenkins'); INSERT INTO specialties VALUES (NULL, 'radiology'); INSERT INTO specialties VALUES (NULL, 'surgery'); INSERT INTO specialties VALUES (NULL, 'dentistry'); INSERT INTO vet_specialties VALUES (2, 1); INSERT INTO vet_specialties VALUES (3, 2); INSERT INTO vet_specialties VALUES (3, 3); INSERT INTO vet_specialties VALUES (4, 2); INSERT INTO vet_specialties VALUES (5, 1); INSERT INTO types VALUES (NULL, 'cat'); INSERT INTO types VALUES (NULL, 'dog'); INSERT INTO types VALUES (NULL, 'lizard'); INSERT INTO types VALUES (NULL, 'snake'); INSERT INTO types VALUES (NULL, 'bird'); INSERT INTO types VALUES (NULL, 'hamster'); INSERT INTO owners VALUES (NULL, 'George', 'Franklin', '110 W. Liberty St.', 'Madison', '6085551023'); INSERT INTO owners VALUES (NULL, 'Betty', 'Davis', '638 Cardinal Ave.', 'Sun Prairie', '6085551749'); INSERT INTO owners VALUES (NULL, 'Eduardo', 'Rodriquez', '2693 Commerce St.', 'McFarland', '6085558763'); INSERT INTO owners VALUES (NULL, 'Harold', 'Davis', '563 Friendly St.', 'Windsor', '6085553198'); INSERT INTO owners VALUES (NULL, 'Peter', 'McTavish', '2387 S. Fair Way', 'Madison', '6085552765'); INSERT INTO owners VALUES (NULL, 'Jean', 'Coleman', '105 N. Lake St.', 'Monona', '6085552654'); INSERT INTO owners VALUES (NULL, 'Jeff', 'Black', '1450 Oak Blvd.', 'Monona', '6085555387'); INSERT INTO owners VALUES (NULL, 'Maria', 'Escobito', '345 Maple St.', 'Madison', '6085557683'); INSERT INTO owners VALUES (NULL, 'David', 'Schroeder', '2749 Blackhawk Trail', 'Madison', '6085559435'); INSERT INTO owners VALUES (NULL, 'Carlos', 'Estaban', '2335 Independence La.', 'Waunakee', '6085555487'); INSERT INTO pets VALUES (NULL, 'Leo', '2010-09-07', 1, 1); INSERT INTO pets VALUES (NULL, 'Basil', '2012-08-06', 6, 2); INSERT INTO pets VALUES (NULL, 'Rosy', '2011-04-17', 2, 3); INSERT INTO pets VALUES (NULL, 'Jewel', '2010-03-07', 2, 3); INSERT INTO pets VALUES (NULL, 'Iggy', '2010-11-30', 3, 4); INSERT INTO pets VALUES (NULL, 'George', '2010-01-20', 4, 5); INSERT INTO pets VALUES (NULL, 'Samantha', '2012-09-04', 1, 6); INSERT INTO pets VALUES (NULL, 'Max', '2012-09-04', 1, 6); INSERT INTO pets VALUES (NULL, 'Lucky', '2011-08-06', 5, 7); INSERT INTO pets VALUES (NULL, 'Mulligan', '2007-02-24', 2, 8); INSERT INTO pets VALUES (NULL, 'Freddy', '2010-03-09', 5, 9); INSERT INTO pets VALUES (NULL, 'Lucky', '2010-06-24', 2, 10); INSERT INTO pets VALUES (NULL, 'Sly', '2012-06-08', 1, 10); INSERT INTO visits VALUES (NULL, 7, '2013-01-01', 'rabies shot'); INSERT INTO visits VALUES (NULL, 8, '2013-01-02', 'rabies shot'); INSERT INTO visits VALUES (NULL, 8, '2013-01-03', 'neutered'); INSERT INTO visits VALUES (NULL, 7, '2013-01-04', 'spayed');
Затем нам пришлось изменить файл business-config.xml в каталоге ~ / spring / spring-petclinic / src / main / resources / spring, чтобы он ссылался на правильный NuoDB hibernate.dialect с помощью свойства hibernate.dialect:
# business-config.xml
<bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"
p:dataSource-ref="dataSource">
<property name="jpaVendorAdapter">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter" />
</property>
<property name="jpaPropertyMap">
<map>
<entry key="hibernate.show_sql" value="${jpa.showSql}" />
<entry key="hibernate.dialect" value="${hibernate.dialect}" />
<entry key="hibernate.temp.use_jdbc_metadata_defaults" value="false" />
</map>
</property>
<property name="persistenceUnitName" value="petclinic"/>
<property name="packagesToScan" value="org.springframework.samples.petclinic"/>
</bean>
In order to support Hibernate 4, we also set hibernate.temp.use_jdbc_metadata_defaults to false.
The database properties can be configured in the data-access.properties file—this file contains the appropriate JDBC parameters (used in data-source.xml) as well as the Hibernate dialect. The sample below has a reference to a local NuoDB instance running on an Ubuntu virtual machine and an AWS EC2 instance (commented out) that will be configured later on in this article:
jdbc.driverClassName=com.nuodb.jdbc.Driver jdbc.url=jdbc:com.nuodb://192.168.80.128/spring?schema=user #jdbc.url=jdbc:com.nuodb://ec2-46-51-162-14.eu-west-1.compute.amazonaws.com/spring?schema=user jdbc.username=spring jdbc.password=spring # Properties that control the population of schema and data for a new data source jdbc.initLocation=classpath:db/nuodb/initDB.sql jdbc.dataLocation=classpath:db/nuodb/populateDB.sql # Property that determines which Hibernate dialect to use # (only applied with "applicationContext-hibernate.xml") hibernate.dialect=com.nuodb.hibernate.NuoDBDialect # Property that determines which database to use with an AbstractJpaVendorAdapter jpa.showSql=true
The datasource-config.xml file defines the data source bean using JDBC:
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close"
p:driverClassName="${jdbc.driverClassName}" p:url="${jdbc.url}"
p:username="${jdbc.username}" p:password="${jdbc.password}"/>
The original pom.xml from GitHub refers to Hibernate 4, and NuoDB can support Hibernate 4, so my pom.xml looked like this:
# pom.xml
<properties>
<hibernate.version> 4.1.0.Final</hibernate.version>
<hibernate-validator.version> 4.2.0.Final</hibernate-validator.version>
<nuodb.version>1.1</nuodb.version>
</properties>
<dependencies>
<dependency>
<groupId>com.nuodb</groupId>
<artifactId>nuodb-hibernate</artifactId>
<version>${nuodb.version}</version>
</dependency>
<dependency>
<groupId>com.nuodb</groupId>
<artifactId>nuodb-jdbc</artifactId>
<version>${nuodb.version}</version>
</dependency>
</dependencies>
Finally, we need to change web.xml in the ~/spring/spring-petclinic/src/main/webapp/WEB-INF directory to use jpa – the out-ot-the-box configuration uses jdbc.
<context-param>
<param-name>spring.profiles.active</param-name>
<param-value>jpa</param-value>
</context-param>
Now we can run the maven command to compile the code, initialize and populate NuoDB tables and then listen to port 9966 for requests.
$ mvn tomcat7:run
and we can connect Spring using http://localhost:9966/petclinic/.

Spring PetClinic using NuoDB on AWS
Until now we used a local NuoDB instance. It’s time to migrate the database layer onto the AWS cloud. To run NuoDB on AWS EC2 instances, one of the simplest options is to use AWS CloudFormation. There are CloudFormation templates available on github.
To download them, we can run
$ git clone https://github.com/nuodb/cloudformation.git
Then we need to open the AWS management console, go to CloudFormation and select «Create Stack» and upload the NuoDB template (e.g., NuoDB-1.1.template in our case). Then we can define the number of agents (in addition to the broker), the domain name, the domain admin username and password and the EC2 instance type.

Once we click on «Continue», the EC2 instances are going to be created. The status first will be CREATE_IN_PROGRESS, then CREATE_COMPLETE.
As a result, we will get three EC2 instances (since we selected three agents): one dedicated to the NuoDB broker and the other two for the NuoDB agents. We will also have three EBS volumes, one for each EC2 instance.
CAUTION: The NuoDB CloudFormation script uses an EC2 auto-scaling group that ensures that the number of agents you selected will always be running. As a result, if you just stop the EC2 instances at the end of your test, AWS will restart them. In order to stop everything properly and clean up your test environment, open the AWS management console, go to CloudFormation, select the NuoDB stack and click “Delete Stack.” This will terminate all instances that were started by the CloudFormation template. More on AWS auto-scaling and how to use the command line tool can be found on the AWS website.
Now we can connect to the EC2 host that runs the NuoDB broker:

Once we log in, we can start a database:
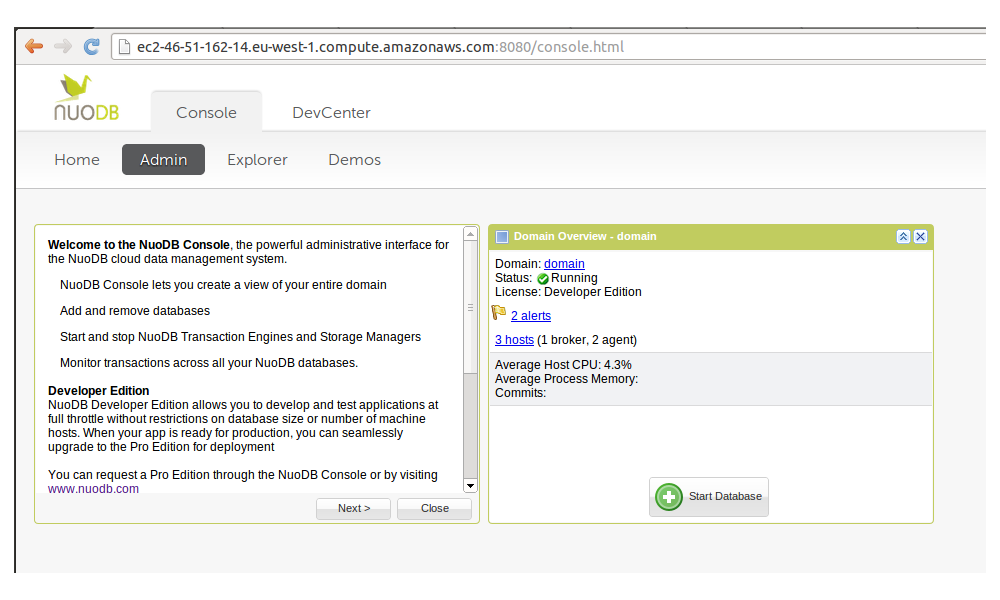
In the next steps, we can define the database name («spring»), leave the “allow non-durable database” option un-selected and the archive and journal directories for the storage manager running on one of the hosts (/home/ec2-user/nuodb/data and /home/ec2-user/nuodb/journal respectively). Please note that the /home/ec2-user directory has to have the appropriate rights to allow the creation of the data and journal directory (-rwxrwxrwx in our test).

After that, we can define the transaction engine running on the other EC2 host:

Now we have three EC2 hosts: one dedicated to the NuoDB broker to serve client connections, one for the storage manager with filesystem storage and one for the transaction engine.
Now, if we change the JDBC connection string in Spring PetClinic (remember, it is defined in data-access.properties), we can connect our application to NuoDB using AWS servers. The reason why the connection is possible is because AWS security groups allow any servers to be connected.
$ vi data-access.properties #jdbc.url=jdbc:com.nuodb://192.168.80.128/spring?schema=user jdbc.url=jdbc:com.nuodb://ec2-46-51-162-14.eu-west-1.compute.amazonaws.com/spring?schema=user
We can then rerun the Spring PetClinic command, this time with the database in the AWS cloud:
$ mvn tomcat7:run
Once the Tomcat server is up and running, we can go to http://ec2-46-51-162-14.eu-west-1.compute.amazonaws.com:9966/petclinic/ and search for vets, add new owners, search for them, etc.



Scale-out and Resilience
Scale-out is a method of adding computing resources by adding additional computers to the system, rather than increasing the computing resources on the computers in the system. Resilience is the ability to provide and maintain an acceptable level of service in case of faults.
If we want to scale out our database and also make it resilient, we can simply go back to the NuoDB console and add a new process using the «Add Process» menu. For instance, we can add a transaction engine to the EC2 server that was originally running the storage manager, and we can also add a storage manager to the EC2 server previously running a transaction server. This way, we have two EC2 servers both running one instance of the transaction engine and the storage manager.
Scaling out the database is a seamless process for the Spring PetClinic application. We just start up another EC2 server with an agent and add a transaction engine or a storage engine.
As can be seen in the NuoDB Performance Report, NuoDB scales almost linearly. The diagram below shows how the number of transactions per second (TPS) can be increased by adding a new node:

Conclusion
As we have seen in this series, NuoDB combines the standard SQL and ACID properties with elastic scalability that makes it perfectly suitable for being a robust cloud data management system for the 21st century. Its unique architectural approach provides high-performance reads and writes and geo-distributed 24/7 operations with built-in resilience. Moreover, applications using well-known frameworks such as Spring and Hibernate can be easily ported or developed with NuoDB as a NewSQL database that meets cloud-scale demands.