Эта проблема
Очевидно, что существует множество различных способов синхронизации баз данных, так почему это должно быть описано снова? Давайте представим, что у нас необычная ситуация с ограничениями ниже:
- В будущей системе будет несколько головных офисов ( HO ) и несколько филиалов ( BO )
- Все офисы расположены в разных местах, и некоторые из них испытывают трудности с подключением к интернету. Это может быть даже ситуация, когда интернет доступен по 1-2 часа в день.
- Почти все важные данные создаются в HO и должны быть представлены в BO только для чтения.
- Обмен данными должен быть ограничен соответствующими разрешениями (например, если оператор создал некоторые конфиденциальные данные в HO для BO1, только BO1 должен иметь доступ к ним).
- HO должен иметь доступ ко всей информации, которая была создана или изменена в BO.
По всем описанным пунктам было принято окончательное решение о написании собственного механизма синхронизации БД.
Основная идея
Из-за ухудшения связи между HO и BO, мы должны синхронизировать все в течение краткосрочных сессий.
Поскольку в общих случаях нет необходимости отправлять информацию во все филиалы, мы должны иметь возможность управлять потоком данных.
Эти мысли приводят нас к мысли, что мы могли бы реализовать какой-то RPC, когда событие происходит в одном офисе, а оно воспроизводится (воспроизводится) в другом. Очереди сообщений ( MQ ) являются идеальным решением для синхронизации данных между ветвями. RabbitMQ — мой любимый MQ, поэтому я буду использовать его в этом примере. Также это приложение будет использовать стек .NET, который имеет удобную клиентскую реализацию API для RabbitMQ под названием EasyNetQ .
Архитектура приложений высокого уровня
Согласно идее воспроизведения некоторых действий в других экземплярах системы, мы должны быть в состоянии разделить их на отдельные бизнес-логические операции. Лучший способ добиться этого — использовать метод Aggregate Roots . Основная идея состоит в том, чтобы разделить объекты, которые разделены объектами домена, и каждый вызов методов этих объектов представляет собой одно изменение состояния бизнес-логики. Например, если у нас есть какой-либо объект предметного документа Document и возможность Get , Upsert или Apply / Unapply , мы должны описать его корень как (псевдокод):
public class DocumentRoot
{
public Document Get(Id) { ... }
public Document Upsert(Document) { ... }
public bool Apply(Id) { ... }
public bool UnApply(Id) { ... }
}
Кроме того, очень важно, чтобы каждый вызов был в транзакции, чтобы избежать потери данных. Это может быть достигнуто с помощью простого метода перехвата (например, Autofac + Castle.Proxy). В других мирах основной процесс будет выглядеть так:
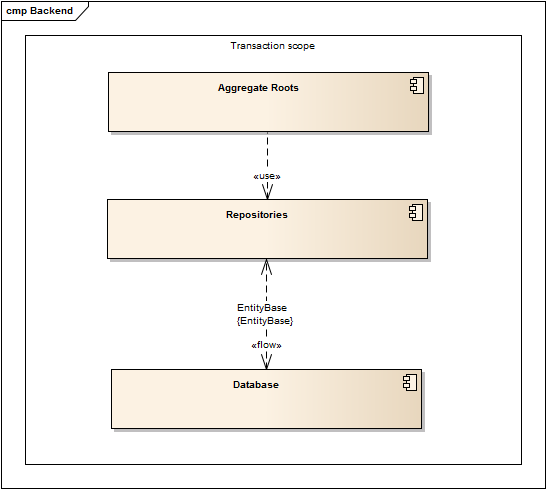
Keep in mind things as entities primary keys, because data will be populated between different system instances, and we’ll need to be sure that ID’s will be the same.
Also, collisions are possible while using simple auto-incrementing PK’s, so our choice is GUID. With the help of a base repository, it’s very simple to implement new GUID storage during object creation. Let’s assume that we have an ExchangeInformation object that handles all data needed to restore a root call on a remote system. It will contain info about the method name, type name, input, and output params – this data can be obtained from a root interceptor. Also, it should have the list of new ID’s, but it’s not hard to get them too, even though we’ll need to implement the UnitOfWork pattern on an ORM type to support transactions. This will allow us to place our ExchangeInformation in that UoF object (for example, within Entity Framework it’s DbContext). Here is the implementation (using EF) of saving any changes in a domain within the base generic repository where the base entity looks like:
public class EntityBase
{
public long Id { get; set; }
public Guid Guid { get; set; }
}
public virtual void Save(T entity)
{
DbEntityEntry<T> entry = Context.Entry(entity);
if (entity.Guid == Guid.Empty)
{
try
{
Guid newGuid = Context.ExchangeInformation.IsExchangeRestore
? Context.ExchangeInformation.NewGuids[0]
: Guid.NewGuid();
if (Context.ExchangeInformation.IsExchangeRestore)
{
Context.ExchangeInformation.NewGuids.RemoveAt(0);
}
else
{
Context.ExchangeInformation.NewGuids.Add(newGuid);
}
entity.Guid = newGuid;
}
catch
{
throw new Exception("Failed to restore exchange, no guid found");
}
entry.State = EntityState.Added;
return;
}
Context.Entry(entity).State = EntityState.Modified;
}
One more important note: to avoid code duplication, it’s necessary to use GUID’s on clients, because if they operate any other ID’s we’ll need to write two different implementations of any method.
Big Picture
After preparation completion, we can proceed with architecture design. Since every system instance should be able to send and receive new data, we can declare two RMQ topics: input and output. Also, because message flow must be orchestrated, queues for each system instance should be created within the output topic. The simplest strategy for a routing implementation is to use the branch office guide as a key.
So we know how to do following at the moment :
- Save the source event in one office.
- Put this event to selected queues (selection could be made but it depends on the situation: read from the entity, call some additional method, use attributes etc.)
The next step is a solution for how to make output events from one office appear in the input queue of the other office.
RabbitMQ has two plugins for that: Federation and Shovel. They are quite similar, but shovel is working on a lower level and has more options to control the synchronization process, so that we’ll use the second one to link queues. Shovel is very good with handling connection degradation and has lot of additional configurable options like message republishing properties, routing etc.
Now it’s time to combine all pieces in to single picture:
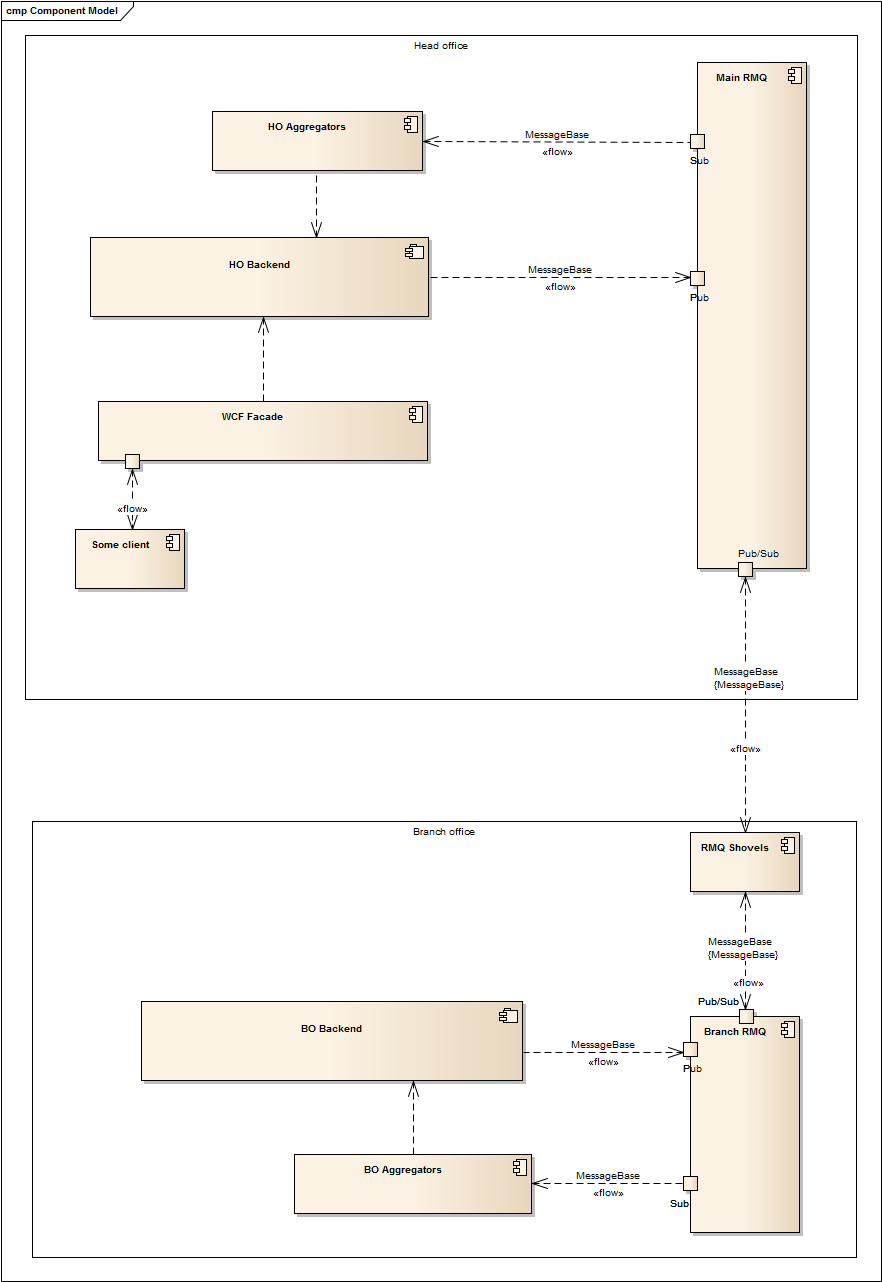
Aggregators here are simple RabbitMQ consumers that handle incoming messages from other offices and launch appropriate methods.
One other problem is restoring transferred params. From my point of view the best way is to use Json.Net with type serialization and restore them on a remote system instance with a small hack:
private object[] GetParams(MethodInfo methodInfo, ExchangeInformation information, ExchangeMessage message)
{
ParameterInfo[] methodParams = methodInfo.GetParameters();
var listParams = new List<object>();
var inputParms = JsonConvert.DeserializeObject<List<JObject>>(information.InputParamsString);
for (int ii = 0; ii < methodParams.Length; ii++)
{
var jObject = JsonConvert.DeserializeObject<JObject>(information.OutputValueString);
string typeName = jObject["$type"].ToString();
listParams.Add(jObject.ToObject(Type.GetType(typeName)));
}
return listParams.ToArray();
}
Surely appropriate conditions for params count mismatch, so valid deserialization and so on are required.
Conclusions
The approach I’ve described is very easy to implement and it has lots of additional places that can be customized. For example, any other method can be executed before/instead of/after restoration on a target branch to change the logic of DOM behavior.
The main issue is that collisions can occur if two BOs edit same object at the same time. Actually, it’s not hard to track this situation by adding a hash to EntityBase. Nevertheless, a human’s decision is needed to resolve conflicts, so a simple UI is necessary in the HO where the operator can choose which data is correct.