Я всегда очень публично писал о том, как меня задумывали, строили и действительно, как он работает. Если когда-нибудь и было время оглянуться назад на это представление, то это произошло после первых нескольких дней после загрузки в нарушение Эшли Мэдисон. Я хочу поделиться «бородавками и всем рассказом» о том, что я наблюдал за три дня последовавшего за этим хаоса.
Я впервые узнал об инциденте в среду около 6 утра по местному времени, который произошел вскоре после того, как торрент впервые вышел в эфир (помните, я в Австралии, которая в будущем для большинства из вас). В течение дня я устранял нарушение, обрабатывал его и в конце концов получал данные в реальном времени около 20:30 той ночью, после чего трафик быстро увеличивался, пока не достиг пика в 11:00 на следующее утро. Вот трехдневный график из Google Analytics среды 19, четверга 20 и пятницы 21 (суббота также была исключительно занята, но все графики Новой Реликвии — три дня, поэтому я буду придерживаться этого периода):

Подумайте об этом на мгновение: сайт перешел с 96 сеансов в час в самый тихий период до 55 611 в самый загруженный. Когда мы говорим о масштабах облаков, это персонифицировано — я заметил увеличение трафика на 58 000% за чуть более 24 часов. Это «заголовочный» показатель, но вот еще один для вас, и вот этот график производительности за те же три дня:
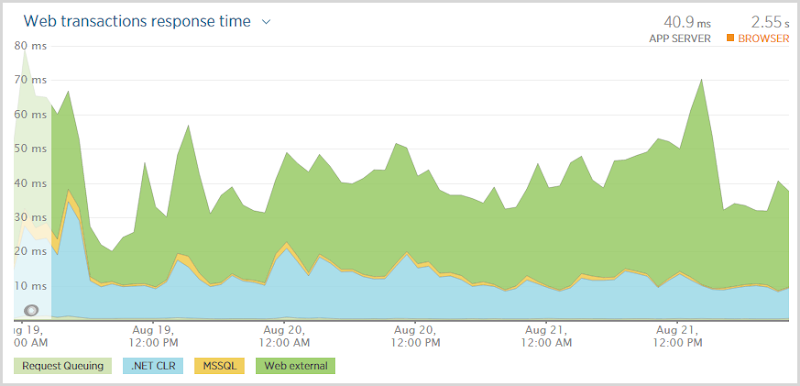
Что мне нравится в этом графике, так это то, что он никак не связан с этим изменением трафика! На самом деле время транзакции, вероятно, немного выше в самом начале, когда трафик почти не существовал. Я получил достаточно хорошее масштабирование Azure, чтобы производительность не снижалась, независимо от того, было ли на сайте десяток человек или, ну, в общем, много
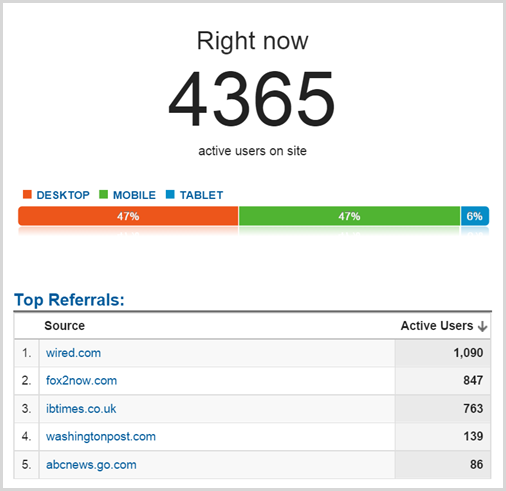
Я снял это в Google Analytics в 05:46 утра четверга в час, когда было 34 240 сеансов, так что в пиковые часы 55 611 было больше как 7k одновременно. На самом деле, назвать это больше похоже среднее из 8.5k одновременных сессий в течение периода часа , потому что это в соответствии с Google Analytics , и я нахожу реальный трафик, как правило , около 20% выше из — за блокирование рекламы и других инструментов, блокирующие отслеживания. Фактический пик в течение этого часа? Кто знает, что-то более 10к, наверное.
Теперь я сказал, что это будет анализ «бородавок и всего», что означает, что мне нужно показать вам следующее:
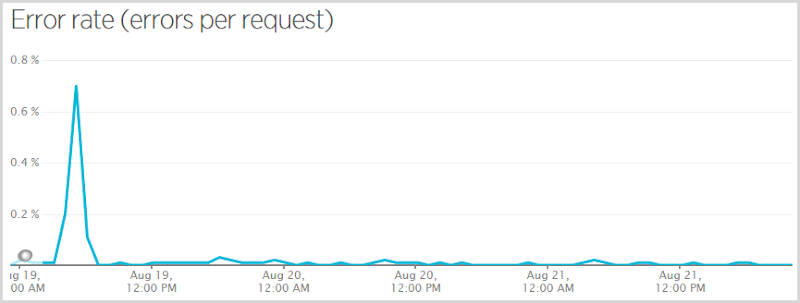
Когда я изначально опубликовал код, который исключил данные Эшли Мэдисон из результатов публичного поиска (подробнее об этом здесь — это очень важный пост о том, как я принял решение о том, что эти данные не должны быть доступны для публичного поиска), я получил пустую ссылку исключение, когда кто-то подписался на сервис, подтвердил свою электронную почту и не был в нарушении Эшли Мэдисон. Они все еще успешно подписались, и никто, кто был в нарушении, не пропустил, когда им сказали, что они там, но те, кто не получил себя, ошиблись. У меня был Raygun сходите с ума от меня, поэтому я исправил это и нажал быстро, но это означало, что 0,7% запросов имели ошибку в час, который охватывает точка данных. Вот более репрезентативный график частоты появления ошибок за самый загруженный период:
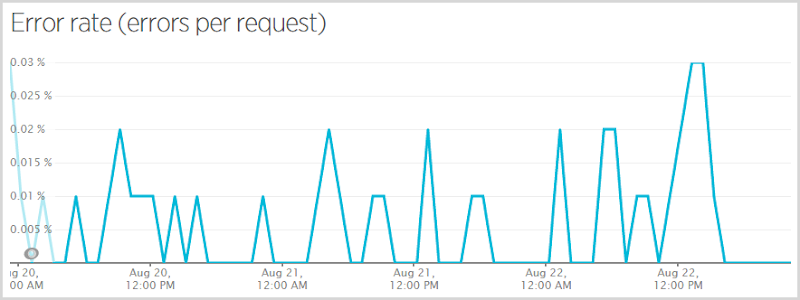
Это все еще трехдневный период, но он пропускает среду и только четверг, пятницу и субботу. Это работает с частотой ошибок 0,0052% (по какой-то причине New Relic дает мне только эту цифру на меньшем графике на первой странице) или, другими словами, 99,9948% запросов были выполнены успешно. Итак, что же было неудачным? Вот так:
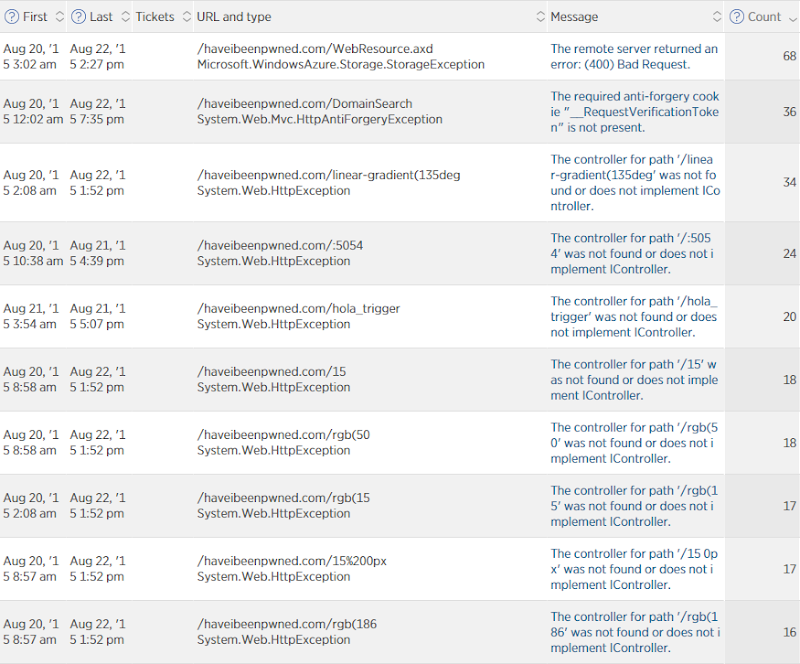
Это преимущественно не связанные с пользователем ошибки. WebResource.axd предназначен для автоматической регистрации нарушений политики безопасности контента с использованием NWebsec (кстати, мой курс по Pluralsight на этом Он был запущен в середине всего хаоса!), и это иногда терпит неудачу, когда очень большие нарушения не помещаются в хранилище таблиц (по какой-то причине я иногда вижу там большие URI данных). Существует исключение против подделки, когда люди (или роботы) пытаются выполнить поиск по домену, а не передают токен против подделки (любимый инструмент для сканирования безопасности) и кучу просто совершенно не относящихся к делу ошибок, таких как искаженные запросы к Существующие ресурсы по разным причинам полностью вне моего контроля. Фактически, если вынуть их из процента ошибок, вы получите настолько близкие к 0% фактических ошибок, с которыми сталкиваются пользователи, что они почти идеальны — менее одной фактической ошибки на 100 000 запросов. очень время ожидания хранения таблицы или SQL Azure недоступны для связи. Обратите внимание, что это никоим образом не связано с нагрузкой — иногда я вижу ошибку такого рода только с небольшим количеством людей на сайте. Конечно, я хотел бы получить это, но я в основном счастлив!
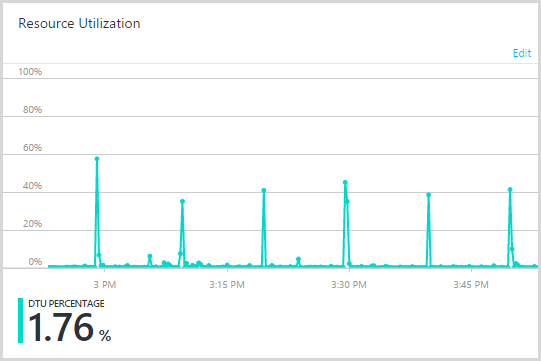
Одна из вещей, которые меня больше всего интересуют, когда появляются серьезные объемы, это то, куда идет нагрузка . Я знаю, где находится объем — он попадает на первую страницу и ищет учетные записи — но где проделывается тяжелая работа? Я обнаружил, что самая большая область, где производительность снижается, это когда люди подписываются на уведомления:
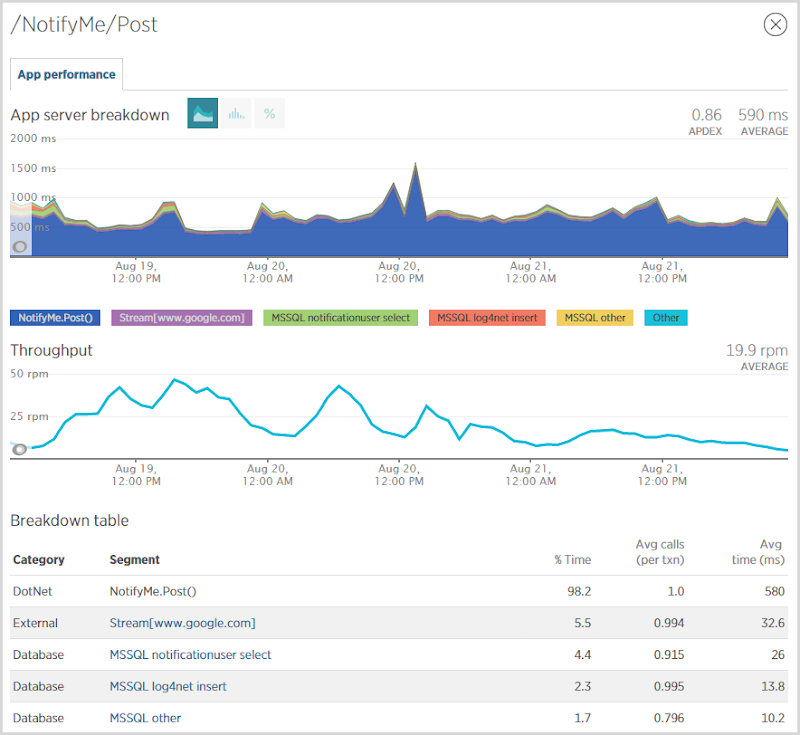
У меня было около 90 тысяч человек, подписавшихся на уведомления за этот период, и, как вы можете видеть на приведенном выше графике, это sloooow. Проблема видна в событии NotifyMe.Post (), которое в среднем занимает 580 мс. Это событие устанавливает прямое соединение с SMTP-сервером Mandrill для отправки подтверждающего письма, что крайне неэффективно. Что я действительно должен делать, так это помещать его в очередь сообщений, посылать немедленный ответ пользователю, а затем использовать WebJob в качестве фонового процесса для отправки электронного письма через несколько секунд. Это остановит доставку почты, блокируя ответ, поэтому пользователь, вероятно, вернет себе полсекунды. С другой стороны,если я использую WebJob для фактической отправки почты, то она по-прежнему выполняется на веб-сервере, поэтому, хотя мне бы хотелось иметь возможность аргументировать повышенную масштабируемость системы, я просто перетасовываю то же самое нагрузка между различными процессами, работающими в одной и той же инфраструктуре. Конечно, существует гибкость, связываясь с хранилищем в Azure, а не с почтовым сервером где-то совершенно другим, но я бы не стал возвращать циклы ЦП, если бы не распространил WebJob на другую инфраструктуру.но я бы не стал возвращать циклы процессора, если бы не распространил WebJob на другую инфраструктуру.но я бы не стал возвращать циклы процессора, если бы не распространил WebJob на другую инфраструктуру.
В конце системы вот что я видел в базе данных:
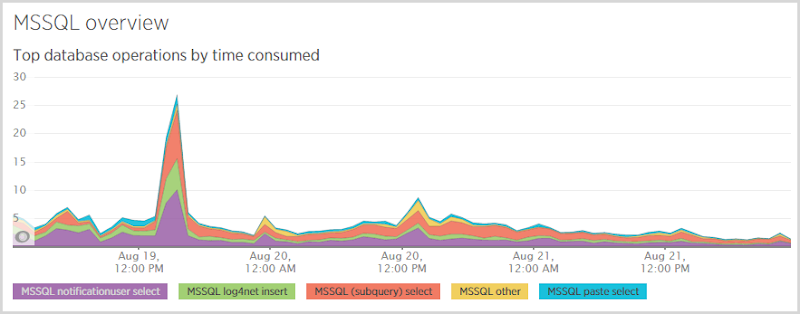
Большое преимущество здесь — это «выбор пользователя уведомления»; когда кто-то подписывается на уведомления, я сначала проверяю, есть ли они в базе данных, поэтому я знаю, отправлять ли им электронное письмо «Эй, вы уже подписаны» или «Вот ваш проверочный токен». Мне также нужно выбрать из этой таблицы после того, как они перейдут по ссылке подтверждения, которая возвращает их запись по токену. Эти выборы дорогие, и вы видите, что они снова представлены во времени отклика базы данных:
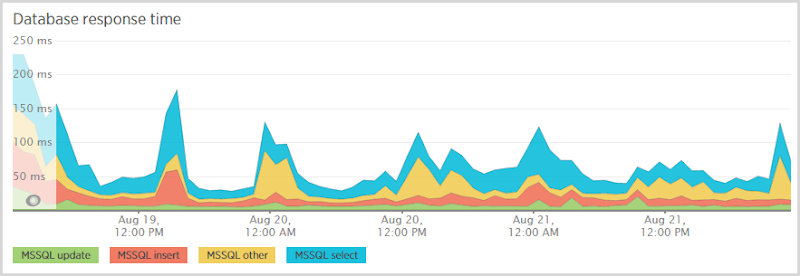
Теперь за этот период я несколько раз менял масштаб базы данных SQL (подробнее об этом позже), поэтому я ожидаю некоторые колебания, но, очевидно, выбор по-прежнему составляет львиную долю расходов. Мне нужно взглянуть на эту таблицу поближе и посмотреть, что происходит с индексами. Они созданы для запросов как по электронной почте, так и по токену, но для таблицы, содержащей около 250 тыс. Строк, все должно работать быстрее, чем это.
Одна интересная статистика, которую я получил в связи с этим, заключалась в распределении запросов на выборку в таблицу уведомлений по вызывающей стороне:
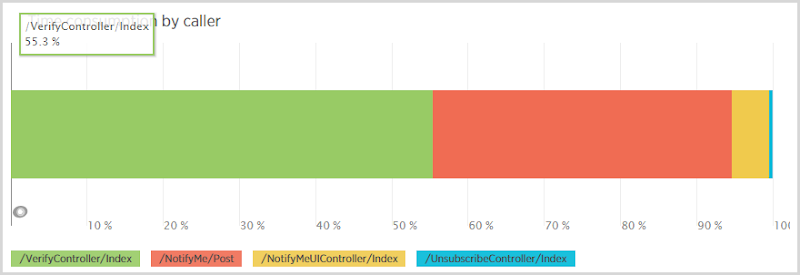
Теперь продумайте рабочий процесс здесь: кто-то делает сообщение на контроллере NotifyMe, чтобы подписаться на уведомления, а затем 80% времени они возвращаются и нажимают VerifyController после того, как они получают электронное письмо (существует 20% -ная степень истощения, которую я предполагаю, либо не получение электронной почты или людей, подписывающих другие адреса). Дело в том, что должно быть намного больше вызовов от регистрации (вызывающего «/ NotifyMe / Post»), чем для проверки, но проверка потребляет 55% всех выборок из таблицы уведомлений пользователей. Почему это?
Я обнаружил проблему в некотором неоптимальном коде, который сначала извлекает пользователя по токену, чтобы я мог видеть, является ли токен действительным и уже проверен, или нет, тогда он делает это:
public void VerifyUser(int id)
{
var notificationUser = _db.NotificationUsers.Single(n => n.Id == id);
notificationUser.IsVerified = true;
notificationUser.VerificationDate = DateTime.UtcNow;
_db.SaveChanges();
}Это очень типичный шаблон Entity Framework, но он неэффективен, так как сначала извлекает запись из базы данных одним запросом (так что теперь выполняет два запроса на выборку при проверке), затем обновляет атрибуты IsVerified и VerificationDate перед выполнением обновления с исправленной сущностью. Это тот случай, когда проще было бы на самом деле лучше, и я должен просто поразить его оператором обновления внутри ExecuteSqlCommand . На самом деле мне, вероятно, даже не нужно делать выбор, чтобы посмотреть, является ли токен первым, я мог просто вернуть значение обратно из оператора обновления, указывающее, была ли строка обновлена (токен существует) или нет (токен недействителен ). Честно говоря, в большинстве случаев это даже не имеет значения, но по мере масштабирования эти дополнительные запросы начинают сказываться на инфраструктуре.
Другой интересный образец базы данных, который я видел, был этот:
Эти пики были расположены на расстоянии 10 минут друг от друга, так что явно был процесс, вызывающий нагрузку на циклической основе. Сначала я задавался вопросом, был ли где-то внешний игрок, который ударил ресурс, который забивал базу данных, затем я вспомнил службу напоминания о проверке …, которая работает с 10-минутными интервалами. Это WebJob, который каждые 10 минут заходит в базу данных и проверяет, есть ли ожидающие подтверждения подписки, которым не менее трех дней. Как я упоминал ранее, только около 80% регистраций фактически заканчивают проверку своего адреса электронной почты, а оставшиеся 20% теряются в фильтрах спама или случайно удаляются или что-то еще. Позже сервис напоминаний отправляет электронное письмо «Эй, вы зарегистрировались, но никогда не проверяли». Очевидно, что запрос на извлечение этих данных теперь заострял DTU.
Я подозреваю, что это происходило потому, что прошло примерно три дня с момента первоначальной большой нагрузки и из-за огромного увеличения числа регистраций, запросы извлекали гораздо больше данных из гораздо большей таблицы. Я также обнаружил, что таблица не была особенно хорошо оптимизирована; Я выбирал пользователя уведомлений с запросом, чтобы выяснить, были ли они активны, были ли они проверены, были ли им отправлены напоминания и зарегистрировались ли они более трех дней назад. У меня не было подходящего индекса для этого запроса, и я собирал их один за другим, что не проблема, когда вы говорите о нормальных объемах, но, очевидно , проблема, когда вещи становятся большими. Ладно, это все еще фоновый процесс, поэтому длительность процесса напоминания не блокирует ответы пользователя напрямую, но все равно вызывает активность базы данных, которая может негативно повлиять на другие запросы.
Кстати, у меня был действительно хороший доступ ко всей этой информации, потому что мой портал Azure выглядит так:
Я настроил свою собственную панель инструментов, чтобы все, что мне нужно, было в одном месте. Ознакомьтесь с этой статьей об улучшениях портала Azure, чтобы узнать, как это сделать, и я настоятельно рекомендую всем, кто использует Azure, делать то же самое. Это невероятно мощный инструмент, который действительно позволяет вам контролировать происходящее.
Пока я работаю с инструментальными панелями и информацией, я держал окно Chrome с абсолютно всем необходимым для мониторинга жизненно важных функций на разных вкладках:
Google Analytics с номерами трафика в реальном времени, New Relic с статистикой производительности, Raygun с ошибками, Azure с облачными фигурами и Mandrill для доставки электронной почты. Возможность быстро увидеть, что происходит в приложении и инфраструктуре, была абсолютно бесценна. Говоря об инфраструктуре …
В прошлом я писал о том, как я настраивал Azure для масштабирования инфраструктуры веб-сервера, и, как и следовало ожидать, я использовал довольно много из них за этот период:
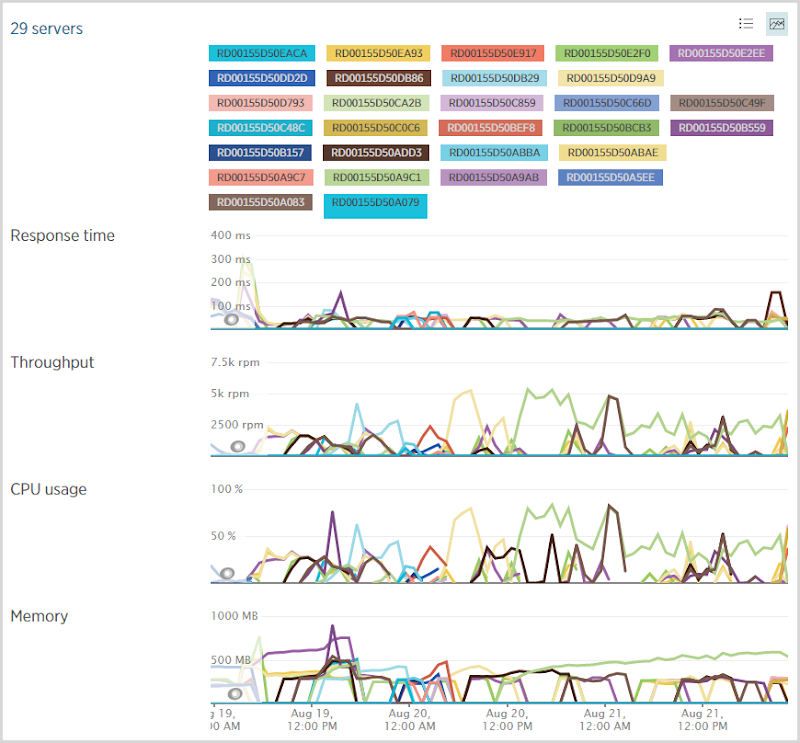
В обычных условиях я запускаю средний экземпляр веб-сайта Azure, который затем масштабируется до нескольких экземпляров по мере необходимости. Перед тем, как лечь спать в среду вечером, я увеличил масштаб и не переставил его обратно до субботнего вечера. Это дало мне гораздо больше возможностей для роста (примерно вдвое больше, чем у среднего экземпляра), и, конечно, когда вы смотрите на некоторые кластеры серверов, возможно, он немного стесняется со средними экземплярами. Тем не менее, я не совсем уверен, что мои пороги масштабирования идеальны, так как кажется, что количество серверов немного местами. Например, вот количество серверов на портале Azure:
Эти пики не полностью соответствуют объемам трафика, и этому есть несколько причин. Во-первых, трафик не является трафиком; различные шаблоны запросов действительно меняют нагрузку. Например, множество обращений к API подчеркивает различные части системы множеством обращений к изображениям или CSS. Еще одна вещь, которую нужно помнить, это то, что у меня в фоновом режиме работает куча веб-заданий . Они увеличиваются независимо от трафика на сайт, и они работали сверхурочно рано утром в четверг, когда вы видите 10 серверов, работающих одновременно. Фактически я вручную уменьшил до 10, чтобы еще больше распараллелить задания, и как только я вернулся к автоматическому масштабированию, он остановился на 4 больших экземплярах, давай или бери.
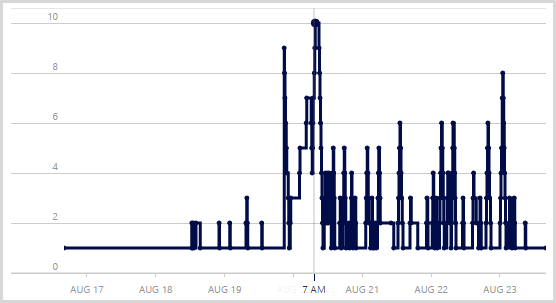
Правила автоматического масштабирования, которые я сейчас использую, выглядят так:
Я обнаружил, что масштабирование только на процессоре, которое у меня было изначально, не было достаточно ранним. Все это было сделано много недель назад, так как API применялся довольно часто, и я заметил, что один средний экземпляр сохранил фиксированную скорость около 8 тыс. Об / мин. Я бы вручную добавил еще один экземпляр, и число оборотов в минуту увеличилось бы. Я обнаружил, что загрузка не вызывает масштабирования через ЦП, но длина очереди HTTP увеличивается, и это становится метрикой, которая запускает масштабирование. Я теперь немного подозрительным , что очередь мера длины может быть причиной масштабироваться то мера CPU вызывает масштаб в ближайшее время после того, таким образом , вызывая , что йо-йо. Я могу уменьшить минимальный порог ЦП для уменьшения количества экземпляров, чтобы это исправить.
Это по общему признанию довольно агрессивный масштабный профиль. У меня всегда было больше энергии, чем мне было нужно, и приведенные выше показатели подтверждают это. Все это, конечно, заставляет людей задуматься — сколько это мне стоило ?! Давайте узнаем!
Вот все, что связано с биллинговой системой Azure. Я собираюсь объяснить каждый график, а затем изобразить затраты по рыночным ставкам. Я сделаю это для этого цикла выставления счетов, который проходит с 13 августа до момента захвата этих графиков 23 августа, и он охватывает безумный период и примерно неделю до этого. Имейте в виду, что эти даты — время в США, поэтому, если это PST, то это на 17 часов больше, чем другие даты, на которые я ссылался. Это не влияет на цифры, но вы увидите, что время немного отличается от приведенных выше графиков.
Я потратил 424,33 часа на сервис приложений среднего масштаба.
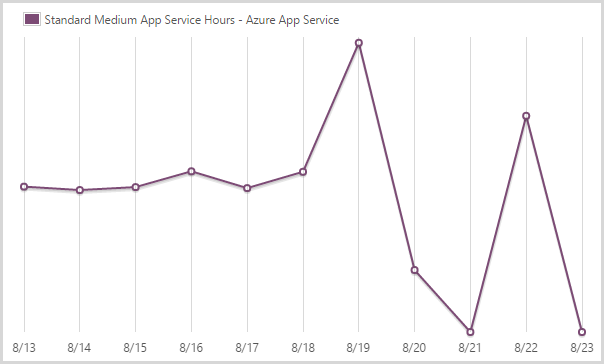
The Azure app service is what you might previously have known as the website service. You can see how it’s pretty steady until the scale out starts to happen. It then goes way down as I resort to only large instances. I go back to medium once the load dies off and the final day in the chart simply doesn’t have any data to register.
I consumed 155.64 hours of a large scale app service.
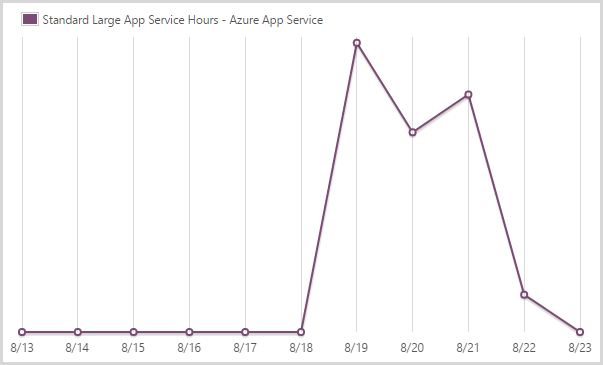
This graph is sort of the inverse of the medium instances because it’s large when it’s not medium and medium when it’s not large and, well, you get the idea. I’m done with large now, unless things go nuts again…
I sent out 16.13GB from the app service in zone 1.
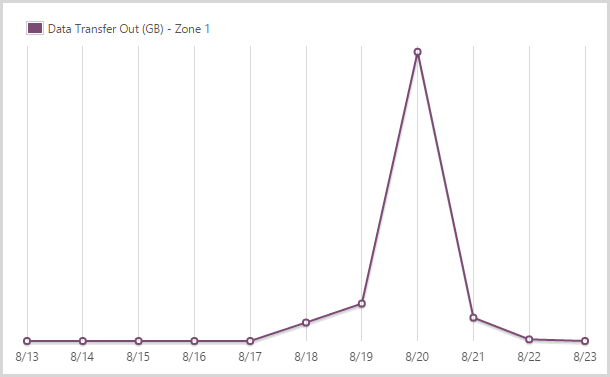
Azure has a tiered egress data charging model which effectively means you pay different amounts depending on where you’re hosting your data. HIBP is in the West US data centre (it’s closest to the most people who use it) and that also happens to be the cheapest. You get the first 5GB free and ingress data (anything sent to the site) is free.
I sent out 122.9GB from the CDN service in zone 1.
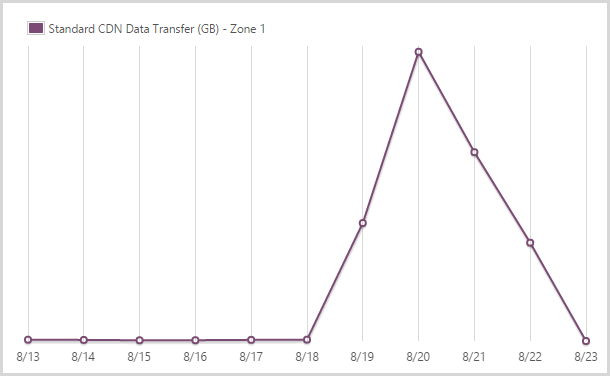
I use the Azure CDN service for hosting the logos of the pwned site. You pay more for the CDN when it comes out of another zone but it’s also faster as it obviously means distributing the content across the globe. I’m happy to pay for that – I optimise the bejesus out of everything that goes in there and it makes things a heap faster so IMHO, it’s worthwhile.
I sent out 9.99GB from the CDN service in zone 2.
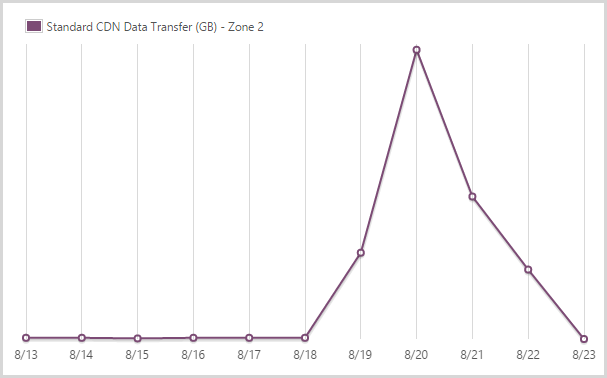
And this is the other zone – it’s a 59% price markup on zone 1 but obviously Microsoft gets hit with different data costs in different locations so that’s fair enough. The figure is much smaller because the traffic was very predominantly driven by US audiences.
I stored 39.62GB in geo redundant table and queue storage.
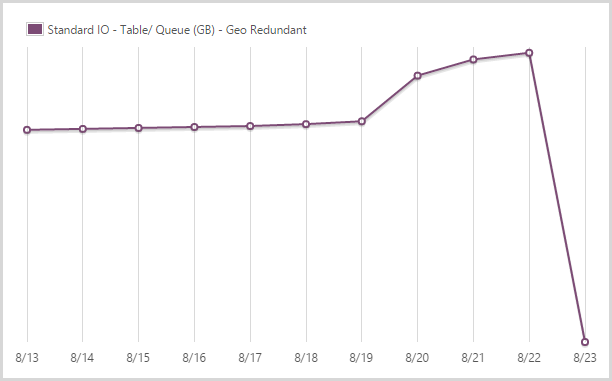
I’ve written extensively about my love of table storage in the past and it performed fantastically during this period. I store all the data that is searched when people hit the site in table storage plus things like my CSP violation reports as well. Queue storage is then used extensively for other processes, particularly in conjunction with the WebJobs. I pay extra for geo redundant storage so that I have a copy in another location should there be a Godzilla event.
I committed 241,702,400 storage transactions.
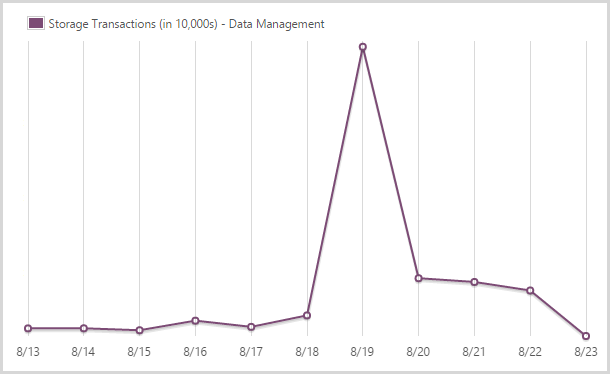
Yes – nearly a quarter of a billion! You also pay for transactions in table storage. There’s a massive spike here as I loaded the Ashley Madison data because the process can result in multiple hits for a single record (i.e. it already exists so I have to pull it, update it then put it back in).
I used 43.96 days of a standard S0 SQL database.
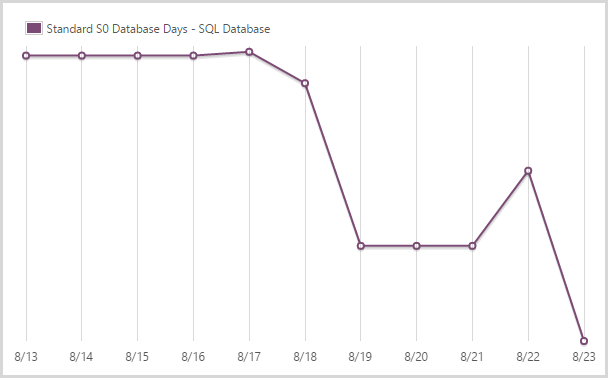
This is the level the SQL database service normally runs at which is your entry level standard database as a service. It’s actually not a fair graph because I have other S0 databases on the account too, not just the one behind HIBP. That’ll inflate the figures a bit, but not by too much. Note how the graph drops off pretty quickly – I scaled the DB up when I loaded the Ashley Madison data because it gets maxed out for a period during the load period (I still use an RDBMS during the load of the data).
I used 1.92 days of a standard S1 SQL database.
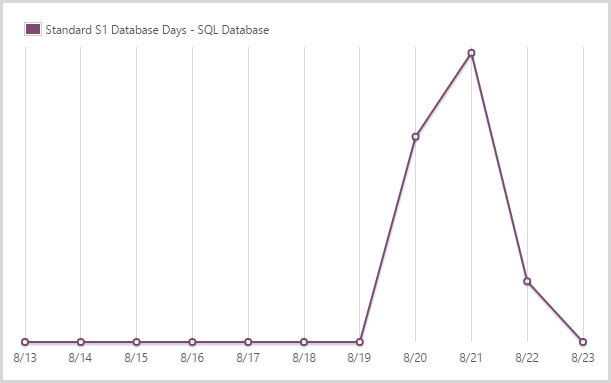
After the initial crazy period and once I saw the DTUs pretty much flat-lining (SQL is only regularly hit when someone subscribes for notifications), I scaled back to an S1. This is only 20% of the DTUs of the S3 you’ll see in the next graph, but with next to no load it was clear I could back it way off, I just left a little bit of insurance by not going all the way back to S0.
I used 1.46 days of a standard S3 SQL database.
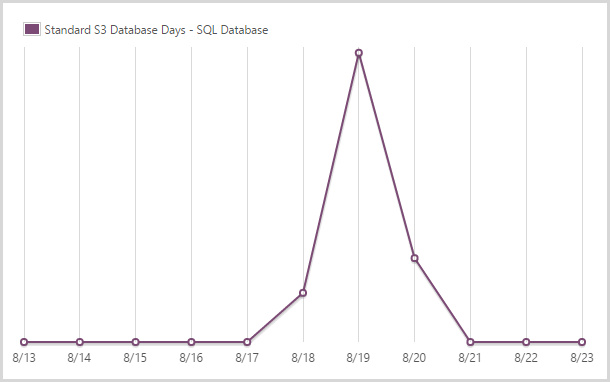
And here’s the spike that fills the gap in amidst the S0 and S1 DBs.
So what do you reckon this all cost me? How far out of pocket did this exercise leave me? I’ll be honest and say that during the event, it was all “scale first and ask questions later” and I did have just an inkling of an uncomfortable feeling that I was going to turn around and see $1k or more of costs, particularly running large instances that would scale out to 10 machines. How would I explain away my long held position of paying less for Azure than what I do for coffee?!
So here it is – the whole set of costs:
|
Service |
Units |
Cost per unit |
Total |
|
Standard medium app service (hours) |
424.22 |
$0.15 |
$63.63 |
|
Standard large app service (hours) |
155.64 |
$0.30 |
$46.69 |
|
App service data transfer out, zone 1 (GB) |
16.13 |
$0.087 |
$1.40 |
|
CDN service data transfer out, zone 1 (GB) |
122.90 |
$0.087 |
$10.69 |
|
CDN service data transfer out, zone 2 (GB) |
9.99 |
$0.138 |
$1.38 |
|
Geo redundant table and queue storage (GB) |
39.62 |
$0.095 |
$3.76 |
|
Storage transactions (per 10,000) |
2,417.024 |
$0.0036 |
$8.70 |
|
Standard S0 SQL database (days) |
43.96 |
$0.4848 |
$21.31 |
|
Standard S1 SQL database (days) |
1.92 |
$2.4192 |
$4.64 |
|
Standard S2 SQL database (days) |
1.46 |
$4.8384 |
$7.06 |
|
$169.29 |
Except the Ashley Madison event didn’t cost me that much because the figure includes all the services I would have normally been paying for over the 10 day period the billing covers anyway. Truth be told, the entire episode cost me about $130 for Azure to serve 3M pages to 1.5M users. Actually, because I’m aiming for full transparency, there were also some costs from Mandrill for sending rather a large number of emails:
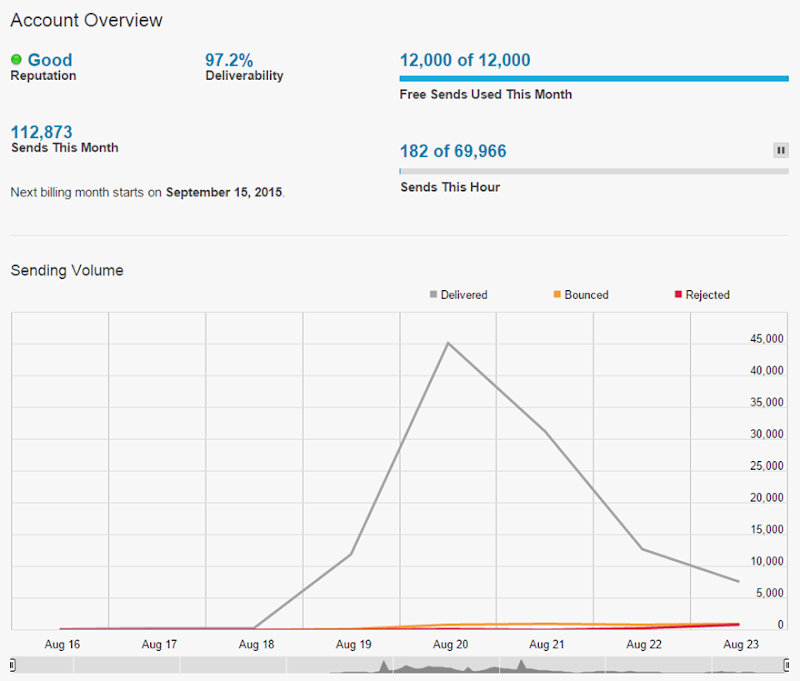
With 12k monthly sends for free, I usually don’t go into paid territory. When I do though, it’s a whole 20c per thousand emails and my account automatically tops up after every $5 of spend so I got three billsfrom Mandrill for a grand total of $15! So probably about $145 all up.
Let me just leave you with one more thing: here’s the stats for the full week, so this is Monday 17 through Sunday 23 inclusive:
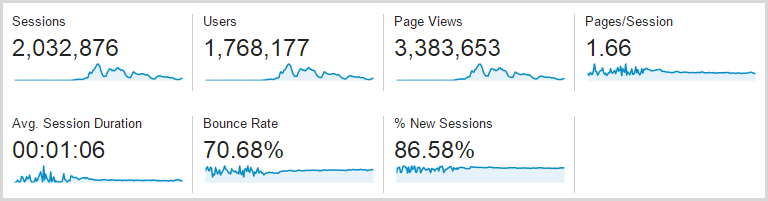
That’s a lot – well over 3 million page views – but of course the devil is in the detail and it comes back to that first graph which shows how intensive the traffic was around Thursday onwards. The real story is that this is a four day traffic spread because the first three days were almost flat, comparatively speaking. Oh – and as per the earlier comment, it’s Google Analytics so what another 20% on top of that and you’re looking at 4 million page views over three days.
But here’s what I really want to show and how I want to end the analysis: the uptime:
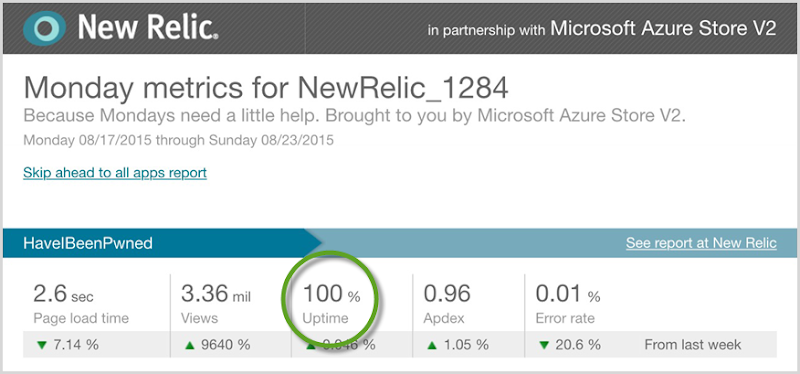
I always like to strive to improve things, but the uptime is one attribute I won’t ever be exceeding. Over those three crazy days, HIBP on Azure served 4M page views to up to 10k simultaneous users querying 220M records at an average of 41ms whilst costing me $130 for 100.00% uptime!
A totally tangential story for a moment: this all blew up while I was on a snow holiday with my family:

Now there was no way I was going to miss out on any snow time so each time my son and I got back on the chairlift, I’d whip out the iPhone and fire up an RDP session to the VM I use to manage everything from:
How freakin’ awesome is this: I’m riding up the mountain on the other side of the world whilst tuning the scale of virtual infrastructure supporting millions of visitors searching across hundreds of millions of records. If only lift tickets were as cheap as running large scale web applications on Azure…