 В большинстве проектов по разработке программного обеспечения есть момент, когда приложение должно начать взаимодействовать с другими приложениями или сторонними компонентами.
В большинстве проектов по разработке программного обеспечения есть момент, когда приложение должно начать взаимодействовать с другими приложениями или сторонними компонентами.
Будь то отправка уведомления по электронной почте, вызов внешнего API, запись в файл или перенос данных из одного места в другое, вы либо развертываете собственное решение, либо используете существующую среду.
Что касается существующих сред в экосистеме Java, на одном конце спектра мы находим TIBCO BusinessWorks и Mule ESB , а на другом конце — Spring Integration и Apache Camel .
В этом уроке я собираюсь познакомить вас с Apache Camel с помощью примера приложения, которое считывает твиты из примера ленты Twitter и индексирует эти твиты в реальном времени с помощью ElasticSearch .
Что такое Apache Camel?
Интеграция приложения с внутренними или внешними компонентами в экосистеме является одной из самых сложных задач в разработке программного обеспечения, и если она не сделана правильно, это может привести к огромному беспорядку и реальной боли в обслуживании в долгосрочной перспективе.
К счастью, Camel — интегрированная среда с открытым исходным кодом, размещенная в Apache, — основана на корпоративных шаблонах интеграции, и эти шаблоны могут помочь в написании более удобочитаемого и обслуживаемого кода. Как и в случае с Lego, эти шаблоны можно использовать в качестве строительных блоков для создания надежного программного проекта.
Apache Camel также поддерживает широкий спектр коннекторов для интеграции вашего приложения с различными платформами и технологиями. И, кстати, он также прекрасно сочетается с Spring .
Если вы не знакомы с Spring, вам может пригодиться этот пост: Обработка ленты Twitter с использованием Spring Boot .
В следующих разделах мы рассмотрим пример приложения, в котором Camel интегрирован как с примером канала Twitter, так и с ElasticSearch.
Что такое ElasticSearch?
ElasticSearch, похожий на Apache Solr, представляет собой высоко масштабируемую систему полнотекстового поиска с открытым исходным кодом на основе Java, построенную на основе Apache Lucene .
В этом примере приложения мы собираемся использовать ElasticSearch для индексирования твитов в режиме реального времени, а также для обеспечения полнотекстового поиска по этим твитам.
Другие используемые технологии
Помимо Apache Camel и ElasticSearch, я также включил в это приложение и другие фреймворки: Gradle в качестве инструмента сборки, Spring Boot в качестве фреймворка веб-приложения и Twitter4j для чтения твитов из примера фида Twitter.
Начиная
Скелет проекта был создан по адресу http://start.spring.io, где я проверил параметр веб-зависимости, заполнил раздел «Метаданные проекта» и выбрал «Gradle Project» в качестве типа проекта.
После того, как проект создан, вы можете загрузить и импортировать его в свою любимую среду IDE. Сейчас я не буду вдаваться в подробности о Gradle, но вот список всех зависимостей в файле build.gradle :
def camelVersion = '2.15.2'
dependencies {
compile("org.springframework.boot:spring-boot-starter-web")
compile("org.apache.camel:camel-core:${camelVersion}")
compile("org.apache.camel:camel-spring-boot:${camelVersion}")
compile("org.apache.camel:camel-twitter:${camelVersion}")
compile("org.apache.camel:camel-elasticsearch:${camelVersion}")
compile("org.apache.camel:camel-jackson:${camelVersion}")
compile("joda-time:joda-time:2.8.2")
testCompile("org.springframework.boot:spring-boot-starter-test")
}Интеграция по верблюжьим маршрутам
Camel imlements в Сообщение- ориентированной архитектуры , и это основные строительные блоки Маршруты , которые описывают поток сообщений.
Routes can be described in either XML (old way) or its Java DSL (new way). We’re only going to discuss the Java DSL in this post as that’s the prefered and more elegant option.
All right, let’s look at a simple Route then:
from("file://orders").
convertBodyTo(String.class).
to("log:com.mycompany.order?level=DEBUG").
to("jms:topic:OrdersTopic");There are a few things to note here:
- Messages flow between endpoints which are represented by and configured using URIs
- A Route can only have a single message producer endpoint (in this case
file://orderswhich reads files from the orders folder) and multiple message consumer endpoints:log:com.mycompany.order?level=DEBUGwhich logs the content of a file in a debug message under com.mycompany.order logging categoryjms:topic:OrdersTopicwhich writes the content of the file into a JMS topic
- In between endpoints the messages can be altered, i.e.
convertBodyTo(String.class)which converts the message body to a String.
Also note that the same URI can be used for a consumer endpoint in one route and a producer endpoint in another:
from("file://orders").
convertBodyTo(String.class).
to("direct:orders");
from("direct:orders).
to("log:com.mycompany.order?level=DEBUG").
to("jms:topic:OrdersTopic");The direct endpoint is one of the generic endpoints and it allows passing messages synchronously from one route to another.
This helps creating readable code and reusing routes in multiple places in the code.
Indexing Tweets
Now let’s take a look at some routes from our code. Let’s start with something simple:
private String ES_TWEET_INDEXER_ENDPOINT = "direct:tweet-indexer-ES";
...
from("twitter://streaming/sample?type=EVENT&consumerKey={{twitter4j.oauth.consumerKey}}&consumerSecret={{twitter4j.oauth.consumerSecret}}&accessToken={{twitter4j.oauth.accessToken}}&accessTokenSecret={{twitter4j.oauth.accessTokenSecret}}")
.to(ES_TWEET_INDEXER_ENDPOINT)
;This is so simple, right? By now you may have figured that this route reads tweets from the Twitter sample feed and passes them to the direct:tweet-indexer-ES endpoint. Note that the consumerKey, consumerSecret, etc. are configured and passed in as system properties (see http://twitter4j.org/en/configuration.html).
Now let’s look at a slightly more complex route that reads from the direct:tweet-indexer-ES endpoint and inserts Tweets to ElasticSearch in batches (see comments for detailed explanation on each step):
@Value("${elasticsearch.tweet.uri}")
private String elasticsearchTweetUri;
...
from(ES_TWEET_INDEXER_ENDPOINT)
// groups tweets into separate indexes on a weekly basis to make it easier clean up old tweets:
.process(new WeeklyIndexNameHeaderUpdater(ES_TWEET_INDEX_TYPE))
// converts Twitter4j Tweet object into an elasticsearch document represented by a Map:
.process(new ElasticSearchTweetConverter())
// collects tweets into weekly batches based on index name:
.aggregate(header("indexName"), new ListAggregationStrategy())
// creates new batches every 2 seconds
.completionInterval(2000)
// makes sure the last batch will be processed before the application shuts down:
.forceCompletionOnStop()
// inserts a batch of tweets to elasticsearch:
.to(elasticsearchTweetUri)
.log("Uploaded documents to ElasticSearch index ${headers.indexName}: ${body.size()}")
;Notes on this Route:
elasticsearchTweetUriis a field whose value is taken by Spring from theapplication.propertiesfile (elasticsearch.tweet.uri=elasticsearch://tweet-indexer?operation=BULK_INDEX&ip=127.0.0.1&port=9300) and injected into the field- To implement custom processing logic within a route, we can create classes that implement the processor interface. See WeeklyIndexNameHeaderUpdater and ElasticSearchTweetConverter.
- The tweets are aggregated using the custom ListAggregationStrategy strategy which aggregates messages into an ArrayList and which will be later on passed on to the next endpoint every 2 seconds (or when the application stops).
- Camel implements an Expression Language that we’re using to log the size of the batch (
${body.size()}) and the name of the index (${headers.indexName}) where messages were inserted from.
Searching Tweets in Elasticsearch
Now that we have tweets indexed in ElasticSearch, it’s time to run some search on them.
First let’s look at the Route that receives a search query and the maxSize param that limits the number of search results:
public static final String TWEET_SEARCH_URI = "vm:tweetSearch";
...
from(TWEET_SEARCH_URI)
.setHeader("CamelFileName", simple("tweet-${body}-${header.maxSize}-${date:now:yyyyMMddHHmmss}.txt"))
// calls the search() method of the esTweetService which returns an iterator
// to process search result - better than keeping the whole resultset in memory:
.split(method(esTweetService, "search"))
// converts Elasticsearch doucment to Map object:
.process(new ElasticSearchSearchHitConverter())
// serializes the Map object to JSON:
.marshal(new JacksonDataFormat())
// appends new line at the end of every tweet
.setBody(simple("${body}\n"))
// write search results as json into a file under /tmp folder:
.to("file:/tmp?fileExist=Append")
.end()
.log("Wrote search results to /tmp/${headers.CamelFileName}")
;This route will be triggered when a message is passed to the vm:tweetSearch endpoint (which uses an in-memory queue to process messages asynchronously).
The SearchController class implements a REST API allowing users to run a tweet search by sending a message to the vm:tweetSearch endpoint using Camel’s ProducerTemplate class:
@Autowired
private ProducerTemplate producerTemplate;
@RequestMapping(value = "/tweet/search", method = { RequestMethod.GET, RequestMethod.POST },
produces = MediaType.TEXT_PLAIN_VALUE)
@ResponseBody
public String tweetSearch(@RequestParam("q") String query,
@RequestParam(value = "max") int maxSize) {
LOG.info("Tweet search request received with query: {} and max: {}", query, maxSize);
Map<String, Object> headers = new HashMap<String, Object>();
// "content" is the field in the Elasticsearch index that we'll be querying:
headers.put("queryField", "content");
headers.put("maxSize", maxSize);
producerTemplate.asyncRequestBodyAndHeaders(CamelRouter.TWEET_SEARCH_URI, query, headers);
return "Request is queued";
}This will trigger the execution of the ElasticSearch, however the result is not returned in the response but written to a file in the /tmp folder (as discussed earlier).
This Route uses the ElasticSearchService class to search tweets in ElasticSearch. When this route is executed, Camel calls the search() method and passes in the search query and the maxSize as input parameters:
public SearchHitIterator search(@Body String query, @Header(value = "queryField") String queryField, @Header(value = "maxSize") int maxSize) {
boolean scroll = maxSize > batchSize;
LOG.info("Executing {} on index type: '{}' with query: '{}' and max: {}", scroll ? "scan & scroll" : "search", indexType, query, maxSize);
QueryBuilder qb = termQuery(queryField, query);
long startTime = System.currentTimeMillis();
SearchResponse response = scroll ? prepareSearchForScroll(maxSize, qb) : prepareSearchForRegular(maxSize, qb);
return new SearchHitIterator(client, response, scroll, maxSize, KEEP_ALIVE_MILLIS, startTime);
}Note that depending on maxSize and batchSize, the code either executes a regular search that returns a single page of results, or executes a scroll request which allows us to retrieve a large number of results. In the case of scrolling, SearchHitIterator will make subsequent calls to ElasticSearch to retrieve the results in batches.
Installing ElasticSearch
- Download ElasticSearch from https://www.elastic.co/downloads/elasticsearch.
- Install it to a local folder (
$ES_HOME) - Edit
$ES_HOME/config/elasticsearch.ymland add this line:cluster.name: tweet-indexer - Install the BigDesk plugin to monitor ElasticSearch:
$ES_HOME/bin/plugin -install lukas-vlcek/bigdesk - Run ElasticSearch:
$ES_HOME/bin/elasticsearch.shor$ES_HOME/bin/elasticsearch.bat
These steps will allow you to run a standalone ElasticSearch instance with minimal configuration, but keep in mind that they’re not intended for production use.
Running the Application
This is the entry point to the application and can be run from the command line.
package com.kaviddiss.twittercamel;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}To run the application, either run the Application.main() method from your favorite IDE or execute the below line from the command line:
$GRADLE_HOME/bin/gradlew build && java -jar build/libs/twitter-camel-ingester-0.0.1-SNAPSHOT.jarOnce the application starts up, it will automatically start indexing tweets. Go to http://localhost:9200/_plugin/bigdesk/#cluster to visualize your indexes:
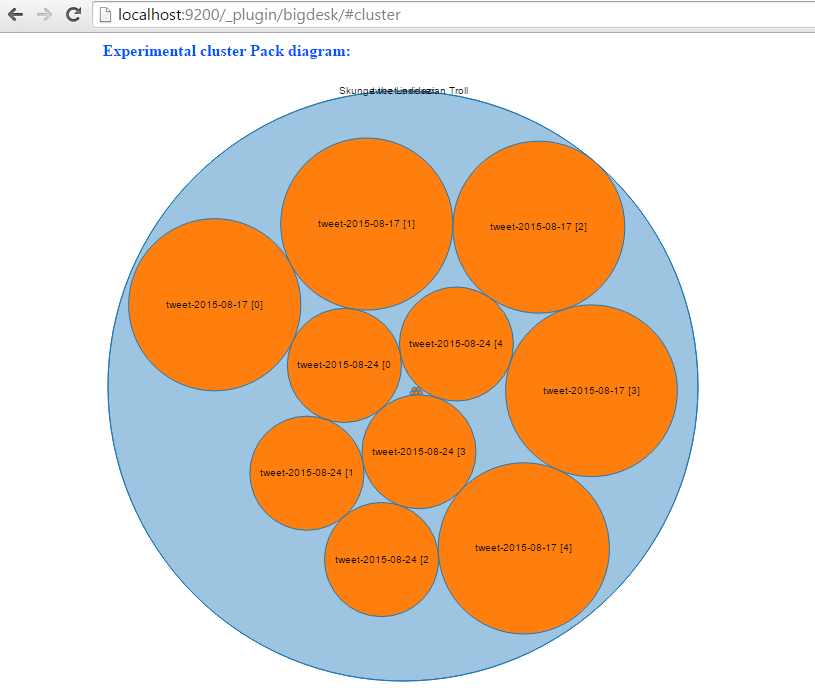
To search tweets, enter a URL something similar to this into the browser: http://localhost:8080/tweet/search?q=toronto&max=100.

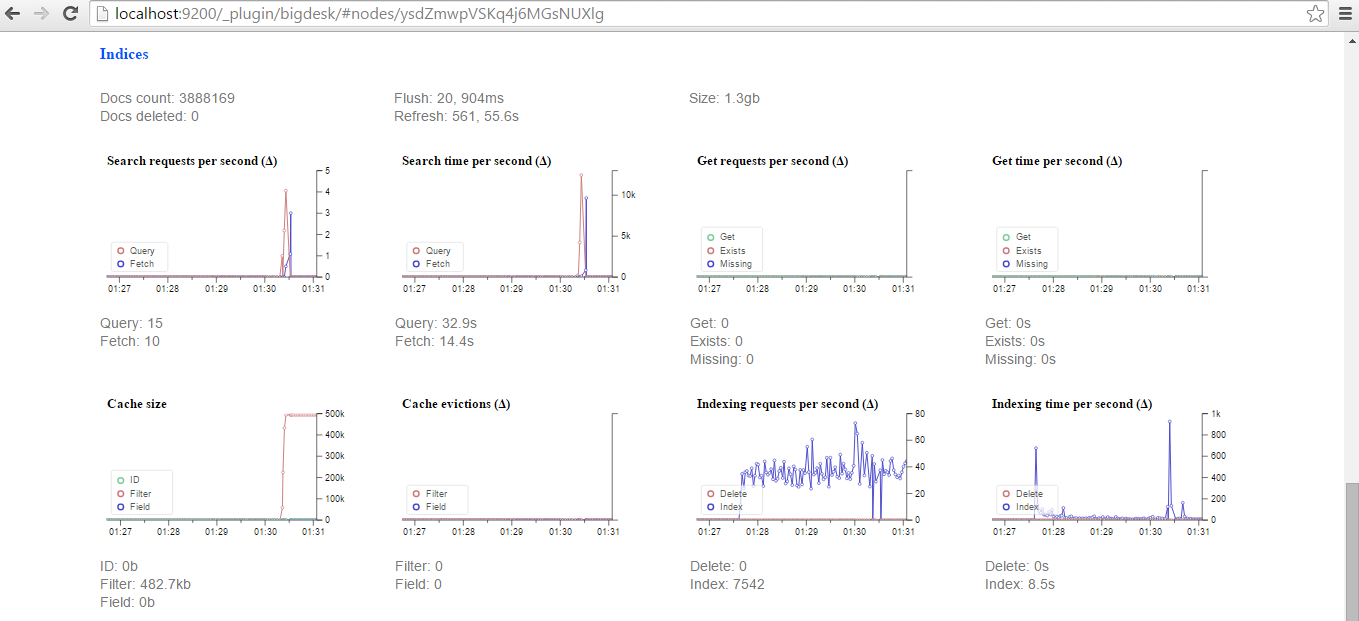
Using the BigDesk plugin, we can monitor how Elasticsearch is indexing tweets:
Conclusion
In this introduction to Apache Camel we covered how to use this integration framework to communicate with external components like Twitter sample feed and ElasticSearch to index and search tweets in real-time.
The source code of the sample application is available at https://github.com/davidkiss/twitter-camel-ingester.
You may also find this post interesting: How to get started with Storm framework in 5 minutes.