При построении конвейеров непрерывной доставки команды часто сталкиваются с проблемой фан-ин.
Фон
Что мы подразумеваем под этим? Диаграмма ниже показывает типичный сценарий. У вас есть несколько компонентов или приложений, которые являются частью системы. Каждый имеет свой собственный конвейер сборки / тестирования. Это также может быть связано с выполнением развертываний и выполнением различных тестов на уровне компонентов.
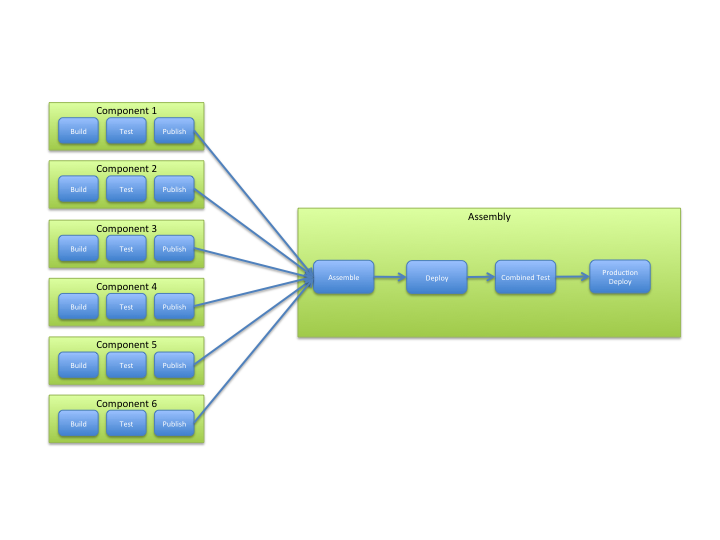
В идеале, ваши принципы архитектуры привели к слабосвязанным компонентам с четко определенными интерфейсами. У вас будет подход, обеспечивающий обратную совместимость интерфейса, или, если вам необходимо внести критические изменения, механизм для создания версий вашего API и поддержки одновременных версий. Это позволит каждому компоненту иметь собственный независимый жизненный цикл, включая производственные развертывания.
Однако иногда это невозможно, и вам необходимо собрать (собрать, если хотите) набор компонентов с определенными версиями и выполнить некоторую форму фазы совокупного / интегрированного тестирования. В одном конкретном взаимодействии с клиентом требовалось постоянно запускать комплект нефункциональных тестов для базового набора компонентов. По мере их обновления базовый уровень необходимо было обновлять, и тесты перезапускались. Работая над этой проблемой, мы разработали реализацию для этого общего шаблона Fan-In. В оставшейся части этой статьи я покажу вам, как создать набор заданий для реализации этого шаблона.
Требования адресованы
- Каждый компонент уже имеет собственный конвейер CI / CD, что приводит к публикации протестированных и версионных артефактов.
- Каждый компонент имеет свою собственную стратегию нумерации версий.
- Общесистемный цикл испытаний займет много часов.
- По завершении цикла испытаний его следует запустить снова.
- В начале каждого теста должны быть развернуты все новые версии компонентов.
- Каждый прогон теста должен иметь аудит версий компонентов, обновленных и включенных в тесты.
Внедрение
Решение реализует требования, используя два задания рабочего процесса:
- Добавить / объединить манифест вакансии.
- Развернуть и проверить работу.
Они показаны на диаграмме ниже, с ключевыми шагами, которые они реализуют:
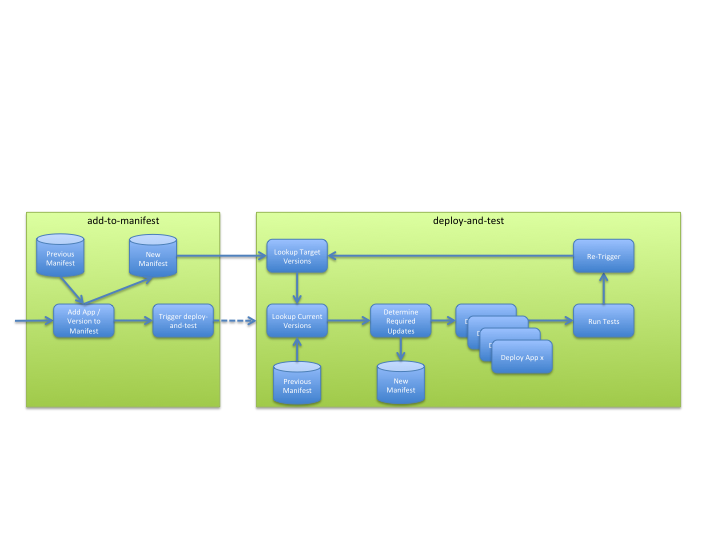
Почему два рабочих места?
Простой ответ «из-за параллелизма».
Более подробный ответ:
- Мы хотим, чтобы все триггеры от вышестоящих компонентов были обработаны — мы не хотим отбрасывать ни один из них.
- Мы должны убедиться, что обновления обрабатываются последовательно.
- Мы должны убедиться, что в манифесте происходит только одно обновление за раз (т.е. синхронизированные записи) — т.е. создать параллелизм 1.
- Нам также необходимо убедиться, что только одна сборка может выполнять либо тест развертывания, либо тест NFT, то есть мы не можем начать повторное развертывание новых версий компонентов во время выполнения NFT.
Мы рассмотрели вопрос о том, будет ли достаточно одного задания рабочего процесса, но ограничение параллелизма рабочего процесса означает, что несколько сборок становятся объединенными, поэтому существует риск отбрасывания некоторых триггеров и связанных с ними параметров, а во-вторых, невозможно обернуть более одного этап в параллельную единицу (хорошо теперь по крайней мере, пока JENKINS-29892 не будет осуществлен).
Добавить / объединить манифест
Давайте начнем с реализации задания Add / Merge Manifest — это тип задания Workflow.
Первая проблема, которую нам необходимо решить, — это где сохранить состояние требуемых версий компонентов, которые необходимо развернуть, то есть манифеста уровня системы или приложения. Был рассмотрен ряд вариантов:
- Хранение версий в файле в SCM.
- Хранение версий в общей файловой системе.
- Хранение версий в файле, связанном со сборкой.
- Взгляд из внешнего хранилища — то есть всегда беру последние «опубликованные» версии.
Мы приняли решение сохранить версии в файле, связанном со сборкой, поскольку это обеспечивает наибольшую переносимость (полагаясь только на самого Дженкинса, а не на внешние системы), но также и на то, чтобы поддерживать историю.
Наша реализация извлекает предыдущий манифест (т.е. из последней успешной сборки), а затем позволяет вносить обновления / дополнения до того, как он будет повторно опубликован как часть сборки.
Давайте посмотрим, как мы реализуем шаги обработки файлов в рабочем процессе.
Получение предыдущего Манифеста:
try {
step 'CopyArtifact', filter: 'manifest', projectName:env.JOB_NAME, selector: [$class: 'StatusBuildSelector', stable: false]])
// Do something with the file
} catch (Exception e) {
echo e.toString()
// Do something to create the first version of the file
}Мы решили взять файл только из последней успешной сборки, чтобы гарантировать, что если задание прекратится и публикация завершится неудачно, мы не потеряем непрерывность.
По завершении обработки обновлений нам нужно опубликовать обновленный манифест:
archive 'manifest'Далее нам нужно фактически прочитать и записать номера версий компонентов из / в манифест. К счастью, Groovy предоставляет несколько простых классов, чтобы справиться с этим. Мы будем использовать класс Properties ().
Если у нас еще нет Manifest (т.е. сценария 1-го запуска), мы определяем новый объект Properties ():
versions = new Properties()В противном случае мы загружаем объект свойств из файла:
def str = readFile 'manifest': file, charset : 'utf-8'
def sr = new StringReader(str)
def props = new Properties()
props.load(sr)Запись файла аналогична, однако из-за ограничений сериализации нам нужно обернуть использование StringWriter в функцию @NonCPS:
writeFile file: 'manifest', text: writeProperties(props)
@NonCPS def writeProperties (props) {
def sw = new StringWriter()
props.store(sw, null)
return sw.toString()
}И затем эта работа выполняет свою основную функцию — получение параметров работы и обновление манифеста:
versions[app]=revisionИ выполнение асинхронного триггера сборки для запуска тестов:
build job: downstreamJob, propagate: false, wait: falseПримечание. Это задание настроено как параметризованная сборка с двумя строковыми параметрами: app и revision. Это задание настроено так, чтобы не выполнять параллельные сборки. Если он запускается одновременно с другими параметрами, то триггеры не будут объединены — несколько сборок будут поставлены в очередь. Это гарантирует, что мы обрабатываем все обновления манифеста по очереди.
Полный исходный код этой работы можно скачать с https://github.com/harniman/workflow-demos/blob/master/fan-in-add-to-manifest.groovy.
Чтобы помочь пониманию, задание было настроено поэтапно, что позволяет четко видеть прогресс в представлении Stage CloudBees Jenkins Platform:
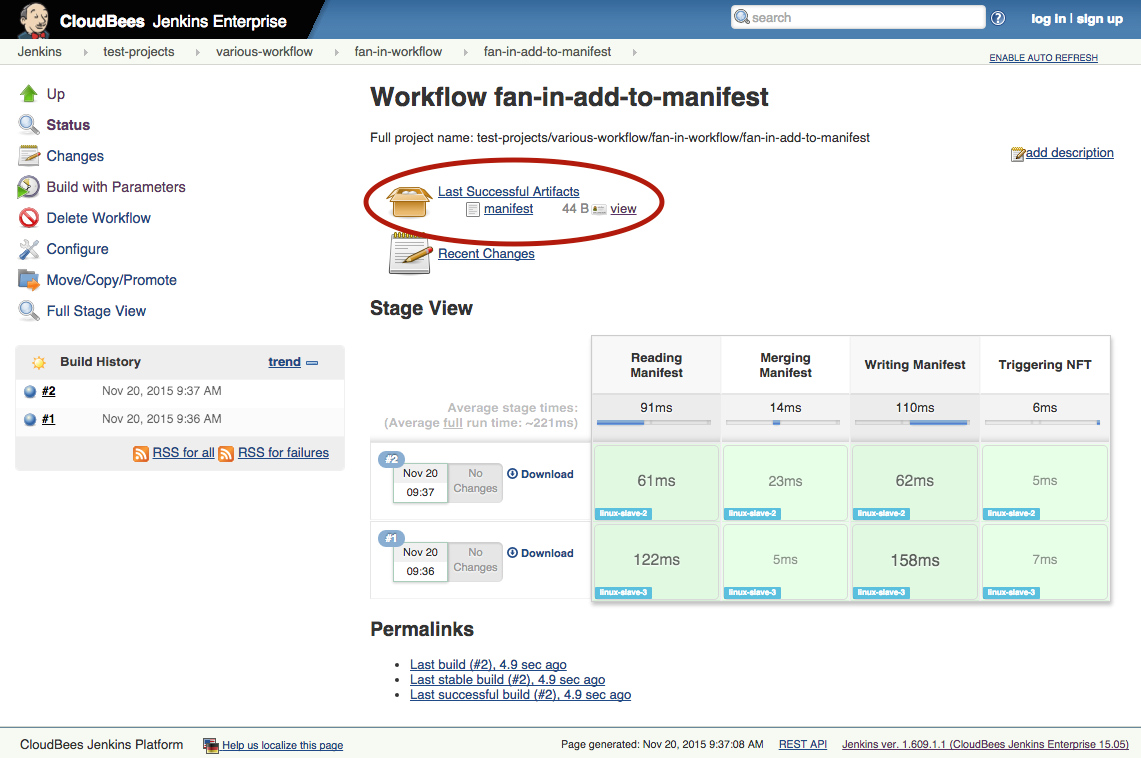
Обратите внимание на ссылку на манифест, который выделен.
Манифест показывает версии приложений, требуемые согласно:
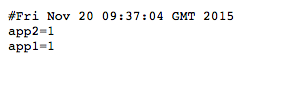
Развернуть и проверить работу
Задание развертывания и тестирования также настроено на одновременное выполнение одной сборки. Это также тип задания рабочего процесса. Это гарантирует объединение нескольких триггеров — вместо этого он не параметризуется, считывая манифест для компонентов и версий, требуемых из предыдущей сборки.
В этом задании используются аналогичные шаги для чтения как необходимого манифеста из вышестоящей сборки, так и текущего манифеста из последнего запуска этого задания. Опять же, нам нужно обрабатывать сценарии, когда это первый запуск, а файл не существует.
Создав текущие и требуемые объекты Properties (), это простой фрагмент отличного кода для сравнения и возврата списка необходимых обновлений:
def compareVersions ( requiredVersions, currentVersions) {
currentapps = currentVersions.stringPropertyNames().toArray()
reqapps = requiredVersions.stringPropertyNames().toArray()
Properties updatedVersions = new Properties()
for (i=0; i < reqapps.size(); i++) {
def app=reqapps[i]
if (currentVersions.getProperty(app) == requiredVersions.getProperty(app) ) {
log "Calculating Deltas", "Correct version of $app already deployed"
} else {
log "Calculating Deltas", "Adding $app for deployment"
updatedVersions.setProperty(app, requiredVersions.getProperty(app))
}
}
return updatedVersions
}Приведенный выше код сравнивает набор развернутых в настоящее время версий (полученных из предыдущей сборки) и требуемых (из задания добавления в манифест ) и генерирует список требуемых обновлений. Вместо того, чтобы извлекать текущие версии из результатов последней успешной сборки, можно было бы запросить у каждого из работающих приложений их версию в качестве более строгой проверки. Также возможно, что реализация средств удаления ненужных приложений может быть рассмотрена. Эти улучшения оставлены читателю для реализации.
Если изменения обнаружены, нам необходимо выполнить необходимое развертывание и повторное развертывание в среде. Чтобы уменьшить задержки при выполнении сборки, мы будем использовать возможность параллельного запуска подпроцессов:
if (appsToUpdate.size()>0) {
log "Update Apps", "The following apps require updating: ${appsToUpdate.toString()}"
def branches = [:]
for (i=0; i < appsToUpdate.size(); i++) {
def app=appsToUpdate[i]
def revision = updatedVersions.getProperty(app)
branches[app] = {
decom(app, revision)
deploy (app, revision)
}
}
parallel branches
}Разложение и развертывание — это функции, определенные в скрипте. Читатель должен выполнить необходимые шаги для выполнения этих задач — либо внутри рабочего процесса, либо путем вызова существующих механизмов.
По завершении всех развертываний выполняются шаги теста. Опять же, читателю поручено заполнить детали.
Последним этапом после завершения этапа тестирования является повторный запуск задания, чтобы оно снова запускалось. Эта потребность была специфична для конкретного клиента — вы можете выбрать успешное тестирование, чтобы опубликовать результаты, выполнить некоторые дополнительные развертывания, такие как промежуточная среда или запустить другое задание.
Выполнение можно контролировать из Stage View:
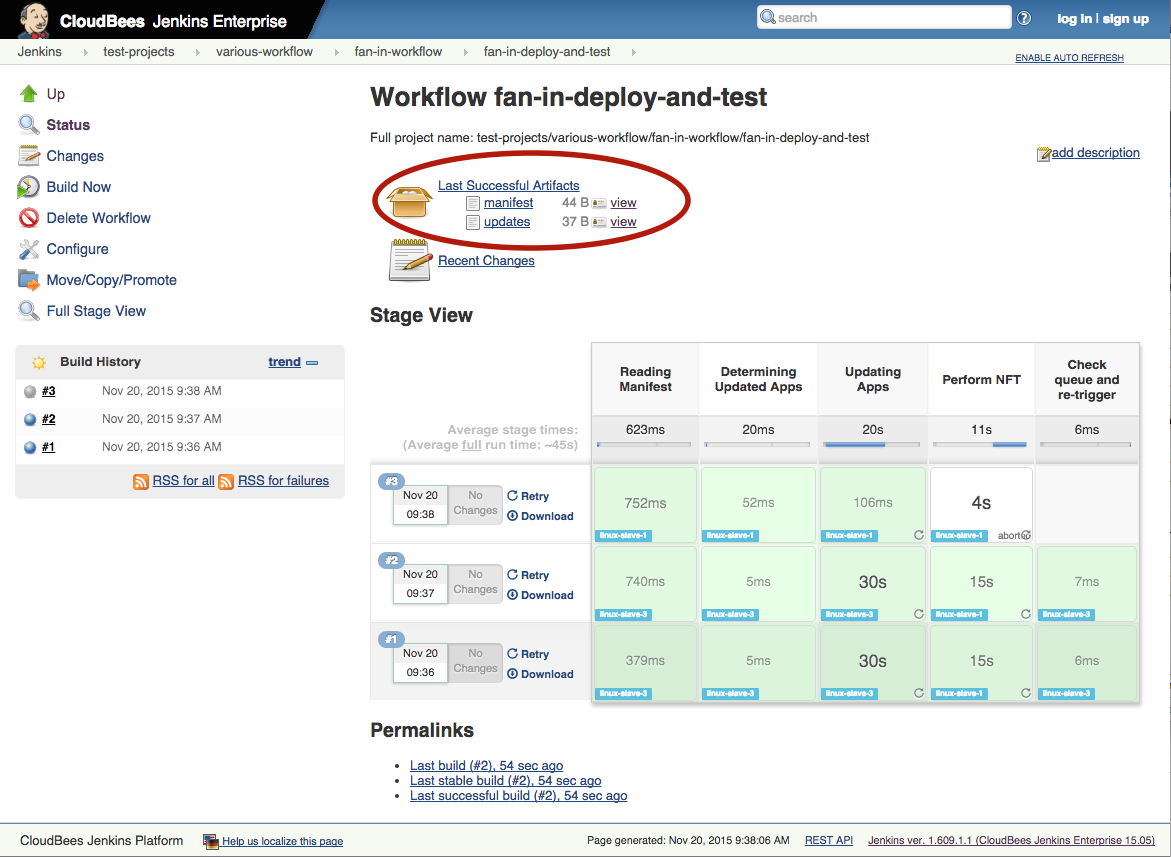
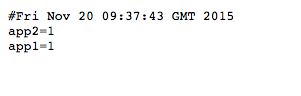
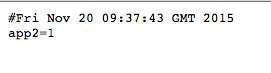
Снова обратите внимание на ссылки на манифест протестированных версий и обновления, которые были включены в прогон:
Содержание манифеста:
Обновления содержимого:
Полный исходный код можно загрузить по адресу https://github.com/harniman/workflow-demos/blob/master/fan-in-deploy-and-test.groovy .
Дальнейшие улучшения
Эти два задания рабочего процесса имеют некоторые общие функции, такие как чтение и запись объектов свойств в / из файлов. Вместо дублирования следует рассмотреть возможность извлечения многократно используемых функций в общую глобальную библиотеку CPS. Пожалуйста, смотрите https://www.cloudbees.com/blog/jenkins-workflow-using-global-library-implement-re-usable-function-call-secured-http-endpoint для более подробной информации.