Добро пожаловать, дорогой читатель, в другой пост из моего блога. В этой новой серии мы поговорим об архитектуре, специально разработанной для обработки данных из файлов журналов, поступающих из приложений, с объединением 3 инструментов, Logstash, ElasticSearch и Kibana. Но в конце концов, нам действительно нужна такая структура для обработки файлов журнала?
Стеки бревна
В экосистеме компании существует множество систем, таких как CRM, ERP и т. Д. В таких средах системы обычно создают тонны журналов, которые обеспечивают не только анализ в реальном времени технического состояния программное обеспечение, но также может предоставить некоторую деловую информацию, например, журнал поведения клиента в корзине. Чтобы погрузиться в этот полезный источник информации, введите архитектуру ELK, название которой происходит от инициалов программного обеспечения: ElasticSearch, LogStash и Kibana. На рисунке ниже показано в макро-видении поток между инструментами:
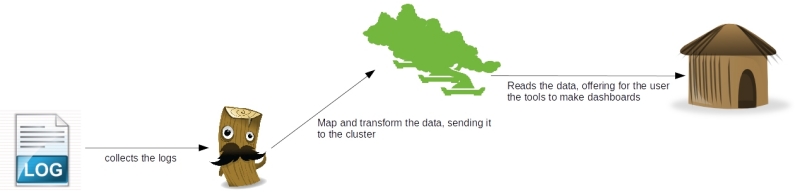
Как мы видим, существует четкое разделение проблем между инструментами, где каждый из них имеет свою индивидуальную часть при обработке данных журнала:
- Logstash : отвечает за сбор данных, преобразование, такое как синтаксический анализ — с помощью регулярных выражений — добавление полей, форматирование в виде структур, таких как JSON, и т. Д. И, наконец, отправка данных в различные пункты назначения, например кластер ElasticSearch. Позже в этом посте мы увидим более подробно об этом полезном инструменте;
- ElasticSearch : индексатор данных RESTful, ElasticSearch предоставляет кластерное решение для поиска и анализа набора данных. Во второй части нашей серии мы увидим больше об этом инструменте;
- Kibana : веб-приложение, отвечающее за предоставление легкого и простого в использовании инструмента панели инструментов. В третьей и последней части нашей серии мы увидим больше этого инструмента;
Итак, чтобы начать наш путь в стеке ELK, давайте начнем с обсуждения инструмента, отвечающего за интеграцию наших данных: LogStash.
Установка LogStash
Для установки все, что нам нужно сделать, это разархивировать файл, полученный с сайта LogStash, и запустить двоичные файлы в папке bin. Единственным предварительным условием для инструмента является установка и настройка Java в среде. Если читатель хочет следовать моим инструкциям в той же системе, что и я, я использую Ubuntu 14.10 с Java 8, которую можно скачать с сайта Oracle здесь .
Установив и настроив Java, мы начинаем с загрузки и разархивирования файла. Для этого мы открываем терминал и вводим:
curl https://download.elasticsearch.org/logstash/logstash/logstash-1.4.2.tar.gz | tar -xzПосле загрузки у нас будет LogStash в той же папке, где мы запускаем нашу команду ‘curl’. В терминологии LogStash у нас есть 4 типа конфигурации, которые мы можем сделать для потока, с именем:
- вход : в этой конфигурации мы помещаем источники наших потоков, которые могут варьироваться от опроса файлов файловой системы до более сложных входных данных, таких как очередь Amazon SQS и даже Twitter;
- кодек : в этой конфигурации мы выполняем преобразования данных, например, превращаемся в структуру JSON или группируем строки, которые семантически связаны, как, например, трассировка стека Java;
- фильтр : в этой конфигурации мы выполняем такие операции, как разбор данных из / в разные форматы, удаление специальных символов и контрольных сумм для дедупликации;
- выходные данные : в этой конфигурации мы определяем места назначения для обработанных данных, таких как кластер ElasticSearch, AWS SQS, Nagios и т. д .;
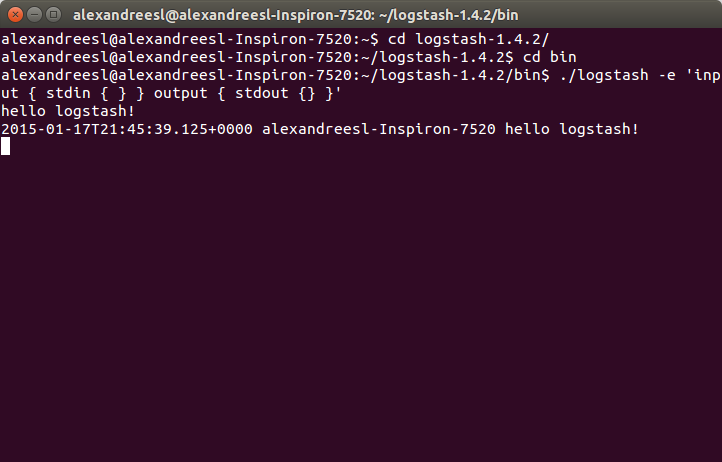
Теперь, когда мы установили структуру конфигурации LogStash, давайте начнем с нашего первого выполнения. В LogStash у нас есть два способа сконфигурировать наше выполнение, один из которых заключается в настройке самой команды start, а другой — в файле конфигурации для этой команды. Самый простой способ загрузить поток LogStash — это настроить вход и выход в качестве самой консоли. Чтобы выполнить это выполнение, мы открываем терминал, переходим в папку bin установки нашего LogStash и выполняем следующую команду:
./logstash -e 'input { stdin { } } output { stdout {} }'Как мы видим после запуска команды, мы загрузили LogStash, установив консоль в качестве ввода и вывода, без каких-либо преобразований или фильтрации. Чтобы проверить, мы просто вводим что-нибудь на консоль, видя, что наше сообщение отображается обратно инструментом:
Теперь, когда мы закончили установку, давайте начнем с самой лаборатории. К сожалению, или нет, в зависимости от точки зрения, нам потребовалось бы много времени, чтобы показать все возможности того, что мы можем сделать с помощью инструмента, поэтому для краткого, но наглядного примера мы запустим 2 потока logstash. , чтобы сделать следующее:
1-й поток:
- Ввод будет сделан java-программой, которая создаст файл журнала с log4j, представляющий техническую информацию;
- Сейчас мы просто напечатаем события logstash на консоли, используя кодек rubydebug. В нашей следующей части серии мы вернемся к этой конфигурации и изменим вывод, чтобы отправлять события вasticsearch;
2-й поток:
- Ввод будет сделан той же Java-программой, которая создаст позиционный файл, представляющий деловую информацию клиентов и заказов;
- Затем мы будем использовать фильтр grok для разбора данных позиционного файла на отдельные поля, получая данные для шага вывода;
- Наконец, мы используем вывод mongodb, чтобы сохранить наши данные — фильтрацию только для сохранения порядков — в коллекции Mongodb;
С определенными потоками мы можем начать наше кодирование. Во-первых, давайте создадим Java-программу, которая будет генерировать входные данные для потоков. Код для программы можно увидеть ниже:
package com.technology.alexandreesl;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import org.apache.log4j.Logger;
public class LogStashProvider {
private static Logger logger = Logger.getLogger(LogStashProvider.class);
public static void main(String[] args) throws IOException {
try {
logger.info("STARTING DATA COLLECTION");
List<String> data = new ArrayList<String>();
Customer customer = new Customer();
customer.setName("Alexandre");
customer.setAge(32);
customer.setSex('M');
customer.setIdentification("4434554567");
List<Order> orders = new ArrayList<Order>();
for (int counter = 1; counter < 10; counter++) {
Order order = new Order();
order.setOrderId(counter);
order.setProductId(counter);
order.setCustomerId(customer.getIdentification());
order.setQuantity(counter);
orders.add(order);
}
logger.info("FETCHING RESULTS INTO DESTINATION");
PrintWriter file = new PrintWriter(new FileWriter(
"/home/alexandreesl/logstashdataexample/data"
+ new Date().getTime() + ".txt"));
file.println("1" + customer.getName() + customer.getSex()
+ customer.getAge() + customer.getIdentification());
for (Order order : orders) {
file.println("2" + order.getOrderId() + order.getCustomerId()
+ order.getProductId() + order.getQuantity());
}
logger.info("CLEANING UP!");
file.flush();
file.close();
// forcing a error to simulate stack traces
PrintWriter fileError = new PrintWriter(new FileWriter(
"/etc/nopermission.txt"));
} catch (Exception e) {
logger.error("ERROR!", e);
}
}
}Как мы видим, это очень простой класс, который использует log4j, чтобы сгенерировать некоторый журнал и вывести позиционный файл, представляющий данные от клиентов и заказов, и в конце попытаться создать файл в папке, к которой у нас нет разрешения написать по умолчанию, «форсируя» ошибку, чтобы произвести трассировку стека. Полный код программы можно найти здесь . Теперь, когда мы создали наш генератор данных, давайте начнем настройку logstash. Конфигурация для нашего первого примера следующая:
input {
log4j {
port => 1500
type => "log4j"
tags => [ "technical", "log"]
}
}
output {
stdout { codec => rubydebug }
}Чтобы запустить скрипт, давайте создадим файл с именем «config1.conf» и сохраним этот файл со скриптом в папке «bin» установочной папки logstash. Наконец, мы запускаем скрипт с помощью следующей команды:
./logstash -f config1.confЭто запустит процесс logstash с предоставленными нами конфигурациями. Чтобы протестировать, просто запустите java-программу, которую мы написали ранее, и мы увидим последовательность событий сообщений в окне консоли logstash, сгенерированную кодеком rubydebug, например, как показано ниже:
{
"message" => "ERROR!",
"@version" => "1",
"@timestamp" => "2015-01-24T19:08:10.872Z",
"type" => "log4j",
"tags" => [
[0] "technical",
[1] "log"
],
"host" => "127.0.0.1:34412",
"path" => "com.technology.alexandreesl.LogStashProvider",
"priority" => "ERROR",
"logger_name" => "com.technology.alexandreesl.LogStashProvider",
"thread" => "main",
"class" => "com.technology.alexandreesl.LogStashProvider",
"file" => "LogStashProvider.java:70",
"method" => "main",
"stack_trace" => "java.io.FileNotFoundException: /etc/nopermission.txt (Permission denied)\n\tat java.io.FileOutputStream.open(Native Method)\n\tat java.io.FileOutputStream.<init>(FileOutputStream.java:213)\n\tat java.io.FileOutputStream.<init>(FileOutputStream.java:101)\n\tat java.io.FileWriter.<init>(FileWriter.java:63)\n\tat com.technology.alexandreesl.LogStashProvider.main(LogStashProvider.java:66)"
}Теперь давайте перейдем к следующему потоку. Сначала мы создаем другой файл с именем «config2.conf» в той же папке, в которой мы создали первый. На этом новом файле мы создаем следующую конфигурацию:
input {
file {
path => "/home/alexandreesl/logstashdataexample/data*.txt"
start_position => "beginning"
}
}
filter {
grok {
match => [ "message" , "(?<file_type>.{1})(?<name>.{9})(?<sex>.{1})(?<age>.{2})(?<identification>.{10})" , "message" , "(?<file_type>.{1})(?<order_id>.{1})(?<costumer_id>.{10})(?<product_id>.{1})(?<quantity>.{1})" ]
}
}
output {
stdout { codec => rubydebug }
if [file_type] == "2" {
mongodb {
collection => "testData"
database => "mydb"
uri => "mongodb://localhost"
}
}
}После создания конфигурации мы можем запустить наш второй пример. Однако, прежде чем мы это сделаем, давайте немного углубимся в конфигурацию, которую мы только что сделали. Во-первых, мы использовали файловый ввод, который заставит logstash следить за файлами в папке и обрабатывать их по мере их появления во входной папке.
Далее мы создаем фильтр с помощью плагина grok. Этот фильтр использует комбинации регулярных выражений, которые анализируют данные из входных данных. Плагин содержит более 100 готовых шаблонов, которые помогают в разработке. Другим полезным инструментом в использовании grok является сайт, на котором мы могли бы проверить наши выражения перед использованием. Обе ссылки доступны в разделе ссылок в конце этого поста.
Наконец, мы используем плагин mongodb, где мы ссылаемся на наш logstash для базы данных и коллекции экземпляра mongodb, где мы будем вставлять данные из файла в документы mongodb. Мы также снова использовали кодек rubydebug, поэтому мы также можем видеть обработку файлов на консоли. Читатель заметит, что мы использовали оператор if перед настройкой вывода mongodb. После того, как мы проанализируем данные с помощью grok, мы можем использовать вновь созданные поля, чтобы сделать некоторую логику в нашем потоке. В этом случае мы фильтруем данные только с типом «2», поэтому в коллекцию на mongodb поступают только данные заказа, а не все данные. Мы могли бы расширить этот пример, например, сохранить данные в две разные коллекции, но для идеи передачи общего представления о структуре logstash для читателя,настоящей логики будет достаточно.
PS: В этом примере предполагается, что читатель установил и запускает mongodb на порте по умолчанию в своей среде, с созданием базы данных «mydb» и коллекции «testData». Если у читателя нет mongodb, инструкции можно найти в официальной документации .
Наконец, когда все установлено и настроено, мы запускаем скрипт с помощью следующей команды:
./logstash -f config2.confПосле запуска logstash, если мы запустим нашу программу для генерации файла, мы увидим, что logstash обрабатывает данные, как показано ниже:
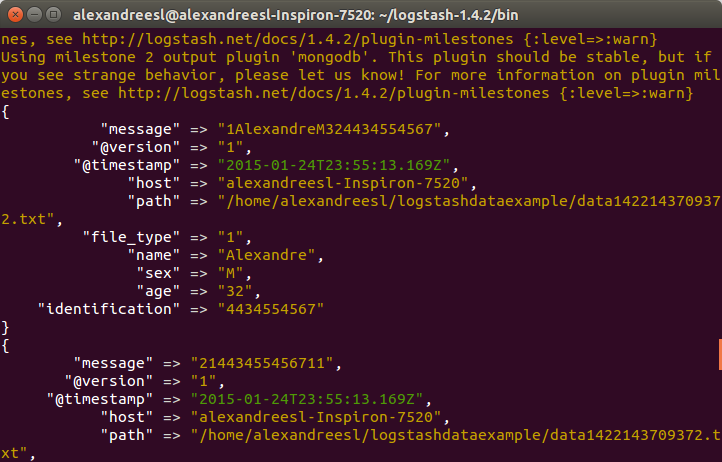
И наконец, если мы запросим коллекцию на mongodb, мы увидим, что данные сохраняются:
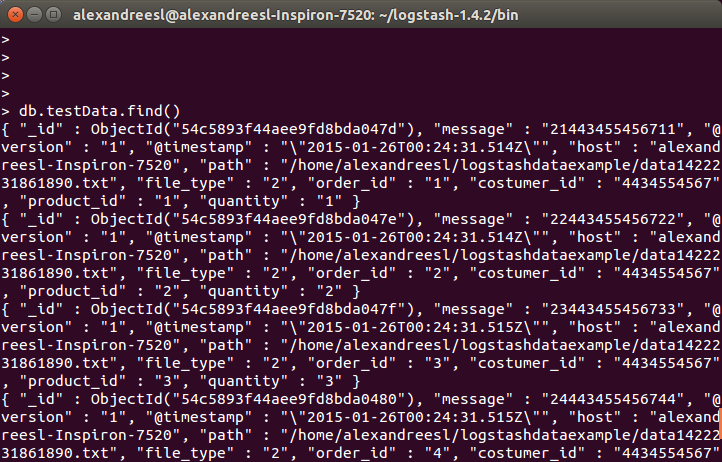
Вывод
И так мы завершаем первую часть нашей серии. При простом использовании logstash оказывается полезным инструментом для интеграции информации из различных форматов и источников, особенно связанных с журналами. В следующей части нашей серии мы погрузимся в следующий инструмент нашего стека: ElasticSearch. До скорого