За время существования вашего продукта и базы кода вы будете собирать множество журналов, поэтому важно иметь возможность поиска по ним. В редких случаях, когда возникает проблема безопасности, отсутствие такой возможности невероятно болезненно.
Возможно, вы сможете использовать службы, позволяющие быстро выполнять поиск по журналам за последние две недели. Но что, если вы хотите искать в течение последних шести месяцев, года или даже дальше? Такая доступность может быть довольно дорогой или вообще не возможной с существующими услугами.
Многие размещенные службы журналов предоставляют поддержку архивации S3, которую мы можем использовать для построения инфраструктуры долгосрочного анализа журналов с помощью AWS Redshift. Недавно я настроил сценарии, чтобы иметь возможность создавать эту инфраструктуру, когда она нам понадобится в Codeship.
«Можете ли вы искать в журналах по годам в случае проблем с безопасностью?» через @codeship
AWS Redshift
AWS Redshift — это решение AWS для хранения данных. Он имеет простой механизм кластеризации и приема, идеальный для загрузки больших файлов журналов и последующего поиска по ним с помощью SQL.
Поскольку он автоматически балансирует ваши файлы журналов на нескольких машинах, вы можете легко увеличить масштаб, если вам нужна большая скорость. Как я уже говорил ранее, просмотр большого количества файлов журнала является относительно редким случаем; вам не нужно, чтобы эта инфраструктура была постоянно, что делает ее идеальным вариантом использования AWS.
Настройка вашего журнала анализа
Давайте пройдемся по сценариям, которые управляют нашей долгосрочной инфраструктурой анализа журналов. Вы можете проверить их в репозитории GitHub flomotlik / redshift-logging .
Я расскажу вам шаг за шагом о настройке всей необходимой конфигурации переменных среды, а также о начале создания кластера и поиска в журналах.
Но сначала давайте посмотрим, что делает скрипт установки, прежде чем углубляться во все различные опции, которые вы можете установить:
- Создает кластер AWS Redshift. Вы можете настроить количество серверов и тип используемого сервера.
- Ожидает кластера, чтобы стать готовым.
- Создает таблицу SQL внутри кластера Redshift для загрузки файлов журнала.
- Загружает все файлы журнала в кластер Redshift из AWS S3.
- Очищает базу данных и печатает команду доступа psql для подключения к кластеру.
Обязательно ознакомьтесь со сценарием на GitHub, прежде чем мы перейдем ко всем различным параметрам, которые вы можете установить через файл .env.
Варианты для установки
Ниже приведен список всех доступных вам опций. Вы можете просто скопировать файл .env.template в .env, а затем заполнить все параметры, чтобы получить их.
- AWS_ACCESS_KEY_ID
- Ключ AWS учетной записи, которая должна запускать кластер Redshift.
- AWS_SECRET_ACCESS_KEY
- Секретный ключ AWS учетной записи, которая должна запускать кластер Redshift.
- AWS_REGION = мы-восток-1
- Регион AWS, в котором должен работать кластер, по умолчанию us-east-1. Убедитесь, что вы используете тот же регион, который используется для архивирования журналов на S3, чтобы они были закрыты.
- REDSHIFT_USERNAME
- Имя пользователя для подключения с PSQL в кластере.
- REDSHIFT_PASSWORD
- Пароль для подключения с PSQL в кластере.
- S3_AWS_ACCESS_KEY_ID
- Ключ AWS, у которого есть доступ к корзине S3, из которой вы хотите получить логи. Мы запускаем кластер анализа журналов в нашей учетной записи AWS Sandbox, но извлекаем журналы из нашей производственной учетной записи AWS, чтобы кластер Redshift никак не влиял на производительность.
- S3_AWS_SECRET_ACCESS_KEY
- Секретный ключ AWS, у которого есть доступ к корзине S3, из которой вы хотите получить логи.
- PORT = 5439
- Порт для подключения к PSQL.
- CLUSTER_TYPE = одноузловых
- Тип кластера может быть одноузловым или многоузловым. Многоузловые кластеры получают автоматическую балансировку, что дает вам большую скорость при более высоких затратах.
- NODE_TYPE
- Тип экземпляра, который используется для узлов кластера. Ознакомьтесь с документацией Redshift для получения подробной информации о типах экземпляров и их различиях.
- NUMBER_OF_NODES = 10
- Количество узлов при работе в многорежимном режиме.
- CLUSTER_IDENTIFIER = лог-анализ
- DB_NAME = лог-анализ
- S3_PATH = s3: // your_s3_bucket / papertrail / журналы / 862693 / дт = 2015
Формат базы данных и неудачные загрузки
При попадании операторов журнала в кластер, убедитесь, что проверили количество неудачных загрузок, которые происходят. Возможно, вам придется отредактировать формат базы данных в соответствии с вашим конкретным стилем вывода журнала. Вы можете легко отладить это, создав сначала кластер с одним узлом, который загружает только небольшое подмножество ваших журналов и в результате работает очень быстро. Удостоверьтесь, что у вас нет или почти нет сбойных нагрузок, прежде чем распространяться на весь кластер
В случае возникновения проблем ознакомьтесь с документацией команды copy, которая загружает ваши журналы в базу данных, и параметрами для этого в скрипте установки.
Пример и ориентиры
Быстро настроить весь кластер и выполнить примеры запросов к нему. Например, я загружу все наши журналы за последние девять месяцев в кластер Redshift и выполню несколько запросов к нему. Я не тратил время на оптимизацию таблицы, но вы могли бы определенно увеличить скорость работы всей системы, если это необходимо. Это достаточно быстро уже для нас из коробки.
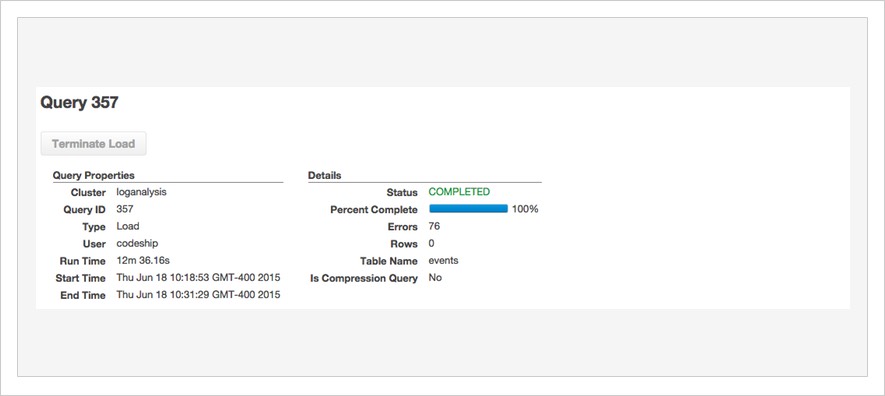
Как вы можете видеть здесь, загрузка всех журналов мая — более 600 миллионов строк журнала — заняла всего 12 минут на кластере из 10 машин. Мы могли бы легко загрузить более одного месяца в этот кластер из 10 компьютеров, поскольку хранилища более чем достаточно, но для этого поста достаточно одного месяца.
После этого мы можем просматривать историю всех наших приложений и прошлых серверов с помощью SQL. Мы соединяемся с нашим psql-клиентом и отправляем SQL-запросы к базе данных «events».
Например, что если мы хотим узнать, сколько серверов сборки сообщили о журналах в мае:
|
1
2
3
4
5
|
loganalysis=# select count(distinct(source_name)) from events where source_name LIKE 'i-%'; count ------- 801(1 row) |
Таким образом, в мае для наших клиентов были запущены 801 EC2-серверы. Этот запрос занял ~ 3 секунды, чтобы закончить.
Или, скажем, мы хотим знать, сколько людей зашло на страницу конфигурации нашего основного хранилища (идентификатор проекта скрыт с XXXX ):
|
1
2
3
4
5
|
loganalysis=# select count(*) from events where source_name = 'mothership' and program LIKE 'app/web%' and message LIKE 'method=GET path=/projects/XXXX/configure_tests%'; count ------- 15(1 row) |
Итак, теперь мы знаем, что на этой странице конфигурации в течение мая было 15 обращений. Мы также можем получить все подробности, включая информацию о том, кто к ней обращался, когда просматривали наши журналы. Это может помочь в случае каких-либо проблем с безопасностью, которые мы должны рассмотреть. Запрос занял около 40 секунд, чтобы пройти через все наши журналы, но он может быть оптимизирован на Redshift еще больше.
Это лишь некоторые из запросов, которые вы можете использовать для просмотра журналов, чтобы лучше понять, как ваши клиенты используют вашу систему. И все это вместе с настройкой, которая стоит $ 2,50 в час, может быть немедленно закрыта и воссоздана в любое время, когда вам снова понадобится доступ к этим данным.
Выводы
Возможность поиска и изучения своей истории невероятно важна для построения большой инфраструктуры. Вы должны иметь возможность легко просматривать свою историю, особенно когда речь идет о проблемах безопасности.
С AWS Redshift у вас есть отличный инструмент в руках, который позволяет вам запускать специальную аналитическую инфраструктуру, которая является быстрой и дешевой для краткосрочных обзоров. Конечно, Redshift может сделать гораздо больше.
Сообщите нам, какие ваши процессы и инструменты, связанные с ведением журналов, хранением и поиском, есть в комментариях.
«Долгосрочный анализ логов с помощью AWS Redshift» через @codeship
| Ссылка: | Долгосрочный анализ журнала с помощью AWS Redshift от нашего партнера JCG Флориана Мотлика в блоге Codeship Blog . |