Docker только что опубликовал новый Docker Engine v1.12. Это самый значительный релиз начиная с v1.9. Тогда у нас была сеть Docker, которая, наконец, сделала контейнеры готовыми для использования в кластерах. С версией 1.1.12 Docker заново изобретает себя с совершенно новым подходом к оркестровке кластера. Попрощайтесь с Swarm в качестве отдельного контейнера, который зависит от внешнего реестра данных, и приветствуйте новый Docker Swarm . Все, что вам нужно для управления вашим кластером, теперь включено в Docker Engine. Рой здесь. Служба обнаружения есть. Улучшенная сеть есть.
Старый Swarm (до Docker v1.12) использовал принцип «забей и забудь» . Мы посылали команду мастеру Swarm, и она выполняла эту команду. Например, если мы отправим что-то вроде docker-compose scale go-demo=5 , старый Swarm оценит текущее состояние кластера, обнаружит, что, например, только один экземпляр работает в данный момент, и решит, что он должен беги еще четыре. Как только такое решение будет принято, старый Swarm будет отправлять команды в Docker Engines. В результате у нас будет пять контейнеров, работающих внутри кластера. Чтобы все это работало, нам нужно было настроить агенты Swarm (как отдельные контейнеры) на всех узлах, которые формируют кластер, и подключить их к одному из поддерживаемых реестров данных (Consul, etcd и Zookeeper). Проблема заключалась в том, что Swarm выполнял команды, которые мы посылаем. Это не было поддержание желаемого состояния. По сути, мы говорили ему о том, что мы хотим сделать (например, увеличивать масштаб), а не о том состоянии, которое нам нужно (убедитесь, что запущено пять экземпляров). Позже, старый Swarm получил функцию, которая будет перепланировать контейнеры с неисправных узлов. Однако у этой функции было несколько проблем, которые не позволили ей стать надежным решением (например, вышедшие из строя контейнеры не были удалены из оверлейной сети).
Теперь у нас новый Рой. Он является частью Docker Engine (нет необходимости запускать его как отдельные контейнеры), он включает в себя обнаружение сервисов (нет необходимости настраивать Consul или какой-либо другой реестр по вашему выбору), он спроектирован с нуля, чтобы принимать и поддерживать желаемое состояние и тд. Это действительно серьезное изменение в том, как мы работаем с кластерной оркестровкой.
В прошлом я был склонен к старому Роему больше, чем Кубернетес. Однако этот наклон был лишь незначительным. Были плюсы и минусы для использования любого решения. У Kubernetes было несколько особенностей, которых не хватало Swarm (например, концепция желаемого состояния), старый Swarm сиял своей простотой и низким использованием ресурсов. С новым Swarm (тот, который поставляется с v1.12), у меня больше нет сомнений, какой использовать. Новый Рой — лучший выбор, чем Кубернетес . Он является частью Docker Engine, поэтому вся установка представляет собой одну команду, которая сообщает механизму о присоединении к кластеру. Новая сеть работает как шарм. Пакет, который можно использовать для определения сервисов, может быть создан из файлов Docker Compose, поэтому нет необходимости поддерживать два набора конфигураций (Docker Compose для разработки и другой для оркестровки). Самое главное, что новый Docker Swarm по-прежнему прост в использовании. Сообщество Docker с самого начала обещало, что они привержены простоте, и с этим выпуском они еще раз доказали, что это правда.
И это еще не все. Новая версия поставляется с множеством других функций, которые не связаны напрямую с Swarm. Тем не менее, исследование этих функций потребует гораздо больше, чем одна статья. Поэтому сегодня я сосредоточусь на Swarm, а остальное оставлю для одной из следующих статей.
Поскольку я считаю, что этот код (или в данном случае команды) объясняет вещи лучше, чем слова, мы начнем с демонстрации некоторых новых функций, представленных в версии 1.12. В частности, мы рассмотрим новый командный сервис .
Настройка среды
В следующих примерах предполагается, что у вас установлена версия Docker Machine v0.8 +, включающая Docker Engine v1.12 +. Самый простой способ получить их — через Docker Toolbox .
Если вы пользователь Windows, пожалуйста, запустите все примеры из Git Bash (устанавливается через Docker Toolbox ).
Мы начнем с создания трех машин, которые будут имитировать кластер.
|
1
2
3
4
5
6
7
|
docker-machine create -d virtualbox node-1docker-machine create -d virtualbox node-2docker-machine create -d virtualbox node-3docker-machine ls |
Вывод команды ls выглядит следующим образом.
|
1
2
3
4
|
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORSnode-1 - virtualbox Running tcp://192.168.99.100:2376 v1.12.0node-2 - virtualbox Running tcp://192.168.99.101:2376 v1.12.0node-3 - virtualbox Running tcp://192.168.99.102:2376 v1.12.0 |
Обратите внимание, что версия Docker ДОЛЖНА быть 1.12 или выше. Если это не так, обновите версию Docker Machine, уничтожьте виртуальные машины и начните заново.

После запуска и запуска машин мы можем приступить к настройке кластера Swarm.
|
1
2
3
4
5
|
eval $(docker-machine env node-1)docker swarm init \ --advertise-addr $(docker-machine ip node-1) \ --listen-addr $(docker-machine ip node-1):2377 |
Первая команда задает переменные среды так, чтобы локальный Docker Engine указывал на узел-1 . Второй инициализировал Swarm на этой машине. Прямо сейчас наш Swarm кластер состоит только из одной виртуальной машины.
Давайте добавим два других узла в кластер.
Для повышения безопасности новый узел можно добавить в кластер, только если он содержит токен, сгенерированный при инициализации Swarm. Токен был напечатан в результате команды docker swarm init . Вы можете скопировать и вставить код из вывода или использовать команду join-token .
|
1
|
docker swarm join-token -q worker |
Вывод следующий.
|
1
|
SWMTKN-1-24hd6kvr8ihzu7mtklhwj6p6hi1mv1uw6ohf2axtw9ada02hot-6ttad3td76xwvnctjnt3m0u41 |
Обратите внимание, что этот токен был сгенерирован на моей машине, и в вашем случае он будет другим.
Давайте поместим токен в переменную окружения и добавим два других узла в качестве рабочих.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
TOKEN=$(docker swarm join-token -q worker)eval $(docker-machine env node-2)docker swarm join \ --token $TOKEN \ $(docker-machine ip node-1):2377eval $(docker-machine env node-3)docker swarm join \ --token $TOKEN \ $(docker-machine ip node-1):2377 |
Две другие машины присоединились к кластеру в качестве агентов. Мы можем подтвердить это, отправив команду node ls узлу Leader ( node-1 ).
|
1
2
3
|
eval $(docker-machine env node-1)docker node ls |
Вывод команды node ls выглядит следующим образом.
|
1
2
3
4
|
ID HOSTNAME MEMBERSHIP STATUS AVAILABILITY MANAGER STATUS92ho364xtsdaq2u0189tna8oj * node-1 Accepted Ready Active Leaderc2tykql7a2zd8tj0b88geu45i node-2 Accepted Ready Activeejsjwyw5y92560179pk5drid4 node-3 Accepted Ready Active |
Звезда говорит нам, какой узел мы можем использовать в данный момент. Статус менеджера указывает, что узел-1 является лидером .
В производственной среде мы, вероятно, установили бы более одного узла в качестве лидера и, таким образом, избежали бы простоев развертывания в случае сбоя одного из них. Для этой демонстрации достаточно одного лидера.
Развертывание контейнера в кластере
Прежде чем мы развернем демонстрационную службу, мы должны создать новую сеть, чтобы все контейнеры, составляющие службу, могли взаимодействовать друг с другом независимо от того, на каких узлах они развернуты.
|
1
|
docker network create --driver overlay go-demo |
Мы можем проверить состояние всех сетей с помощью следующей команды.
|
1
|
docker network ls |
Вывод команды network ls выглядит следующим образом.
|
1
2
3
4
5
6
7
|
NETWORK ID NAME DRIVER SCOPEe263fb34287a bridge bridge localc5b60cff0f83 docker_gwbridge bridge local8d3gs95h5c5q go-demo overlay swarm4d0719f20d24 host host localeafx9zd0czuu ingress overlay swarm81d392ce8717 none null local |
Как вы можете видеть, у нас есть две сети, которые имеют область роя . Один с именем ingress был создан по умолчанию при настройке кластера. Второй ( go-demo ) был создан командой network create . Мы назначим все контейнеры, которые составляют сервис go-demo для этой сети.
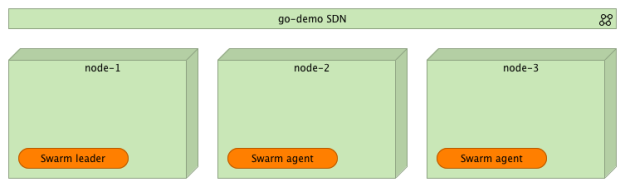
Сервис go-demo требует двух контейнеров. Данные будут храниться в MongoDB. Серверная часть, которая использует эту БД, определяется как контейнер vfarcic / go-demo .
Давайте начнем с развертывания контейнера Монго где-то внутри кластера. Обычно мы использовали ограничения для указания требований к контейнеру (например, тип HD, объем памяти и ЦП и т. Д.). Мы пропустим это и просто скажем Swarm развернуть его в любом месте кластера.
|
1
2
3
4
|
docker service create --name go-demo-db \ -p 27017 \ --network go-demo \ mongo |
Аргумент -p устанавливает порт в 27017 . Обратите внимание, что если он содержит только одно значение, порт будет доступен только через сети, к которым принадлежит контейнер. В этом случае мы устанавливаем демо- сеть (созданную ранее). Как видите, то, как мы используем service create , похоже на команду run Docker, к run вы, вероятно, уже привыкли.
Мы можем перечислить все запущенные сервисы.
|
1
|
docker service ls |
В зависимости от того, сколько времени прошло между командами service create и service ls , вы увидите, что значение столбца Replicas равно нулю или единице. Сразу после создания службы значение должно быть 0/1 , что означает, что реплики запущены с нулем, и цель состоит в том, чтобы иметь одну. После загрузки образа монго и запуска контейнера значение должно измениться на 1/1 .
Окончательный вывод команды service ls должен быть следующим.
|
1
2
|
ID NAME REPLICAS IMAGE COMMANDc8tjeq1hofjp go-demo-db 1/1 mongo |
Если нам нужна дополнительная информация о сервисе go-demo-db , мы можем запустить команду service inspect .
|
1
|
docker service inspect go-demo-db |
Теперь, когда база данных запущена, мы можем развернуть контейнер go-demo .
|
1
2
3
4
5
|
docker service create --name go-demo \ -p 8080 \ -e DB=go-demo-db \ --network go-demo \ vfarcic/go-demo |
В этой команде нет ничего нового. Внутренне он предоставляет порт 8080 и относится к демоверсии сети . Переменная окружения DB является внутренним требованием сервиса go-demo, который сообщает коду адрес базы данных.
На данный момент у нас есть два контейнера ( mongo и go-demo ), которые работают внутри кластера и взаимодействуют друг с другом через сеть go-demo . Обратите внимание, что ни один из них (пока) не доступен вне сети. На данный момент ваши пользователи не имеют доступа к API службы. Мы обсудим это более подробно в следующей статье. До этого я дам только подсказку: вам нужен прокси, способный использовать новую сеть Swarm.
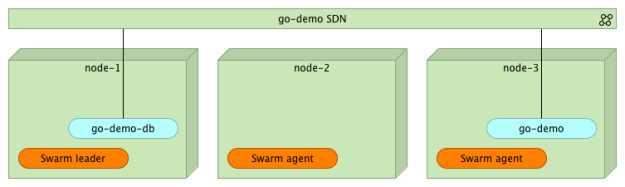
Что произойдет, если мы хотим масштабировать один из контейнеров?
Услуги масштабирования
Например, мы можем сказать Swarm, что мы хотим запустить пять копий сервиса go-demo .
|
1
|
docker service update --replicas 5 go-demo |
С помощью команды service update мы запланировали пять реплик. Через некоторое время Swarm убедится, что пять экземпляров go-demo запущены где-то внутри кластера.
Мы можем подтвердить, что на самом деле пять реплик работают через уже знакомую команду service ls .
|
1
|
docker service ls |
Вывод следующий.
|
1
2
3
|
ID NAME REPLICAS IMAGE COMMAND1hzeaz2jxs5e go-demo 5/5 vfarcic/go-democ8tjeq1hofjp go-demo-db 1/1 mongo |
Как мы видим, пять из пяти реплик контейнера go-demo работают.
Команда service ps предоставляет более подробную информацию об одном сервисе.
|
1
|
docker service ps go-demo |
Вывод следующий.
|
1
2
3
4
5
6
|
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR40jasxwg45kg0p1ulht39904o go-demo.1 vfarcic/go-demo node-3 Running Running about a minute ago08mghas13b99e9bb4rsols77o go-demo.2 vfarcic/go-demo node-2 Running Running 51 seconds agobus2hm8y6a113lnemrz5ke0yn go-demo.3 vfarcic/go-demo node-2 Running Running 51 seconds ago8vae12ugrrrakevey74p7hhsq go-demo.4 vfarcic/go-demo node-1 Running Running 53 seconds ago99uura8n1tgjtjk4tqp49mszz go-demo.5 vfarcic/go-demo node-3 Running Running about a minute ago |
Мы видим, что сервис go-demo запускает пять экземпляров, распределенных по трем узлам. Поскольку все они принадлежат одной и той же демонстрационной сети, они могут общаться друг с другом независимо от того, где они работают внутри кластера. В то же время ни один из них не доступен извне.
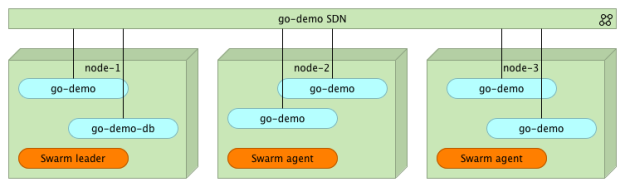
Что произойдет, если один из контейнеров остановлен или весь узел выйдет из строя? В конце концов, процессы и узлы рано или поздно выходят из строя. Ничто не идеально, и мы должны быть готовы к таким ситуациям.
Отказоустойчивость
К счастью, стратегии аварийного переключения являются частью Docker Swarm. Помните, что когда мы выполняем service команду, мы не говорим Swarm, что делать, а требуемое состояние. В свою очередь, Swarm сделает все возможное, чтобы поддерживать указанное состояние независимо от того, что происходит.
Чтобы проверить сценарий сбоя, мы уничтожим один из узлов.
|
1
|
docker-machine rm -f node-3 |
Swarm нужно немного времени, пока он не обнаружит, что узел не работает. Как только это произойдет, он перенесет контейнеры. Мы можем отслеживать ситуацию с помощью команды service ps .
|
1
|
docker service ps go-demo |
Выход (после перепланирования) выглядит следующим образом.
|
1
2
3
4
5
6
7
8
|
ID NAME SERVICE IMAGE LAST STATE DESIRED STATE NODEczbpu8lrhds1wx0ml4vhv65s1 go-demo.1 vfarcic/go-demo node-2 Running Running 13 seconds ago40jasxwg45kg0p1ulht39904o \_ go-demo.1 vfarcic/go-demo node-3 Shutdown Running about a minute ago08mghas13b99e9bb4rsols77o go-demo.2 vfarcic/go-demo node-2 Running Running about a minute agobus2hm8y6a113lnemrz5ke0yn go-demo.3 vfarcic/go-demo node-2 Running Running about a minute ago8vae12ugrrrakevey74p7hhsq go-demo.4 vfarcic/go-demo node-1 Running Running about a minute agocnbwfraw6jbkfzf9ufdv970bg go-demo.5 vfarcic/go-demo node-1 Running Running 13 seconds ago99uura8n1tgjtjk4tqp49mszz \_ go-demo.5 vfarcic/go-demo node-3 Shutdown Running about a minute ago |
Как вы можете видеть, через короткий промежуток времени Swarm перепланировал контейнеры среди исправных узлов ( узел-1 и узел-2 ) и изменил состояние тех, которые работали внутри отказавшего узла, на Завершение работы . Если ваши выходные данные все еще показывают, что некоторые экземпляры работают на узле-3 , пожалуйста, подождите несколько секунд и повторите команду service ps .
Что теперь?
На этом мы завершаем исследование основных концепций новых функций Swarm, которые мы получили в Docker v1.12. Это все, что нужно знать, чтобы успешно запустить кластер Swarm? Даже не близко! То, что мы исследовали сейчас, это только начало. Есть немало вопросов, ожидающих ответа. Как мы предоставляем наши услуги общественности? Как мы разворачиваем новые выпуски без простоев? Есть ли дополнительные инструменты, которые мы должны использовать? Я постараюсь дать ответы на эти и многие другие вопросы в будущих статьях. Следующий будет посвящен исследованию способов предоставления наших услуг населению. Мы попытаемся интегрировать прокси с кластером Swarm.
| Ссылка: | Введение в Docker Swarm (серия Around Docker 1.12) от нашего партнера по JCG Виктора Фарсика в блоге по технологиям . |