Базы данных давно являются плохим родственником уровня приложений, когда речь идет о многих процессах, которые мы считаем само собой разумеющимся в мире .NET. Например, система управления исходным кодом почти повсеместно распространена для файлов приложений, и есть несколько превосходных продуктов VCS, которые делают управление версиями быстрым. Непрерывная интеграция — это еще одна практика, которая, хотя и не столь распространена, все же часто присутствует в надежном жизненном цикле приложений.
Конечно, проблема в том, что объекты базы данных не существуют в виде простых файлов, которые могут быть версионированы, и вы не можете просто взять их и поместить в целевое местоположение, когда вы хотите развернуть их. Вы должны учитывать саму природу баз данных, заключающуюся в том, что вы имеете дело с реальными живыми данными, и последствия порчи развертывания довольно серьезны.
Некоторые специальные инструменты в порядке, и, к счастью, планеты начинают выравниваться таким образом, что некоторые из моих любимых продуктов работают очень хорошо вместе, чтобы служить именно той цели, к которой мы стремимся. В прошлом году я писал о Red Source SQL Source Control как об отличном способе управления версиями баз данных, а позже в этом году рассказал об автоматизации развертываний с TeamCity .
Давайте возьмем эти инструменты — плюс еще несколько из пакета продуктов Red Gate — и, наконец, сделаем развертывание базы данных одним щелчком по-настоящему первоклассным гражданином с равноправным приложением.
Получите вашу базу данных под контролем исходного кода
Прежде всего, ничего из этого не будет иметь никакого смысла, если только вы не поставите свою базу данных под контроль исходного кода. Как я писал пару дней назад в «Излишнем зле совместной разработки баз данных» , «Управление исходным кодом базы данных больше не подлежит обсуждению».
Базы данных являются важным компонентом многих приложений, которые мы создаем, и отрицать их ценность VCS — просто сумасшедший разговор. Без БД в управлении исходным кодом мы получаем фрагментированную, частично полную картину того, что представляет собой приложение. Мы теряем способность говорить «Здесь — это состояние кода с течением времени», поскольку существует только часть картины.
Конечно, мы также теряем все преимущества производительности не только откатов, когда это необходимо, но и интеграции с работой наших коллег. Иногда мы обращаемся к последним, используя общие базы данных разработки, но, в общем, вернитесь и прочитайте статью выше, чтобы узнать, что с этим не так.
Но самое главное в контексте этого поста, VCS является «источником правды» для автоматизированных развертываний из среды непрерывной интеграции. Именно здесь начинается жизнь приложения, и именно там TeamCity собирается обратиться, когда она опубликует как веб-приложение, так и базу данных.
схема
Работая с пониманием того, что все, что мы хотим выпустить с помощью этого процесса, должно исходить из управления исходным кодом, очевидные элементы базы данных, которые должны входить в VCS, — это почти все в схеме. Это включает в себя любые объекты базы данных, такие как хранимые процедуры, представления, триггеры и, конечно, таблицы. Поскольку SQL Source Control аккуратно помещает каждый тип объекта в свою собственную папку, все, что нам нужно сделать, — это быстро взглянуть в репозиторий Subversion для проекта, и мы увидим, какие вещи будут там добавляться:
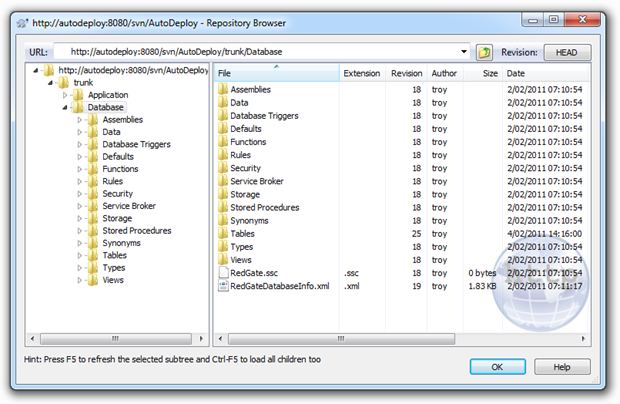
Когда дело доходит до публикации вышесказанного, нам нужен механизм, который может вытащить их из системы контроля версий, затем выполнить сценарий и выполнить необходимые изменения в целевой среде. В зависимости от изменений мы можем удалять объекты, изменять разрешения, изменять длину данных или, возможно, любые другие возможные изменения в базе данных. Главное, что VCS является нашим источником правды, и мы должны убедиться, что целевая среда изменена, чтобы точно соответствовать этому .
Это где SQL Compare вступает в игру. Я давно пользуюсь этим на десктопе как средство автоматизации релизов и обеспечения абсолютно идентичных сред. Но в текущей версии есть две особенности, которые делают ее идеальной для наших целей; автоматическое выполнение командной строки и синхронизация из источника VCS, последний из которых требует версии Professional.
В этой статье я собираюсь запустить процесс для модели данных, которая выглядит следующим образом:
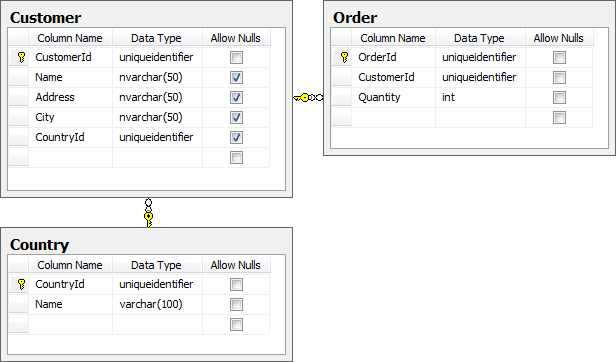
Теоретически таблицы «Заказчик» и «Заказ» будут накапливать транзакционные данные, а таблица «Страна» будет содержать статический набор справочных данных. Важность этого различия скоро станет ясна, но сейчас давайте просто поработаем, предполагая, что все, что вы видите на изображении выше, удачно спрятано в VCS через SQL Source Control.
Данные не данные
Вот спорный вопрос для вас; версия данных. Но есть данные, а затем есть данные . То, что никогда не должно входить в систему контроля версий, — это транзакционные данные, полученные во время нормальной работы приложения. Он не должен использоваться как сценарии SQL, он не должен передаваться в CSV и определенно не должен использоваться как резервная копия базы данных.
Но есть класс данных, которые должны входить в систему контроля версий, и это любые данные, необходимые для реального функционирования приложения, такие как справочные данные. Например, если регистрационная форма содержит обязательный выпадающий список стран, взятых из таблицы «Страна», мы должны получить эти данные, чтобы все работало.
В принципе, мы хотим, чтобы VCS содержал достаточно информации о приложении, чтобы мы могли развернуть его непосредственно в целевой среде, и все будет работать . Чтобы сделать это, нам нужны средства для генерации данных в формате сценариев, хранения их в системе управления исходным кодом, их извлечения и синхронизации с целевой средой.
Но прежде чем мы это сделаем, нам нужно заполнить мою локальную базу данных разработки (потому что общая будет злой) списком стран (спасибо Text Fixer ). Как только это будет сделано, мы можем перейти к фактическому версионированию данных.
Это то место, где этот пост идет в несколько ином, хотя и значительно улучшенном направлении, к тому, что я изначально планировал. Вы видите, я был собирается писать (на самом деле я — то в конечном итоге удаление) о том , как SQL Data Compare может быть использован для версии справочных данных. Это включало проверку схемы базы данных в пути к папке и генерацию в ней справочных данных. Я начал оплакивать громоздкую природу этого; поддерживая другую рабочую копию БД вне одного SQL Source Control, управляет различными процессами (и впоследствии различными ревизиями), чтобы получить все в VCS, и, возможно, наиболее разочаровывающе, требуя, чтобы другой продукт просто сохранял данные версионными. Затем появился предварительный предварительный просмотр SQL Source Control 2.
Видите ли, следующая версия распознает эту проблему и, как обычно, Red Gate делает ее чрезвычайно простой версией данных. Вы просто щелкаете правой кнопкой мыши по таблице и мгновенно вводите данные в «hey presto»:
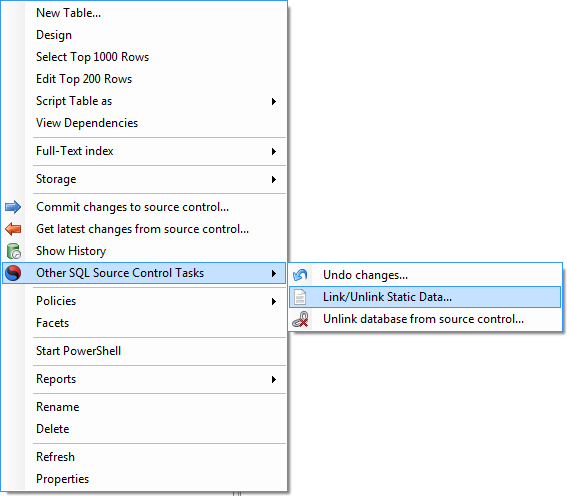
С помощью этой опции мы теперь можем явно указать, что таблица «Страна» содержит нашу ссылку — или «статическую» в номенклатуре SQL Compare — данные:
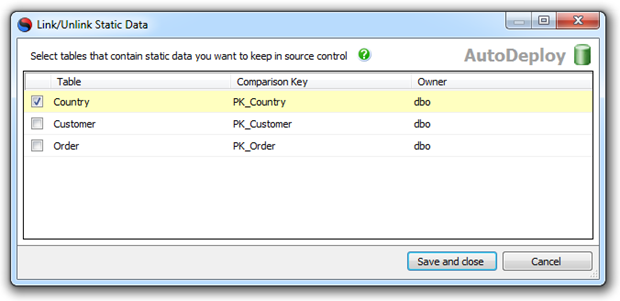
Это гарантирует, что как только мы вернемся к знакомой старой вкладке «Commit Changes», у нас будет богатый набор статических данных, готовых для управления версиями. Давайте посмотрим на то, что мы совершаем:
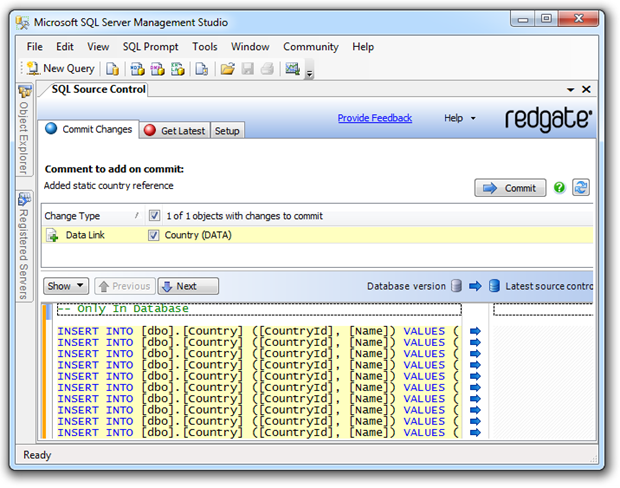
Теперь мы можем пойти дальше и просто зафиксировать это непосредственно в системе контроля версий. Преимущество управления версиями данных таким образом заключается в том, что одна транзакция также может содержать изменения в схеме. Чтобы дать вам представление о том, насколько проще это сделать по сравнению с исходным подходом SQL Data Compare, который я использовал, приведенные выше несколько абзацев заменили более 1100 слов и полдюжины иллюстраций. Очень хорошо!
Как и в случае со схемой, нам в конечном итоге нужны средства автоматизации развертывания этих данных в целевой среде. Это будет означать не только вставку нескольких записей, но и их последующее обновление или удаление. Нам нужен механизм синхронизации, и здесь мы возвращаемся к SQL Data Compare Professional, но он будет выполнять всю свою работу с сервера сборки.
Сборка
Давайте начнем с гаек о том, как все это будет работать при развертывании. Во-первых, я собираюсь использовать проект TeamCity, который так хорошо мне помогал в течение всей серии . Тем не менее, я обновил TeamCity 5 до версии 6, поэтому, хотя все выглядит довольно знакомо, у нас будет несколько новых функциональных возможностей, которые станут очень полезными чуть позже.
Я также собираюсь использовать комбинацию SQL Compare и SQL Data Compare — версии Professional для каждой из них, чтобы они могли работать со сценариями из VCS — так что оба они должны быть установлены на сервере сборки . К счастью, они не потребуются нам нигде, например на компьютерах разработчиков.
Начнем с общих настроек сборки:
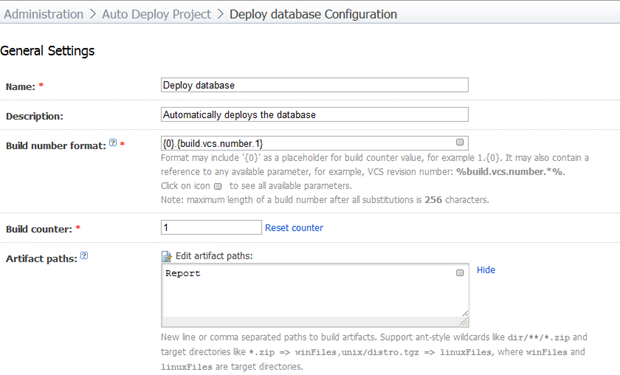
Как я уже говорил в предыдущих статьях, мне всегда нравится сохранять номер версии VCS в номере сборки, поскольку в дальнейшем это может значительно облегчить жизнь. Путь «Отчет» в наших артефактах будет содержать выходные данные развертывания, чтобы мы могли проверить его после сборки.
Переходя к конфигурации VCS, я оставил все основные настройки в их положениях по умолчанию и настроил только правило проверки VCS:
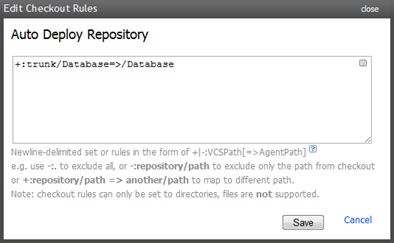
Одна вещь, которую я изменил в исходном решении, — это структура в VCS. Вместо того чтобы сидеть приложением ASP.NET прямо в стволе, я переместил его в папку с именем «Приложение» и поместил папку «База данных» рядом с ней (вы можете увидеть это на скриншоте в «Схеме»). и объекты », раздел выше). Это означало, что мне нужно было вернуться и изменить правило проверки VCS в существующих сборках, чтобы тянуть с одного уровня глубже магистрали.
Переходя к этапам сборки, нам нужно разобраться с этим в двух частях; объекты затем данные. По этой причине TeamCity 6 делает вещи немного проще, потому что теперь он предусматривает несколько шагов в одной сборке. Да, мы могли бы обернуть все это в сценарий MSBuild с некоторыми задачами exec и просто вызвать это, но всегда приятно избегать дополнительных уровней сложности, где это возможно.
Первым шагом будет синхронизация схемы, и мы запустим ее непосредственно из исполняемого файла SQL Compare. Сначала нам нужно выполнить это просто потому, что от этого может зависеть синхронизация данных (т. Е. Создается новая справочная таблица и значения для вставки). Давайте начнем:
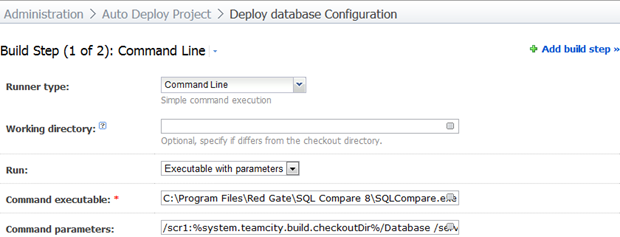
Магия в параметрах:
/scr1:%system.teamcity.build.checkoutDir%/Database /server2:(local) /db2:AutoDeploy /Sync /Include:identical /Report:Report/SchemaDiffReport.html /ReportType:Interactive /ScriptFile:Report/SchemaSyncScript.sql /Force /Verbose
Как кратко я могу это объяснить, вот что происходит; источник наших сценариев находится в папке «База данных» каталога извлечения (мы указали это в правиле оформления заказа). Мы собираемся синхронизировать эту схему с SQL Server, известным как «(локальный)» (очевидно, это был бы удаленный сервер при нормальных обстоятельствах), и базой данных с именем «AutoDeploy». Учетная запись, в которой работает агент сборки, имеет права на создание объектов в целевой базе данных, в противном случае нам нужно будет проверить их передачу с помощью параметров имени пользователя и пароля.
Переходя к конфигурации синхронизации, параметр «Синхронизация» гарантирует, что изменения фактически реплицируются в целевую систему, а не просто дает нам отчет о различиях (подробнее об этом позже).
Параметр «Включить: идентичный» означает, что выходные данные команды будут явно сообщать нам, какие объекты были идентичны, и это гарантирует, что SQL Compare не завершится с кодом ошибки, когда все будет идентично. Если мы этого не сделаем, последующие запуски сборки завершатся неудачно и вернут сообщение примерно так:
Выбранные объекты идентичны или в сравнении не было выбрано ни одного объекта.
Мне нравится дополнительная детализация и явная обратная связь с этой опцией, и кроме того, я не хочу, чтобы моя сборка завершилась неудачей только потому, что не было найдено никаких изменений. Более того, если мы не выберем эту опцию, сценарий синхронизации схемы (подробнее об этом в ближайшее время) не будет сгенерирован, и сборка выберет последний, если мы сначала не очистим исходные коды.
Переходя к отчетам, мы автоматически меняем здесь объекты базы данных, что может быть немного пугающим в реальной среде, поэтому я хочу много выходных данных. Параметр «Отчет» даст нам хороший отчет о веб-интерфейсе, который является «Интерактивным» в том смысле, что он позволит нам детализировать изменения (подробнее об этом в ближайшее время). Мы также сохраним фактический файл сценария, который был выполнен для цели, и назовем его «SchemaSyncScript.sql».
Параметр «Force» гарантирует, что когда SQL Compare попытается написать отчет, а один уже существует из предыдущей сборки, он будет перезаписан. Если мы не сделаем этого, сборка выдаст вам хорошее сообщение об ошибке (в этой цитате отсутствует пробел от Red Gate — не от меня!):
Невозможно записать отчет в файл Report / SchemaDiffReport.html, поскольку файл уже существует.
И, наконец, давайте получим как можно больше многословия в ответе команды. Все это попадет в журнал сборки, поэтому чем больше информации, тем лучше.
Прежде чем мы перейдем к синхронизации данных, поскольку SQL Compare с радостью сгенерирует нам хороший HTML-отчет, давайте убедимся, что мы можем отобразить его дружественным образом на странице сборки. Перейдите к администрированию TeamCity -> Конфигурация сервера -> Вкладка «Отчет» и добавьте новую запись следующим образом:
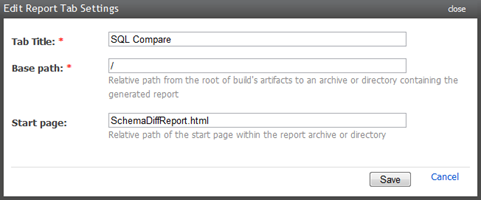
На следующий шаг; синхронизация данных:
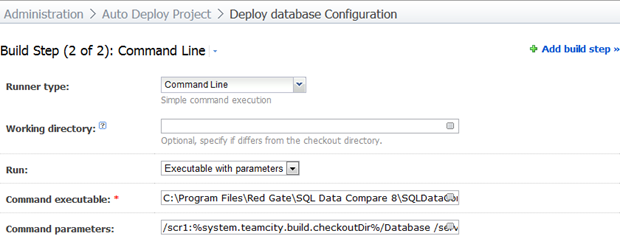
Ситуация очень похожа на SQL Compare, просто другой исполняемый файл и путь и некоторые немного другие параметры:
/scr1:%system.teamcity.build.checkoutDir%/Database /server2:(local) /db2:AutoDeploy /Sync /Include:table:Country /Include:identical /ScriptFile:Report/DataSyncScript.sql /Force /Verbose
На самом деле, есть важное отличие. Я должен был явно включить таблицу, которую я хочу синхронизировать. Вы видите, что по умолчанию Data Compare хочет синхронизировать каждую таблицу и без явного указания, какие из них сравнивать, каждая таблица сравнивается либо со скриптом в управлении исходным кодом, либо ни с чем, и когда вы синхронизируете ничего, ну, в итоге вы получаете ничего такого.
Проблема этого подхода состоит в том, что по мере добавления новых справочных таблиц в базу данных параметры сборки должны обновляться дополнительными параметрами «/ Включить» для каждой таблицы, иначе они не будут синхронизироваться. Итак, в итоге мы получаем белый список таблиц в конфигурации сборки, совпадающих с теми же таблицами, которые уже были версионированы.
Первоначально я делал это наоборот — черный список, исключая таблицы, которые я не хотел синхронизировать, — но вопрос, сидящий на форумах Red Gate , привел к более благоприятному, хотя и не идеальному, результату. Я все еще предпочел бы синхронизировать его непосредственно с VCS и просто игнорировать любые таблицы, которые не были версионированы.
На самом деле есть только одно другое отличие в параметрах, и это имя файла сценария, поэтому он не конфликтует со сценарием изменения схемы. Другие различия на самом деле являются упущениями; нет упоминания об отчете. Если честно, кажется немного странным, что SQL Compare весьма рад представить очень удобный для восприятия отчет о различиях, но Data Compare, похоже, не имеет такой возможности.
Заставить волшебство произойти (или запустить сборку)
Теперь, когда у нас есть вся схема под контролем исходного кода, все справочные данные, на которые мы хотим сослаться, и сборка с шагами развертывания для обоих, давайте запустим все это для новой базы данных, в которой ничего нет. Это абсолютно чистая установка — просто новая, пустая БД:
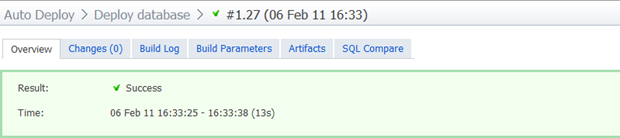
Зеленый это хорошо, но давайте посмотрим, что на самом деле здесь произошло. Во-первых, это заняло всего 13 секунд. Да, изменения очень малы, но они также работают внутри виртуальной машины на моем ПК, включая весь спектр TeamCity, IIS, SVN, SQL Server и, конечно, инструменты Red Gate.
Давайте посмотрим в журнал сборки. Там много информации (помните, я специально просил многословия), но вот первый важный момент на первом этапе сборки для синхронизации схемы:
Object type Name DB1 DB2 --------------------------------------------------------------------- Table [dbo].[Country] >> Table [dbo].[Customer] >> Table [dbo].[Order] >>
Здесь мы видим перечисленные таблицы и двойные угловые скобки, указывающие от DB1 (который является нашей VCS) к DB2 (которая является целевой базой данных). Угловые скобки означают, что структура слева будет скопирована на структуру справа.
Журнал затем содержит все сценарии создания и различную другую информацию, пока мы не перейдем ко второму этапу сборки, где данные синхронизируются. Вот что важно:
Object type Name Records DB1 DB2 --------------------------------------------------------------------- Table [dbo].[Country] 244 >>
Довольно понятно, 244 записи будут вставлены в нашу совершенно новую таблицу «Страна». Давайте двигаться дальше и посмотрим на артефакты, которые были созданы:
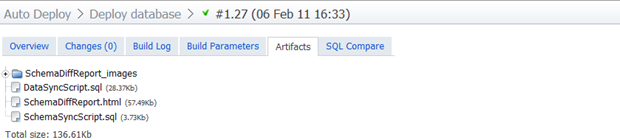
Здесь следует рассмотреть две основные схемы: SchemaSyncScript.sql и DataSyncScript.sql. Они оба на самом деле довольно ничем не примечательны, так как первый содержит серию операторов CREATE, а последний содержит все операторы INSERT, которые мы видели, когда SQL Data Compare впервые их генерировал.
Это вкладка SQL Compare, где все становится немного интереснее:
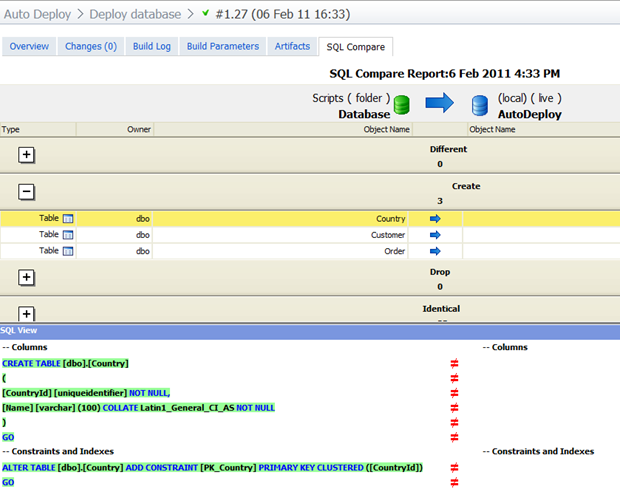
Здесь у нас есть хорошее визуальное представление трех таблиц, а затем требуемое изменение выбранной таблицы — таблицы «Страна», которая, конечно, просто приводит к сравнению с несуществующей сущностью. Теперь, почему мы не можем получить это и для SQL Data Compare ?!
Вот и все — полностью автоматизированное развертывание схемы и объектов одним нажатием кнопки. Но, конечно, чистый процесс CREATE и INSERT выполняется только в первый раз. Давайте сделаем это немного сложнее.
Как сборка обрабатывает изменения
Мы хотим продвинуть конверт немного дальше, поэтому давайте отойдем от комфортной зоны простой репликации исходной среды на другую красивую чистую цель. Вот изменения, которые я собираюсь сделать:
- Добавьте поле «PostCode» в таблицу «Customer»
- Измените столбец «Имя» в таблице «Страна» с varchar (100) на nvarchar (150)
- Удалите запись «Новая Зеландия» из таблицы «Страна» (очевидно, они просто станут другим штатом в Австралии)
- Уберите слово «Демократическая» из «Корея, Народно-Демократическая Республика» (давай, они никого не обманывают)
Отличительной особенностью SQL Compare 2 является то, что все вышеперечисленное можно использовать как одну транзакцию VCS. Это идеально для поддержания атомарной правильности базы данных — теперь, если только прикладной уровень может войти одновременно!
Давайте снова запустим все это и посмотрим на журнал сборки. Во-первых, что он находит со схемой:
Object type Name DB1 DB2 --------------------------------------------------------------------- Table [dbo].[Country] <> <> Table [dbo].[Customer] <> <>
Две противоположные угловые скобки указывают, что объекты не совпадают в исходном и целевом объектах, что верно для обеих таблиц. Просматривая артефакты, мы видим оператор ALTER COLUMN в таблице «Страна», за которым следует оператор ADD в таблице «Клиент». Здорово.
Теперь давайте посмотрим на данные:
Object type Name Records DB1 DB2 --------------------------------------------------------------------- Table [dbo].[Country] 242 == == Table [dbo].[Country] 1 <> <> Table [dbo].[Country] 1 <<
Таким образом, 242 записи синхронизируются идеально, одна отличается в обоих источниках, а одна существует только в цели. Правильно, правильно и правильно. Вернемся к артефактам и скрипт синхронизации данных показывает оператор DELETE для Новой Зеландии (извините, ребята) и оператор UPDATE для Северной Кореи. Отлично!
Это процесс изменений, который действительно иллюстрирует мощь этого механизма и, в частности, инструментов Red Gate. Вы можете позволить средам проходить через все виды изменений схемы и данных, а затем просто позволить сборке синхронизировать все это. Red Gate заботится о обычных проблемах, таких как ссылочная целостность и сохранение данных в течение всего изменения, поэтому для людей, ответственных за среду, это действительно так просто, как нажать кнопку запуска и подождать около дюжины секунд.
Это фантастический пример непрерывной интеграции и способности новой работы двигаться в другом направлении, не опасаясь возможности объединить все это вместе. Самое замечательное в этом то, что это также делает возврат изменений легким делом; Легко запустить сборку с более ранней ревизией, потому что вы знаете, что Красные Врата могут просто выявить различия и соответствующим образом записать их в сценарий.
Ломать сборку
Пока все это было гладко, но что происходит, когда что-то идет не так? Что произойдет, например, если я удалю страну из статических справочных данных, которые использовались клиентом в целевой среде? Давай выясним:
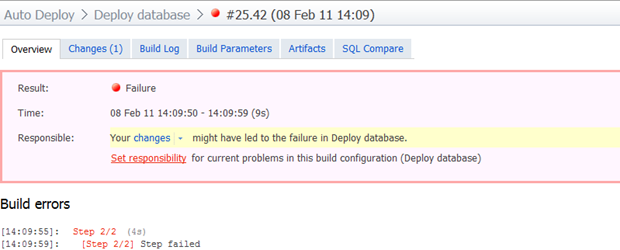
И если теперь мы углубимся в журнал сборки:
Error: Synchronization of 'Scripts.Database' and '(local).AutoDeploy' failed: The DELETE statement conflicted with the REFERENCE constraint "FK_Customer_Country". The conflict occurred in database "Autodeploy", table "dbo.Customer", column 'CountryId'.
Это именно то, что мы ожидаем увидеть, и это поднимает интересный момент; Будут времена, когда 100% автоматизация может быть невозможна. Если, например, Новая Зеландия действительно стала австралийским штатом (прекрати издеваться над предложением — я не придумал его ), и мы хотели соответствующим образом изменить все наши записи о клиентах, прежде чем удалять страну, возможно, будет несколько этапов процесса.
Конечно, мы могли бы начать весь сценарий и запускать только этот процесс в сборке через sqlcmd, и в некоторых средах другого пути быть не может, но он начинает становиться чем-то вроде анти-паттерна гибкости. Возможно, было бы проще упростить процесс сборки в пользу работы с тем, кто играет роль DBA. В конце концов, весь смысл этого процесса состоит в том, чтобы облегчить публикацию, а не ограничивать людей жесткими процессами.
Я нервничаю; Могу ли я увидеть изменения до их запуска?
Да, и это чрезвычайно просто сделать; просто удалите параметр / Sync. Видите ли, выполнение этого даст нам всю информацию, которую мы ранее получили в артефактах — а именно, предложенные сценарии изменений и отчет для SQL Compare — но на самом деле они не будут запускаться.
Реальная простота этого подхода заключается в том, что TeamCity предоставляет вам функцию «копирования» для простой репликации существующей конфигурации сборки, чтобы мы могли воспользоваться той, которую мы установили ранее, а затем просто удалить параметры с каждого шага сборки. Как только это будет сделано, вы можете запустить новую сборку, а затем просто сидеть сложа руки и впитывать результаты, не совершая никаких действий. Легко!
Сложная проблема триггера — решена!
В серии « Развертывание неверно» последовательность сборки была вызвана изменением VCS. Как я сказал в то время, вы, возможно, не всегда хотите делать это, но это был довольно аккуратный трюк на вечеринке, и он хорошо работает при определенных обстоятельствах (например, небольшая команда, развертывание в среде интеграции).
Именно здесь я раньше сетовал на тот факт, что для передачи схемы и данных в VCS потребовалось два коммита, и нужно было соблюдать осторожность, чтобы сделать это в правильном порядке, чтобы вы не попытались вставить данные в таблицу, которая не т еще не было создано. Но SQL Source Control 2 решает эту проблему, поскольку все идет как одна транзакция. Так что сработайте!
Одинокая мать всех сборок против связанных сборок
Ранее мы создали конфигурацию сборки в два этапа, чтобы можно было развернуть и схему, и данные. Но, конечно, имеет смысл связать это и с прикладным уровнем, что будет означать его связь со сборкой веб-развертывания. Это просто вопрос того, насколько это явно.
В одном углу мы могли бы сохранить полностью автономные конфигурации сборки и просто запускать одну из другой с зависимостью моментального снимка, чтобы гарантировать, что они извлекают из одной и той же ревизии. С другой стороны, поддержка нескольких этапов сборки TeamCity 6 (или классического MSBuild с шаблоном с несколькими задачами) может свести все это в одну сборку.
Лично мне модель со связанными сборками лучше подходит Начнем с того, что вы тянете из разных корней VCS, поэтому, если все это входит в одну сборку, вы должны получить уровень выше, а затем убедиться, что все ваши ссылки ссылаются на соответствующий путь «Приложение» или «База данных».
Тогда вы получите верность ошибок сборки; просто видеть красный в матерях всех тел не расскажет вам много о том, что пошло не так, не углубляясь в это. И после этого, что если вы просто хотите снова запустить развертывание БД, а не обязательно сборку приложения?
Конечно, ваш журнал сборки также становится чем-то вроде эпоса, и нужно больше думать об управлении артефактами. Кроме того, вы не можете распространять сборки веб-приложений и базы данных по разным агентам, что может пригодиться в будущем.
Единственная проблема со связанными сборками заключается в том, что если они запускаются коммитом VCS и существует зависимость от снимка ревизии, у вас будут проблемы, когда вам нужно будет сделать как веб-приложение, так и коммиты БД. На самом деле вы в конечном итоге запустите обе сборки дважды, поскольку вторая требует сборки первой с той же ревизией. В этой ситуации я бы, вероятно, просто отделил их и позволил изменениям корневого веб-приложения инициировать веб-развертывание, а корневому каталогу базы данных — инструменты Red Gate.
Работа с данными испытаний против чистого листа
Модель, описанная выше, отлично подходит для синхронизации схемы и данных в справочной таблице. Но как насчет других таблиц? Что мы хотим сделать с нашими клиентами и заказами?
Существует несколько различных вариантов использования, которые следует учитывать в зависимости от целевой среды и способа ее использования. Производство, например, легко — этот механизм работает отлично, поскольку он сохраняет все транзакционные данные, накопленные системой.
Среда тестирования в середине приемочного тестирования — это еще одно место, где применяется это правило. Если вам абсолютно необходимо вытолкнуть изменение в середине цикла тестирования, последнее, что вам нужно, это внезапное и неожиданное изменение состояния данных транзакционных таблиц.
Аналогично в среде разработки, если вы работаете в команде и совместно разрабатываете схему и справочные данные. Вы не хотите счастливо работать над своими собственными задачами, а затем принять замену от коллеги, и вдруг вы потеряли кучу фиктивных данных о клиентах.
Но бывают времена, когда подход к чистому государству желателен. Например, между циклами тестирования желательно очистить транзакционные данные с точки зрения начала тестирования из известного состояния данных. И если вы выполняете интеграционные тесты в любом месте с зависимостью от данных, абсолютно необходимо запускать их для предсказуемого набора данных.
Но это также не означает, что вы хотите, чтобы транзакционные таблицы были на 100% чистыми — вам могут потребоваться некоторые инициализированные данные, такие как учетные записи пользователей, чтобы даже иметь возможность войти в систему. Что вам действительно нужно, так это возможность создать сценарий инициализации, чтобы подготовить базу данных к вашим личным вкусам.
SQL Server на самом деле делает это очень просто, предоставляя утилиту sqlcmd, которая поставляется вместе со студией управления. Это позволяет нам удаленно выполнять сценарий, который можно легко извлечь непосредственно из VCS. В качестве примера я поместил следующий сценарий в папку «InitialiseData» в стволе хранилища:
DELETE FROM dbo.[Order] GO DELETE FROM dbo.[Customer] GO INSERT INTO dbo.Customer (CustomerId, [Name], Address, City, CountryId) SELECT NEWID(), 'Troy Hunt', '1 Smith St', 'Sydney', 'AA1DFC30-DD53-4BE5-A606-B595912C5C2B' GO
Затем я создал новую конфигурацию сборки в TeamCity, вызвав команду «C: \ Program Files \ Microsoft SQL Server \ 100 \ Tools \ Binn \ SQLCMD.exe» и передав следующие параметры:
-i %system.teamcity.build.checkoutDir%/InitialiseData/Clean.sql -S (local) -d AutoDeploy
Как и в предыдущих сборках, агент сборки в этом случае обладает необходимыми правами на SQL Server, поэтому все просто работает. Очевидно, что для этого также необходимо установить утилиту sqlcmd. Проверьте синтаксис команды в предыдущей ссылке, если вам действительно нужно передать учетные данные.
Очевидно, что это в значительной степени сборка «только по требованию», но теперь это означает, что мы можем автоматизировать полностью чистое состояние базы данных каждый раз, когда я хочу сбросить целевую среду. Или, в качестве альтернативы, можно запустить успешное развертывание в среде интеграции перед запуском автоматических тестов. Очень круто.
Тестирование на больших объемах данных
Пару недель назад я был вовлечен в проект, в котором был выпущен релиз для производственной среды, что привело к внезапному и неожиданному потоку времени ожидания SQL. Посмотрев на оскорбительную хранимую процедуру, не потребовалось много времени, чтобы понять, что она никогда не будет хорошо играть с большими объемами данных. Но как это могло быть? Он работал нормально на компьютере разработчика, и во время приемочного тестирования не было никаких результатов, что происходило?
Простая разница между этими средами заключалась в объеме данных. Несмотря на то, что среда тестирования ранее была заполнена большим количеством записей, производственная среда превзошла это на порядок. И как раз перед тем, как мы пойдем дальше, никогда не будет нормальным переносить производственные данные в любую другую среду для тестирования производительности. Там должен быть лучший способ…
И вот оно; Генератор данных SQL Red Gate . Этот щенок может развернуться и заполнить вашу базу данных корпоративного уровня с 10 миллионами реалистичных записей в мгновение ока. Он идеально подходит для инициализации БД с достаточным количеством данных, чтобы продемонстрировать производительность в будущем цикле роста приложения.
Как оно работает? На сайте Red Gate есть несколько замечательных демонстраций, которые подробно описаны, но вкратце, они рассматривают имена столбцов и типы данных, а затем используют комбинацию регулярных выражений и статических данных для таких вещей, как города, и используют их для создания реалистичного набора данные. Вы также можете предоставить свой каждый из них, если хотите получить более конкретную информацию (возможно, только в городах Китая), и все это учитывает ограничения ссылочной целостности, так что внешний ключ «CountryId» всегда будет иметь действительный значение основано на записях таблицы «Страна».
Как и в случае SQL Compare и Data Compare, мы собираемся выполнить это на сервере сборки. Однако мы не можем просто ввести в командной строке некоторые параметры; этот требует настройки непосредственно в приложении Data Generator. Это имеет смысл, хотя; вы просто не сможете передать конфигурацию, необходимую для успешного запуска инструмента через командную строку.
Так что это на сервер TeamCity, и мы запустим Data Compare. Конфигурация проекта очень проста, и пока мы будем держаться подальше от других вкладок:
Здесь происходит волшебство; настройка генератора данных:
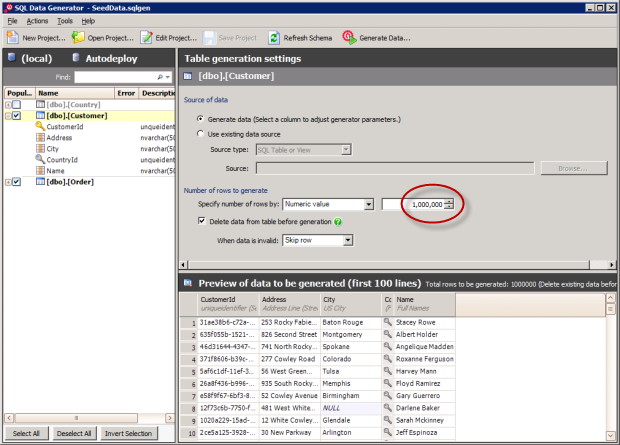
As you can see from the “Preview of data to be generated”, this is pretty realistic looking data. You’ll also see I’m going to generate one million records – I’m not one to do things by halves and to that effect I’m also going to generate two and a half million orders. Very cool.
Once this has been configured I’m going to save the solution file into a new “TestData” folder in the trunk of the repository and call it “Generate.sqlgen”. I’ll just check that folder out to a location on the build server and save the configuration there so it’s easy to come back to and reconfigure later on. The most important thing is that we need to get it committed back to VCS as this has now become an essential component of the project.
This activity doesn’t have to be done on the build server; the project could just as easily be created on a PC. But of course this necessitates an additional license so assuming you’re happy to provide remote access to the build server – and this often won’t be the case – this makes things a little more cost effective.
I won’t go into the detail of every screen in the build (you’ve seen enough of that earlier on), but essentially this works in a near identical fashion to the earlier ones. Call it “Generate test data”, instruct the VCS checkout rule to grab the file from the “TestData” folder in the trunk and save it in a local path of the same name, then configure the build to run the “C:\Program Files\Red Gate\SQL Data Generator 1\SQLDataGenerator.exe” command.
The parameters are pretty basic for this one:
/project:%system.teamcity.build.checkoutDir%/TestData/Generate.sqlgen /verbose
There are no artifacts to be generated and nothing else worth configuring for this build. All that’s left to do is to run it. Everything goes green and we get the following in the build log:
Start time: Tuesday, 8 February 2011 06:50:33 AM End time: Tuesday, 8 February 2011 06:53:16 AM [dbo].[Customer] Rows inserted: 1000000 [dbo].[Order] Rows inserted: 2500000
Have a good look at this – we just generated three and a half million records of test data in two and a half minutes. In a virtual machine running on a PC. Whoa. Is this for real?
SELECT COUNT(*) FROM dbo.[Customer] SELECT COUNT(*) FROM dbo.[Order]
And we see:
- 1000000
- 2500000
That should last us for a while. So this is real-ish test data, generated on demand against a clean deployment by a single click of the “Run” button from a remote machine. Test data doesn’t get any easier than that.
Summary
Achieving a reliable, repeatable continuous integration build for the database was never going to be straight forward without investing in some tools. The fact that purely on its own merits, SQL Source Control stood out as the best way of getting the DB schema into Subversion – even before they added the static data capabilities – made the selection of the other Red Gate tools a very easy decision.
It’s a similar story with SQL Compare and Data Compare; I’ve used these for years (since 2004, by my records), and they’re quite simply the best damn thing you can do with your money if you’re regularly involved in deployments. The ability for these tools to integrate with SQL Source Control and run autonomously on the build server makes them an easy choice.
Purchased separately, the build server dependencies – SQL Compare, Data Compare and Data Generator – cost $1.5k. Spend that instead on the SQL Developer Bundle and you get a spare license of SQL Source Control (normally $300) and a few other bits as well (SQL Prompt is especially nice – decent intellisense for SSMS), that you can give to your favourite developer rather than buying a standalone license.
To be honest, the price is a bit inconsequential in the context of any rational look at what the tools are doing. Manual database migrations can be quite laborious, very error prone and extremely bad news when they go wrong. The ability to do all this automatically in a fraction of the time and in unison with web app deployment just by a single button click is absolute gold and in my humble opinion, worth every cent of the asking price.
Resources
Source: http://www.troyhunt.com/2011/02/automated-database-releases-with.html