Для архивирования ваших данных в AWS вы можете использовать AWS Glacier . Этот сервис предлагает более дешевое хранилище, чем сервис S3, но недостатком является то, что ваши данные не будут доступны сразу же, как в S3. Восстановление данных может занять несколько часов, но если вы используете этот сервис для реальных целей архивирования, это не должно быть реальной проблемой. Позволяет настроить Glacier Vault с помощью консоли управления . Выберите сервис Glacier в консоли управления:
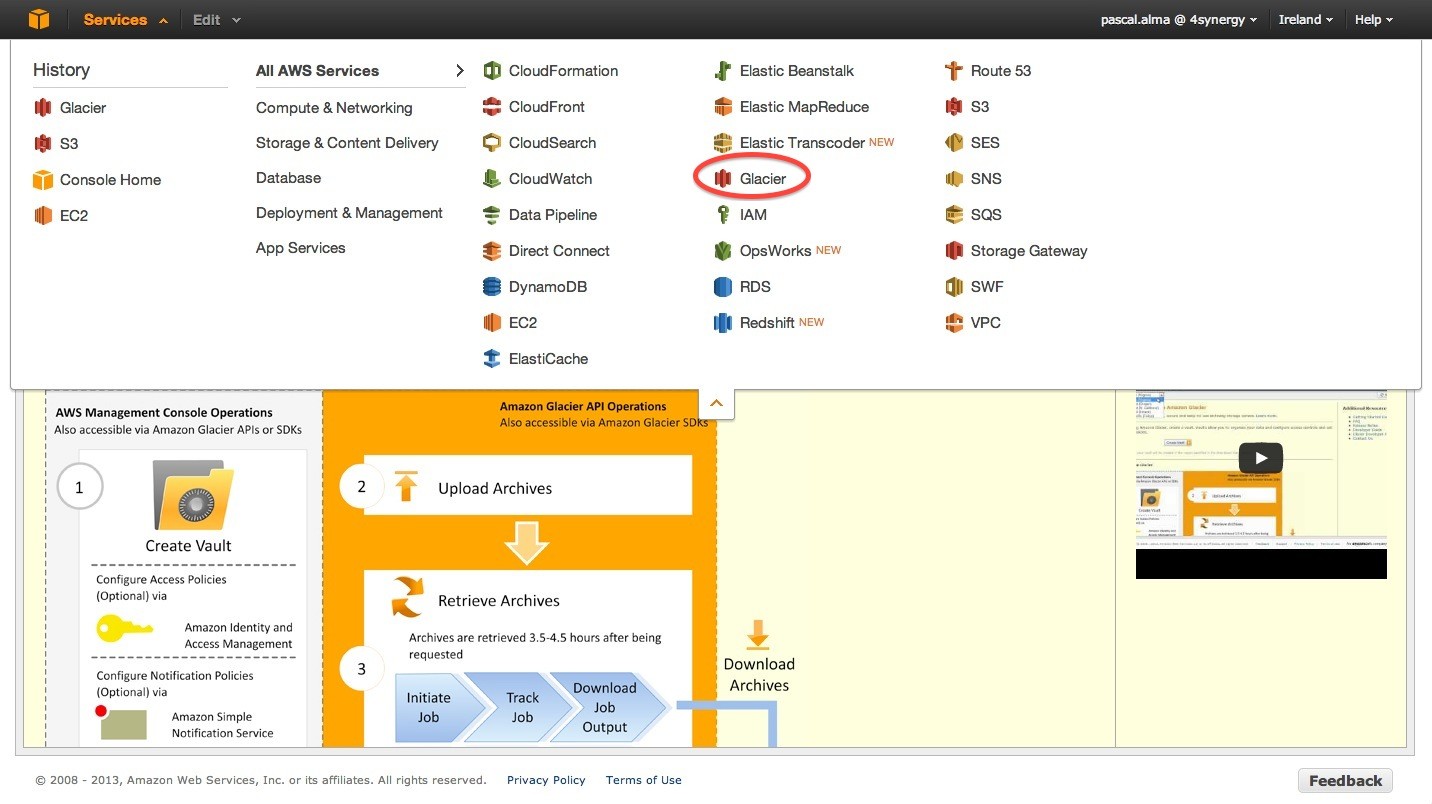
Нажмите «Создать хранилище» и дайте ему имя:
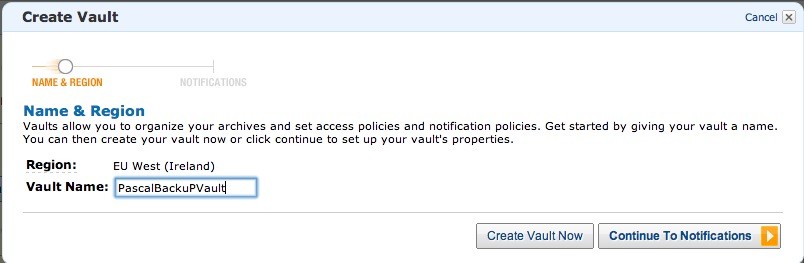
Установите новую тему SNS, чтобы мы могли получать сообщения, когда действия по архивированию завершены.
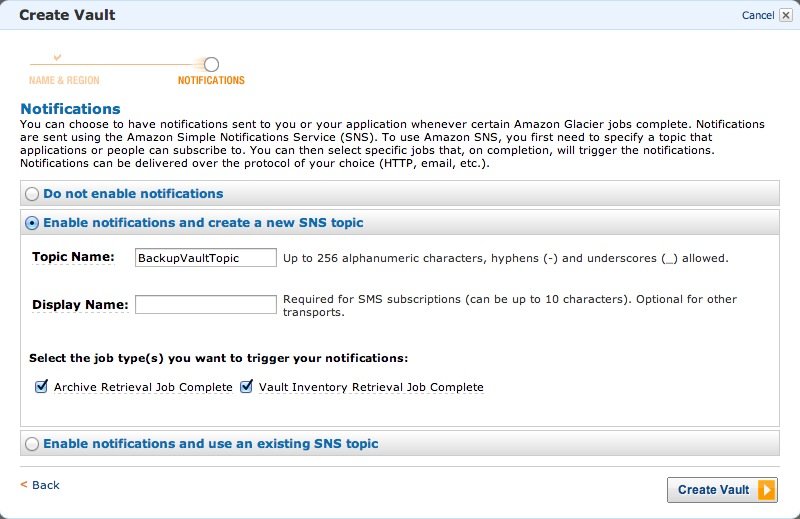
Если все прошло хорошо, Хранилище создано:
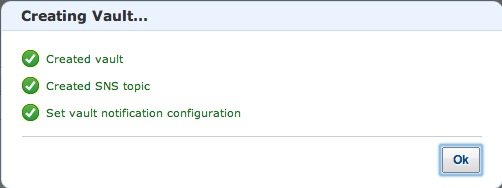
Вместе с хранилищем также создается новый SNS. Чтобы получать сообщения, размещенные на SNS, давайте подпишемся на него. Выберите сервис SNS в консоли:
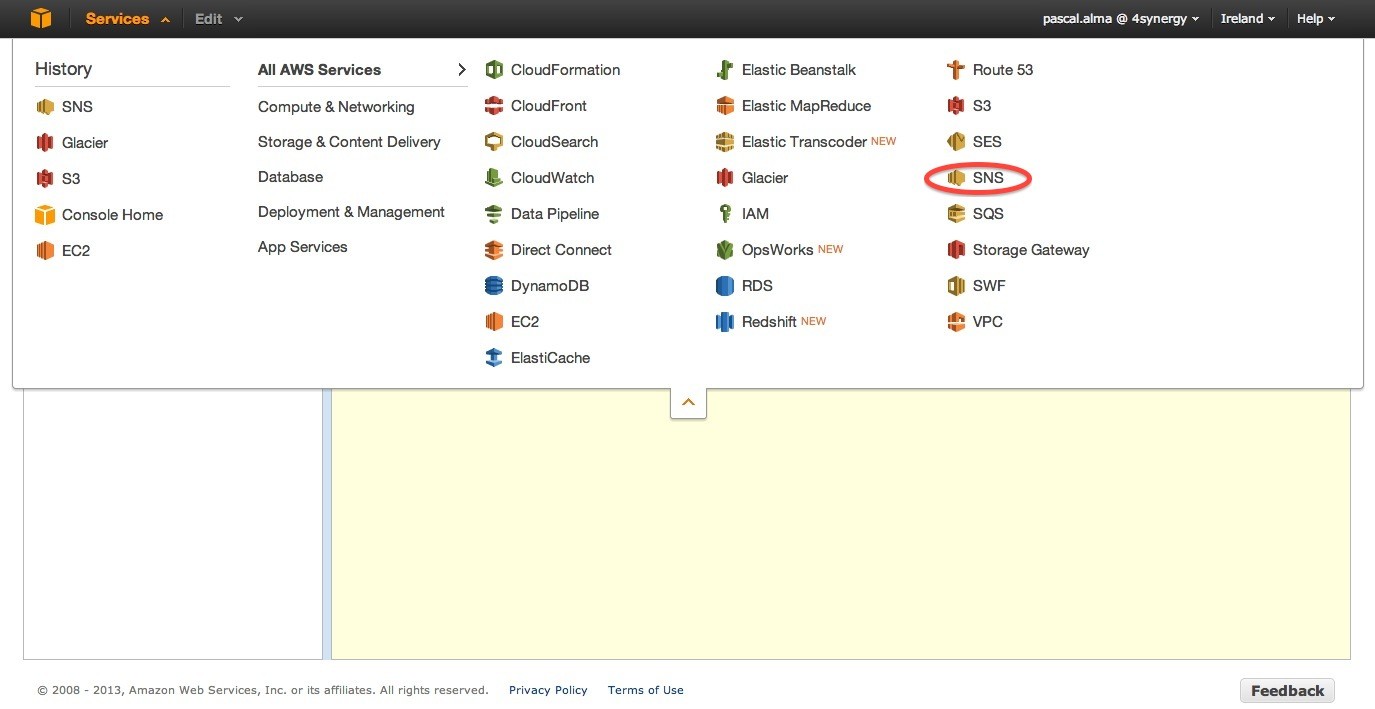
Выберите тему SNS, которая только что была создана:
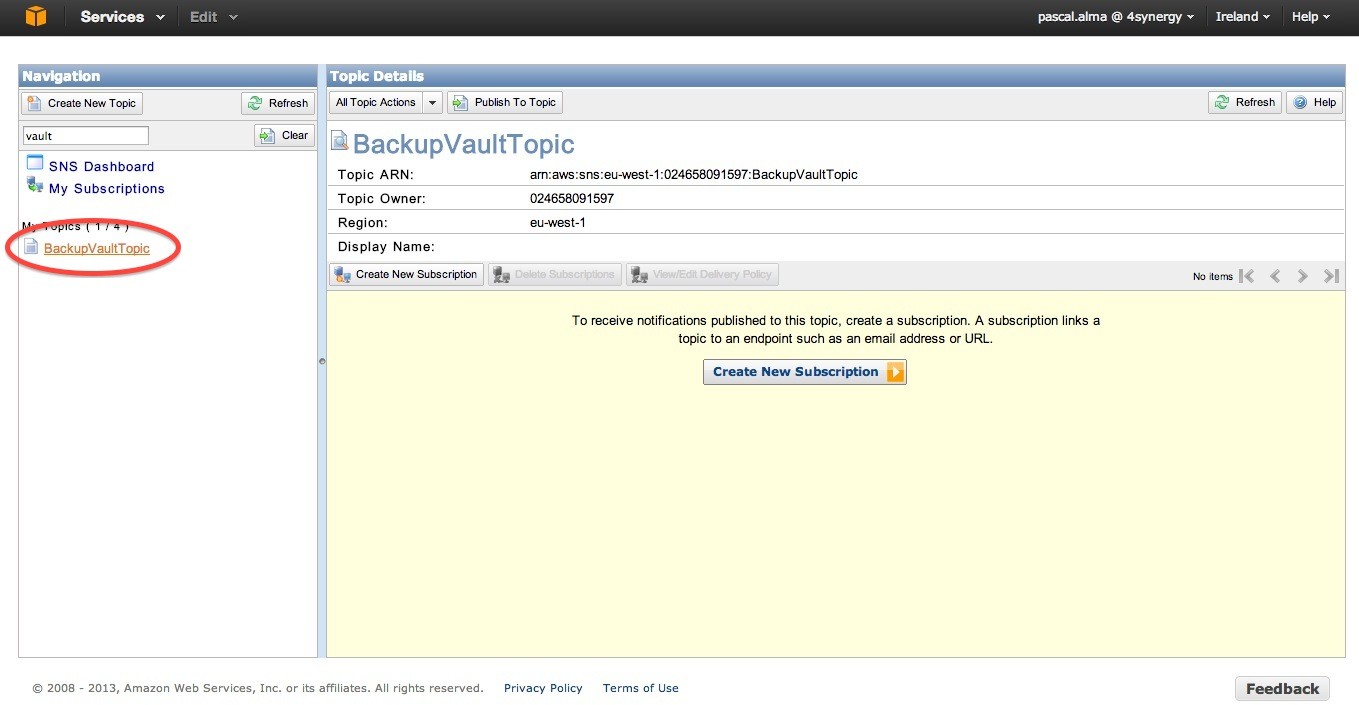
Теперь нажмите на кнопку, чтобы создать подписку на эту тему. Я просто создаю подписку по электронной почте, чтобы каждое сообщение, опубликованное в теме, отправлялось на указанный адрес электронной почты:
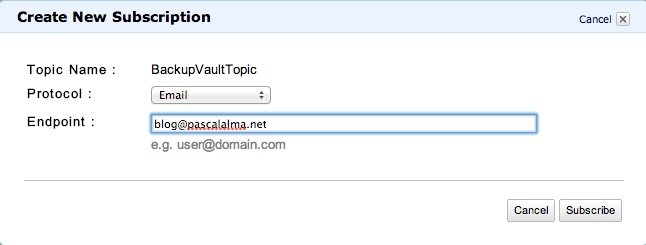
Служба Glacier в Консоли управления не поддерживает функцию архивирования / восстановления файлов в Glacier и из него (как это происходит в S3). Но, конечно, есть API для использования и несколько SDK для передачи файлов. И, конечно, есть сообщество, которое вмешалось в это и создало множество инструментов на основе GUI и CLI. Я просто выбрал один из них и установил его.
После установки и настройки Glacier-cli я могу проверить, найдено ли созданное хранилище:
|
1
2
|
pascal$ ./glacier.py --region eu-west-1 vault listPascalBackuPVault |
Позволяет положить некоторые данные в хранилище. Я использую пример инструмента CLI в качестве вдохновения. Создайте локальный файл:
|
1
|
pascal$ echo 42 > example.txt |
Загрузите файл в хранилище, созданное ранее:
|
1
|
pascal$ ./glacier.py --region eu-west-1 archive upload PascalBackuPVault example.txt |
Давайте проверим, находится ли файл в хранилище:
|
1
2
|
pascal$ ./glacier.py --region eu-west-1 archive list PascalBackuPVaultexample.txt |
Теперь удалите локальный файл и восстановите архив:
|
1
2
3
4
5
6
7
8
|
pascal$ rm example.txtpascal$ ./glacier.py --region eu-west-1 archive retrieve PascalBackuPVault example.txtglacier: queued retrieval job for archive 'example.txt'pascal$ ./glacier.py --region eu-west-1 archive retrieve PascalBackuPVault example.txtglacier: job still pending for archive 'example.txt'pascal$ ./glacier.py --region eu-west-1 job lista/p 2013-05-20T18:40:25.107Z PascalBackuPVault example.txtpascal$ ./glacier.py --region eu-west-1 archive retrieve --wait PascalBackuPVault example.txt |
Через несколько часов работа завершена, и мы снова можем получить доступ к локальному файлу «example.txt».
|
1
2
|
pascal$ cat example.txt42 |
И в письме я нахожу следующее уведомление о том, что архивный файл готов к поиску:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
{"Action":"ArchiveRetrieval","ArchiveId":"CggVcXvaWKfRn5tDR_UKna0GsYyXyZzlALPvjEFkcLdRq4NRBXra36m7hBOJSNCbOmEkQ04VoyTQyMt_pXdrNggms13e3vjUqwW3tZwps8BiA1gprQQZyUQPDwwWkuKAFZoqahzA-g","ArchiveSHA256TreeHash":"084c799cd551dd332d5c5f9a5d593b2e931f5e36122ee5c793c1d08a19839cc0","ArchiveSizeInBytes":3,"Completed":true,"CompletionDate":"2013-05-20T22:40:31.040Z","CreationDate":"2013-05-20T18:40:25.107Z","InventorySizeInBytes":null,"JobDescription":null,"JobId":"rxRUKT0QVWyOEMu4VYW_zrhXXYZC0ZrVo63sCtQJDBpFyhO-pPRJ7Z_Af02Hvn-bge-yGrKzRw78xG9d-Nvxjv2LcQho","RetrievalByteRange":"0-2","SHA256TreeHash":"084c799cd551dd1d6e535f9a5d593b2e931f5e36122ee5c793c1d08a19839cc0","SNSTopic":null,"StatusCode":"Succeeded","StatusMessage":"Succeeded","VaultARN":"arn:aws:glacier:eu-west-1:678658091597:vaults/PascalBackuPVault"}--... |
Конечно, о AWS Glacier можно рассказать гораздо больше. Эта страница станет хорошим следующим шагом для знакомства с Glacier.