Первоначально созданный Мартином Шустриком,
я провел в прошлом месяце переписывание кода nanomsg для внутреннего использования конечных автоматов, передавая асинхронные события вместо использования случайных обратных вызовов между компонентами. Изменение является сложным, требует большой работы и невидимо для конечного пользователя, поэтому вопрос: зачем это вообще нужно? Можно уделить время более эффективному использованию новых привлекательных функций, которые сделают пользователей счастливыми. Вместо этого прогресс в библиотеке кажется застопорившимся, и такое серьезное переписывание может даже привести к регрессам. Зачем вообще беспокоиться?
Я постараюсь дать ответ в этой статье. Он вводит общий аргумент против обратных вызовов, поэтому, если вы используете обратные вызовы, прочитайте его, даже если вы не заинтересованы в nanomsg как таковом. Кстати, обратите внимание, что я не собираюсь говорить ничего нового здесь. Знания существуют буквально десятилетия. Тем не менее, учитывая объем программирования, основанного на обратном вызове, который уже сделан и очевиден — хотя и совершенно непонятен для меня — стремление некоторых пользователей ZeroMQ и nanomsg к API на основе обратного вызова, я считаю, что повторение основ было бы полезно.
Проблема в том, что кодовая база ZeroMQ эволюционировала до такой степени, что внутренние взаимодействия внутри библиотеки настолько сложны, что добавить любую новую базовую функциональность стало практически невозможно. Например, хотя библиотека существует уже 6 лет, в течение этого времени не было добавлено ни одного нового транспортного механизма. Было много попыток, но ни одна из них не смогла обеспечить полностью стабильный код, который можно было бы объединить с основной линией. Вместо этого люди прибегают к наведению мостов между ZeroMQ и другими транспортами.
Одна из целей nanomsg состояла в том, чтобы улучшить внутреннюю архитектуру библиотеки таким образом, чтобы было легко добавить новые функции. В первой итерации я снова попытался избежать конечных автоматов (в следующей статье я попытаюсь объяснить, почему), и у меня ничего не получилось. Сложность постепенно подкралась. Кажется, что единственный способ держать сложность в страхе — избегать обратных вызовов.
Рассмотрим этот код:
struct A
{
void foo () {b->baz ();}
void bar () {++i;}
B *b;
int i;
}
struct B
{
void baz () {a->bar ();}
A *a;
};
Это довольно просто. A имеет указатель на B и наоборот. Если вы вызываете A :: foo, он вызывает B :: baz, который, в свою очередь, вызывает A :: bar. A :: bar увеличивает значение переменной-члена A. Там нет никакой ловушки. Программа будет работать как положено.
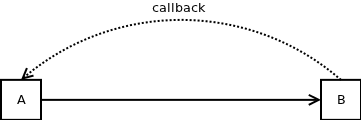
Однако представим, что мы сделаем A :: foo немного более сложным:
void A::foo ()
{
int tmp = i;
b->baz ();
assert (tmp == i);
}
Мы копируем переменную члена класса в локальную переменную и вызываем функцию. В этом нет ничего плохого. Однако сразу после этого мы сделаем проверку работоспособности и проверим, равна ли локальная переменная переменной-члену. Удивительно, но это не так. Значение переменной-члена таинственным образом изменилось только потому, что мы вызвали метод другого объекта.
Конечно, в этом примере легко определить, что пошло не так. Мы можем решить проблему простым способом. Например, мы можем перечитать значение переменной-члена в локальную переменную после вызова:
void A::foo ()
{
int tmp = i;
b->baz ();
tmp = i;
assert (tmp == i);
}
Теперь программа работает как положено. Похоже, эти надоедливые обратные вызовы не так уж и сложны!
Ну, не совсем. Далее я попытаюсь объяснить, почему приведенный выше код — это брезент, который просто ждет, чтобы съесть вас заживо.
Во-первых, представьте, что обратный вызов происходит в более сложной настройке. Объект A вызывает объект B, который вызывает объект C, который вызывает объект D, который вызывает объект E, который, в свою очередь, вызывает объект A.
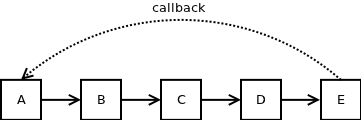
Совершенно очевидно, что обработка обратного вызова в этом случае будет намного более сложной. Проблема связана с тем фактом, что когда A вызывает B, он не имеет представления о том, что там, с вложенными пятью уровнями глубины, есть обратный вызов A. Таким образом, когда вызов B возвращается, разработчик будет искренне удивлен, что состояние А тем временем мутировал.
Если бы в каждой функции был только один вызов, как показано на рисунке выше, то есть вызов B был бы единственным вызовом функции в A, вызов C был бы единственным вызовом функции в B и т. Д., Обнаружение цикла было бы все еще возможное. Однако предположим, что каждая функция содержит в среднем три вызова функций. Это означает, что там, на глубине пяти уровней, находятся 243 функции, одна из которых может быть, а может и не быть, обратным вызовом A. Подобные вещи очень трудно обнаружить, просто взглянув на код.
Кроме того, многие функции в графе вызовов вызываются только тогда, когда выполняется определенное условие, а некоторые из этих условий довольно редки. Если путь от A до A содержит несколько редких условий, вероятности умножаются и обратный вызов почти никогда не произойдет. Таким образом, даже при широком тестировании вполне возможно, что обратный вызов никогда не сработает, и проблема, которую он вызывает, пройдет тестирование незамеченным — только для того, чтобы произойти в производстве, предположительно в самый неподходящий момент.
Добавьте к этому, что циклы обратного вызова часто не 5, а 10 или 15 шагов. В такой среде практически невозможно убедиться, что программа будет вести себя прилично. Лучшее, что вы можете сделать, это провести некоторое тестирование, затем отправить продукт, а затем исправить ошибки, о которых сообщили пользователи. Даже в этом случае вы можете быть уверены, что в базе кода все еще есть редкие ошибки.
Я собираюсь предположить, что к настоящему времени я убедил вас, что длинные циклы в графе вызовов — действительно плохая идея. Итак, вернемся к нашему первоначальному примеру. A вызывает B, который в свою очередь перезванивает A. Это самый простой возможный случай обратного вызова. Цикл сразу виден, разработчик может тщательно настроить его на работу при любых обстоятельствах. Он может задокументировать цикл и поместить большой комментарий ПРЕДУПРЕЖДЕНИЕ перед каждым вызовом функции, чтобы ни один будущий сопровождающий базы кода не мог случайно пропустить его. Что может пойти не так?
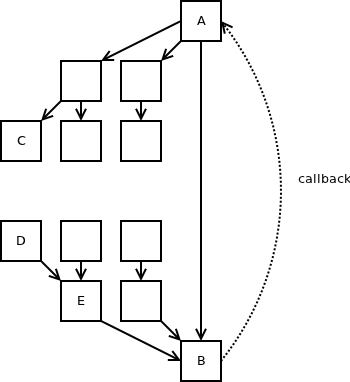
Проблема в том, что в любом реалистичном сценарии граф вызовов намного сложнее, чем простой двухузловой граф, как показано в верхней части этой статьи. Есть другие функции, вызываемые A, и B вызывается также из других функций:
Теперь представьте, что в какой-то момент в будущем какой-нибудь случайный разработчик добавит вызов из C в D. Он даже не знает о существовании A и B, не говоря уже о цикле между ними. Тем не менее, изменение вводит новый цикл из 6 узлов:
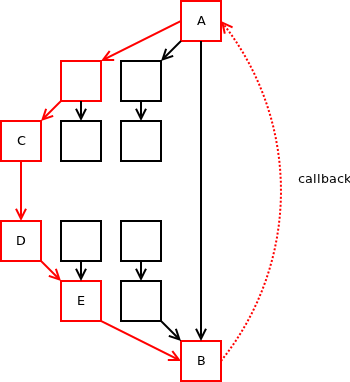
Внезапно может случиться так, что компонент E делает вызов B — который работал без проблем прежде — и находит свое собственное состояние измененным, когда функция возвращается. Что, конечно, делает его неудачным или, что еще хуже, ведет себя плохо.
Чтобы понять масштаб проблемы, которую мы создали, рассмотрим следующее: разработчик C внес локальное изменение в C. Изменения взаимодействовали с небольшим циклом в совершенно не связанной подсистеме и создали большой цикл, который, в свою очередь, вызывает еще и другое совершенно не связанный компонент (E) потерпит неудачу. Теперь давайте предположим, что разработчик C, разработчик A & B и разработчик E — это три разных человека, возможно, даже работающих в разных отделах или — если используются сторонние библиотеки — в разных компаниях. Совершенно разумные изменения, внесенные первым разработчиком, плохо взаимодействуют с кодом, написанным 15 лет назад вторым разработчиком, и приводят к ошибке, сообщаемой третьему разработчику, работающему в другой компании в некоторой отдаленной стране, и даже не говорящему по-английски. Я бы предпочел не быть в шкуре этого парня.
Распространенным способом решения проблем, вызванных циклами в графе вызовов, является введение новой переменной класса («executing»), которая включается, когда объект уже используется, и выключается, когда это не так. Посредством проверки этой переменной компонент может идентифицировать случай, когда в стеке вызовов есть цикл, и обработать случай соответствующим образом.
Ниже приведен простой пример такого кода. выполнения и я переменные — члены класса А . Если функция вызывается в цикле, она ничего не делает. Если цикла нет, он увеличивает переменную i :
void A::foo ()
{
if (executing)
return;
executing = true;
++i;
executing = false;
}
Этот подход может помочь избавиться от конкретной ошибки, но это хакерское решение, которое может вызвать еще больше проблем в будущем. Представьте, что код изменен так:
void A::foo ()
{
if (executing) {
delete this;
return;
}
executing = true;
b->bar ();
executing = false;
}
void B::bar ()
{
a->foo ();
}
Можете ли вы определить проблему?
Программа не сможет получить доступ к неверной ячейке памяти при выполнении executing = false . Мы не можем по-настоящему дотронуться до члена, потому что объект может измениться, пока мы выполняем вызов b-> bar (), и «изменение» может фактически означать, что он освобождается.
Единственное реальное решение здесь — отложить обратный вызов. Просто отметить, что он должен быть выполнен, и выполнить его позже, когда завершится вызов A :: foo () . И это, конечно, первый шаг к полному подходу конечного автомата.
Если вам интересна эта тема, в Интернете есть много литературы о конечных автоматах, а также множество инструментов, которые помогут вам в их реализации. Я также хотел бы изучить этот вопрос подробнее в этом блоге. В частности, меня интересуют два вопроса: во-первых, почему разработчики готовы перепрыгивать через обручи только для того, чтобы избежать использования конечных автоматов? Во-вторых, есть ли хорошие практические правила (в отличие от реальных программных инструментов), которые разработчик должен учитывать при реализации конечного автомата?
Оставайтесь в курсе.