Недавно мой коллега рассказал мне о нескольких преимуществах Кассандры, и я решил попробовать. Apache Cassandra описана в разделе «Краткое введение в Apache Cassandra» как «одна из самых популярных на сегодняшний день баз данных NoSQL». Главная страница для Apache Cassandra утверждает , что « Apache Cassandra базы данных является правильным выбором , когда вам нужно масштабируемость и высокую доступность без ущерба для производительности.» Cassandra используется такими компаниями , как eBay , Netflix , Adobe , Reddit , Instagram и Twitter, Этот пост представляет собой краткое изложение шагов для начала работы с Cassandra .
Apache Cassandra можно загрузить с главной веб-страницы Apache Cassandra . На странице загрузки указано, что «последняя стабильная версия Apache Cassandra — 2.0.7 (выпущена 2014-04-18)», и эту версию я буду обсуждать и использовать в этом посте.
Для этого поста я скачал и установил DataStax Community Edition с сайта Planet Cassandra Downloads . В состав DataStax Community 2.0.7 входит «Самая стабильная и рекомендуемая версия Apache Cassandra для производства (2.0.7)». Доступны загрузки DataStax Community Edition для Mac OS X , Microsoft Windows и нескольких версий Linux .
На следующем снимке экрана показан список каталогов для каталога «bin» Apache Cassandra, включенного в установку DataStax Community Edition.

Из этого каталога «bin» сервер Cassandra можно запустить, просто запустив соответствующий исполняемый файл. В случае этого единственного компьютера с Windows эта команда, cassandra.batи этот шаг показан на следующем снимке экрана.

Интерактивный инструмент командной строки cqlsh также находится в подкаталоге Apache Cassandra «bin». Этот инструмент похож на SQL * Plus для баз данных Oracle , mysql для баз данных MySQL и psql для PostgreSQL . Это позволяет вводить различные операторы CQL ( Cassandra Query Language ), такие как вставка новых данных и запрос данных. Запуск cqlsh из командной строки на компьютере с Windows показан на следующем снимке экрана.
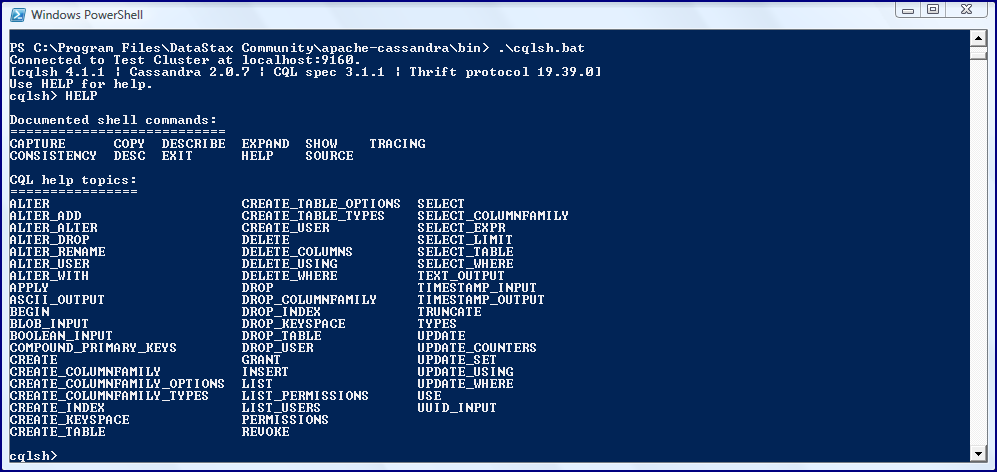
Есть несколько полезных наблюдений, которые можно сделать из предыдущего изображения. Как cqlshвидно из результатов запуска , эта версия Apache Cassandra — 2.0.7, эта версия cqlsh— 4.1.1, а соответствующая спецификация CQL — 3.1.1 . Непосредственно предыдущий снимок экрана также демонстрирует помощь, предоставленную с помощью команды «HELP». Мы видим, что есть несколько «документированных команд оболочки», а также еще больше «разделов справки по CQL».
Предыдущий снимок экрана продемонстрировал, что команда «help» в cqlsh перечисляет отдельные разделы, по которым команда help может быть специально запущена. Например, следующий снимок экрана демонстрирует вывод запущенных «типов справки» в cqlsh.

В этом снимке экрана, мы видим типы данных CQL , которые поддерживаются в cqlsh , таких как ascii, text/ varchar, decimal, int, double, timestamp, list, set, и map.
Пространства клавиш в Кассандре
Пространства ключей важны в Кассандре. Хотя этот пост охватывает Cassandra 2.0, документация Cassandra 1.0 хорошо объясняет пространства ключей в Cassandra: «В Cassandra пространство ключей является контейнером для данных вашего приложения, аналогично схеме в реляционной базе данных. Пространства ключей используются для группировки семейств столбцов вместе. Обычно кластер имеет одно пространство ключей на приложение. » В этой документации объясняется, что пространства ключей обычно используются для группировки семейств столбцов по стратегии репликации. Следующий снимок экрана демонстрирует создание пространства ключей в cqlshи перечисляет доступные пространства ключей.

Последний снимок экрана включал пример использования команды SELECT * FROM system.schema_keyspaces; чтобы увидеть доступные пространства клавиш. Когда кто-то просто хочет получить список имен доступных пространств клавиш без всех других деталей, легко использовать пространства клавиш desc, как показано на следующем снимке экрана.

Создание семейства столбцов («Таблица»)
With a keyspace created, a column family (or table) can be created. The next screen snapshot demonstrates using the newly created movies_keyspace with the use movies_keyspace; statement and then shows using the cqlsh command SOURCE (similar to using @ in SQL*Plus) to run an external file to create a table (column family). The screen snapshot demonstrates listing available tables with the desc tables command and listing specific details of a given table (MOVIES in this case) with the desc table movies command.
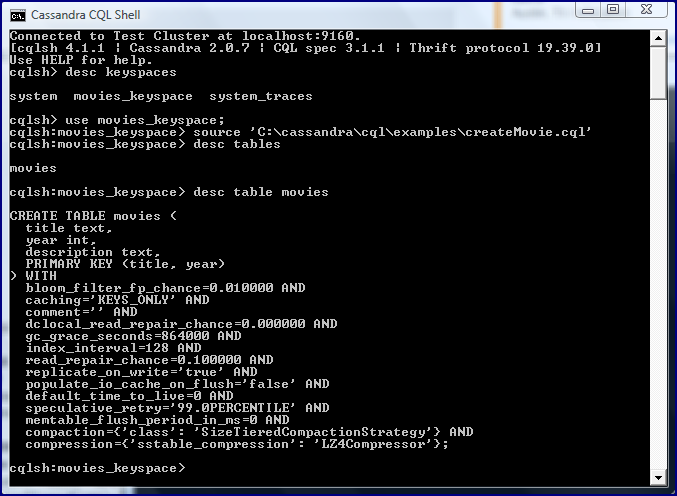
The above screen snapshot demonstrated running an external file called createMovie.cql using the SOURCE command. The code listing for the createMovie.cql file is shown next.
CREATE TABLE movies
(
title varchar,
year int,
description varchar,
PRIMARY KEY (title, year)
);
Inserting Data into and Querying from the Column Family
The next screen snapshot demonstrates how to insert data into the newly created column family/table [insert into movies_keyspace.movies (title, year, description) values ('Raiders of the Lost Ark', 1981, 'First of Indiana Jones movies.');]. The image also shows how to query the column family/table to see its contents [select * from movies].

Cassandra is NOT a Relational Database
Looking at the Cassandra Query Language (CQL) statements just shown might lead someone to believe that Cassandra is a relational database. However, CQL is a relational-like feature added to Cassandra 2.0 intended to help people with SQL expertise more readily adopt Cassandra. Similarly, triggers are being added in 2.0/2.1. Despite the presence of these Cassandra features intended to make it easier for relational database users to adopt Cassandra, there are significant differences between Cassandra and a relational database.
The Cassandra Data Model is a page in the Apache Cassandra 1.0 Documentation that describes some key differences between Cassandra and relational databases. These include:
- «Cassandra does not enforce relationships between column families the way that relational databases do between tables»
- There are no foreign keys in Cassandra and there is no «joining» in Cassandra.
- Denormalization is not a shameful thing in Cassandra and is actually welcomed to a certain degree.
- Cassandra «table» (column family) modeling should be done based on expected queries to be used.
Conclusion
I’ve just begun to get my feet wet with Cassandra but look forward to learning more about it. This post has focused on some basics of acquiring and starting to use Cassandra. There is much to learn about Cassandra and some «deeper» topics that really need to be understood to truly appreciate Cassandra include Cassandra architecture (and here), Cassandra Data Modeling (and here), and Cassandra’s strengths and weaknesses.