Apache Spark предоставляет широкие возможности и возможности больших данных и аналитики в реальном времени . Имея это в виду, давайте представим Apache Spark в этом кратком практическом руководстве. Это введение в Apache Spark, часть 1 из 4.
Эта статья о Spark состоит из четырех частей:
- Часть 1 Введение в Spark, как использовать оболочку и RDD.
- Часть 2 Spark SQL, Dataframes и как заставить Spark работать с Cassandra.
- Часть 3 Введение в MLlib и Streaming.
- Часть 4 GraphX.
Это часть 1.
Для полной аннотации и схемы, пожалуйста, посетите наш веб-сайт Apache Spark QuickStart для анализа данных в режиме реального времени .
На сайте вы также можете найти много других статей и учебных пособий, таких как; Java Reactive Microservice Training , Архитектура микросервисов | Консульство Обнаружение службы и здоровье для микросервисной архитектуры Учебник . И многое другое. Проверьте это.
Spark Обзор
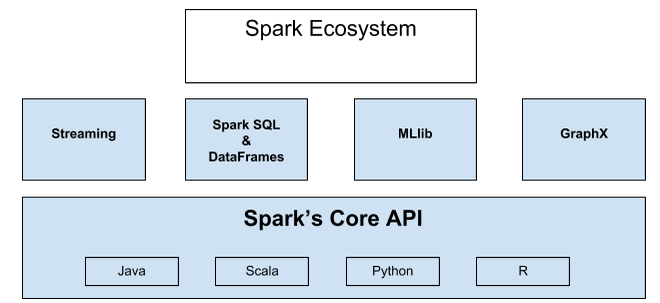
Apache Spark, кластерная вычислительная система с открытым исходным кодом, быстро развивается. Apache Spark имеет растущую экосистему библиотек и фреймворков для расширенной аналитики данных. Быстрый успех Apache Spark объясняется его мощью и простотой использования. Он более продуктивен и имеет более быстрое время выполнения, чем типичная аналитика на основе MapReduce BigData . Apache Spark обеспечивает распределенные вычисления в памяти. Он имеет API в Java, Scala, Python и R. Экосистема Spark показана ниже.

{kind=link}
Вся экосистема построена на ядре ядра. Ядро обеспечивает скорость вычислений в памяти, а его API поддерживает Java, Scala, Python и R. Потоковая передача позволяет обрабатывать потоки данных в режиме реального времени. Spark SQL позволяет пользователям запрашивать структурированные данные, и вы можете делать это на своем любимом языке. DataFrame находится в ядре Spark SQL, он хранит данные в виде набора строк и каждый столбец в строке именуется, а с помощью DataFrames вы можете легко выбрать, построить и отфильтровать данные. MLlib — это среда машинного обучения. GraphX - это API для структурированных данных графа. Это был краткий обзор экосистемы.
Немного истории об Apache Spark:
-
Первоначально разработанный в 2009 году в лаборатории UC Berkeley AMP, он стал открытым исходным кодом в 2010 году, а теперь является частью Apache Software Foundation.
-
Имеет около 12 500 коммитов, сделанных около 630 участниками ( как видно из репозитория Apache Spark Github ).
-
В основном написано на Scala .
-
Интерес к поиску Google для Apache Spark в последнее время резко возрос, что свидетельствует о широком круге интересов. (108 000 поисковых запросов в июле по данным Google Ad Word Tools примерно в десять раз больше, чем у Microservices ).

-
Некоторые из дистрибьюторов Spark: IBM, Oracle, DataStax, BlueData, Cloudera …
-
Некоторые приложения, созданные с использованием spark: Qlik, Talen, Tresata, atscale, platfora …
-
Некоторые из компаний, которые используют Spark: Verizon , NBC , Yahoo, Spotify …
Причина, по которой люди так заинтересованы в Apache Spark, заключается в том, что он предоставляет всю мощь Hadoop в руки разработчиков. Кластер Apache Spark проще настроить, чем кластер Hadoop. Это работает быстрее. И это намного проще для программирования. Он предоставляет широкие возможности и возможности больших данных и анализа в реальном времени. Имея это в виду, давайте представим Apache Spark в этом быстром уроке.
Загрузка Spark и как использовать интерактивную оболочку
Отличный способ поэкспериментировать с Apache Spark — это использовать доступные интерактивные оболочки. Существует оболочка Python и оболочка Scala.
Чтобы загрузить Apache Spark, перейдите по этой ссылке и получите последнюю готовую версию, чтобы мы могли запустить оболочку из коробки.
Сейчас Apache Spark — версия 1.5.0, выпущенная 9 сентября 2015 года.
Разархивировать Spark
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgzЗапустить оболочку Python
cd spark-1.5.0-bin-hadoop2.4
./bin/pysparkМы не будем использовать оболочку Python здесь, в этом разделе.
Интерактивная оболочка Scala работает на JVM, поэтому она позволяет вам использовать библиотеки Java.
Запустить оболочку Scala
cd spark-1.5.0-bin-hadoop2.4
./bin/spark-shell Вы должны увидеть что-то вроде этого:
Приветствие Scala Shell
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.5.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_25)
Type in expressions to have them evaluated.
Type :help for more information.
15/08/24 21:58:29 INFO SparkContext: Running Spark version 1.5.0Ниже приведено простое упражнение, которое поможет вам начать работу с оболочкой. Возможно, вы не понимаете, что мы делаем сейчас, но мы подробно объясним позже. С оболочкой Scala сделайте следующее:
Создать текстовый файл СДР из файла README в Spark
val textFile = sc.textFile("README.md")Получить первый элемент в текстовом файле RDD
textFile.first()
res3: String = # Apache SparkВы можете отфильтровать RDD текстовый файл вернуть новый СДР, содержащий все строки со словом искра, а затем сосчитать его строки.
Фильтрованный СДР linesWithSpark И посчитай его строки
val linesWithSpark = textFile.filter(line => line.contains("Spark"))
linesWithSpark.count()
res10: Long = 19Найти строку с наибольшим количеством слов в СДР linesWithSpark, сделайте следующее. С помощью карта метод, сопоставьте каждую строку в RDD к числу, и ищите пробелы. Затем используйтеуменьшить метод для поиска строк, которые имеют наибольшее количество слов.
Найти строку в СДР текстовый файл в котором больше всего слов
textFile.map(line => line.split(" ").size)
.reduce((a, b) => if (a > b) a else b)
res11: Int = 14В строке 14 больше всего слов.
Вы также можете импортировать библиотеки Java, например, как Math.max () метод, потому что аргументы карта и уменьшить являются литералами функций Scala.
Импорт методов Java в оболочке Scala
import java.lang.Math
textFile.map(line => line.split(" ").size)
.reduce((a, b) => Math.max(a, b))
res12: Int = 14Мы можем легко кэшировать данные в памяти.
Кеш отфильтрованный RDD linesWithSpark затем посчитать строки
linesWithSpark.cache()
res13: linesWithSpark.type =
MapPartitionsRDD[8] at filter at <console>:23
linesWithSpark.count()
res15: Long = 19Это был краткий обзор того, как использовать интерактивную оболочку Spark.
РД
Spark позволяет пользователям выполнять задачи параллельно в кластере. Этот параллелизм стал возможен благодаря использованию одного из основных компонентов Spark , СДР . СДР ( устойчивые распределенные данные ) — это представление данных. СДР — это данные, которые могут быть разбиты на кластеры (если хотите, данные будут защищены). Разбиение позволяет выполнять задачи параллельно . Чем больше у вас разделов, тем больше параллелизма вы можете сделать . Диаграмма ниже представляет собой СДР :

{kind=link}
Рассматривая каждый столбец как раздел, вы можете легко назначить эти разделы узлам кластера.
Чтобы создать СДР , вы можете читать данные из внешнего хранилища; например, от Cassandra или Amazon Simple Storage Service, HDFS или любых данных, которые предлагают формат ввода Hadoop. Вы также можете создать СДР , читая текстовый файл, массив или JSON. С другой стороны, если данные являются локальными для вашего приложения, вам просто нужно распараллелить их, тогда вы сможете применить все функции Spark к ним и выполнить анализ параллельно через Apache Spark Cluster . Чтобы проверить это с оболочкой Scala Spark :
Сделать RDD thingsRDD из списка слов
val thingsRDD = sc.parallelize(List("spoon", "fork", "plate", "cup", "bottle"))
thingsRDD: org.apache.spark.rdd.RDD[String] =
ParallelCollectionRDD[11] at parallelize at <console>:24Считайте Слово в СДР thingsRDD
thingsRDD.count()
res16: Long = 5Для работы с Spark вам нужно начать с контекста Spark . Когда вы используете оболочку, Spark Context уже существует какЮжная Каролина, Когда мы называемРаспараллеливать метод в контексте Spark, мы получим RDD, который разделен и готов к распределению по узлам.
Что мы можем сделать с RDD?
С помощью RDD мы можем либо преобразовывать данные, либо предпринимать действия с этими данными. Это означает, что с помощью преобразования мы можем изменить его формат, искать что-то, фильтровать данные и т. Д. С помощью действий вы вносите изменения, вы извлекаете данные, собираете данные и дажекол-(),
Например, давайте создадим СДР текстовый файл из текстового файла README.md доступный в Spark , этот файл содержит строки текста. Когда мы читаем файл в RDD стекстовый файлданные будут разбиты на строки текста, которые могут быть распределены по кластеру и работать параллельно.
Создать RDD текстовый файл от README.md
val textFile = sc.textFile("README.md")Считать линии
textFile.count()
res17: Long = 98Количество 98 представляет количество строк в README.md файл.
Получит что-то похожее на это:

{kind=link}
Тогда мы можем отфильтровать все строки, которые имеют слово искраи создайте новый RDD linesWithSpark который содержит эти отфильтрованные данные.
Создать отфильтрованный RDD linesWithSpark
val linesWithSpark = textFile.filter(line => line.contains("Spark"))Используя предыдущую диаграмму, где мы показали, как текстовый файл СДР будет выглядеть как СДР linesWithSpark будет выглядеть следующим образом:

{kind=link}
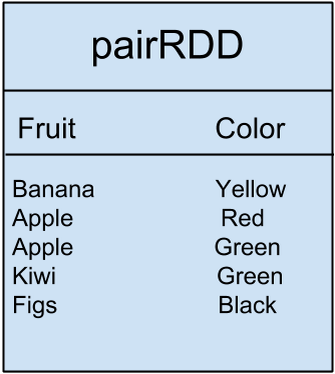
Стоит отметить, что у нас также есть то, что называется парным СДР , этот вид СДР используется, когда у нас есть парные данные ключ / значение. Например, если у нас есть данные, подобные следующей таблице, Плоды соответствуют своему цвету:

{kind=link}
Мы можем выполнить groupByKey () преобразование на данные фруктов, чтобы получить.
преобразование groupByKey ()
pairRDD.groupByKey()
Banana [Yellow]
Apple [Red, Green]
Kiwi [Green]
Figs [Black]Это преобразование просто сгруппировало 2 значения (красное и зеленое) с одним ключом (Apple). Это примеры изменений трансформации.
После того, как мы отфильтровали RDD , мы можем собрать / материализовать его данные и включить их в наше приложение, это пример действия. Как только мы это сделаем, все данные в RDD исчезнут, но мы все равно можем вызвать некоторые операции с данными RDD, поскольку они все еще находятся в памяти.
Сбор или материализация данных в linesWithSpark РДД
linesWithSpark.collect()Важно отметить, что каждый раз, когда мы вызываем действие в Spark, например, действие count () , Spark будет выполнять все преобразования и вычисления, выполненные в этой точке, а затем возвращать число счетчиков, это будет несколько медленным. Чтобы устранить эту проблему и повысить скорость работы, вы можете кэшировать RDD в памяти . Таким образом, когда вы вызываете действие раз за разом, вам не нужно запускать процесс с самого начала, вы просто получаете результаты кэшированного RDD из памяти.
Обналичивание RDD linesWithSpark
linesWithSpark.cache()Если вы хотите удалить RDD linesWithSpark из памяти вы можете использовать unpersist () метод.
Удаление linesWithSpark из памяти
linesWithSpark.unpersist()В противном случае Spark автоматически удаляет самый старый обналиченный RDD, используя наименее использованную логику (LRU).
Вот список, чтобы суммировать процесс Spark от начала до конца:
-
Создайте RDD какого-либо рода данных.
-
Преобразование данных СДР путем фильтрации, например.
-
Кэшируйте преобразованный или отфильтрованный RDD при необходимости повторного использования.
-
Выполните некоторые действия с RDD, такие как извлечение данных, подсчет, хранение данных на Cassandra и т. Д.
Вот список некоторых преобразований, которые можно использовать в СДР:
-
фильтр()
-
карта()
-
образец()
-
союз ()
-
groupbykey ()
-
sortbykey ()
-
combineByKey ()
-
subtractByKey ()
-
mapValues ()
-
Ключи ()
-
Значения()
Вот список некоторых действий, которые можно выполнить на СДР:
-
собирать ()
-
кол-()
-
первый()
-
countbykey ()
-
saveAsTextFile ()
-
уменьшения ()
-
принять (п)
-
countBykey ()
-
collectAsMap ()
-
поиск (ключ)
Для полных списков с их описаниями, проверьте следующую документацию Spark .
Вывод
Мы представили Apache Spark , быстрорастущую кластерную вычислительную систему с открытым исходным кодом. Мы продемонстрировали некоторые библиотеки и платформы Apache Spark для расширенной аналитики данных. Мы показали, почему Apache Spark быстро преуспевает благодаря своей мощности и простоте использования. Мы продемонстрировали, что Apache Spark предоставляет распределенную вычислительную среду в памяти, а также простоту ее использования и понимания.
Вернитесь к части 2. Мы углубимся в часть 2.
Ссылки по теме: