Это заняло неделю больше, чем я надеялся, но я наконец-то готов к следующему выпуску моей работы «больше блога». Как многие из вас знают, я не человек данных. Однако нельзя игнорировать тот факт, что приложения являются либо проводником, либо генератором данных. Поэтому неизбежно, что я должен время от времени выходить из своей зоны комфорта. Важно использовать эти возможности и чему-то научиться у них.
Самый последний пример этого был, когда у меня был партнер, который столкнулся с устаревшим уровнем ценообразования веб-бизнес-баз данных Azure SQL. Их решение является чувствительным к затратам, и когда они посмотрели рекомендации портала Azure относительно новых уровней для своих многочисленных баз данных, у них был небольшой шок от наклеек.
С некоторой помощью от таких людей, как Гай Хэйкок из команды Azure SQL и хорошего начального поста в блоге по мониторингу использования БД SQL , партнер смог определить, что рекомендации высокого уровня были связаны с ежедневными процессами резервного копирования базы данных. Поскольку новые уровни SQL предлагают восстановление на определенный момент времени, моему партнеру не нужно было делать собственные резервные копии, и в результате их фактические потребности были намного ниже, чем предложенные порталом, что экономило им много денег.
Чтобы определить, что им действительно нужно, все, что сделал партнер, — это перенес данные диагностического представления SQL в Excel, а затем визуализировал их там. Но я подумал, что должен быть еще более простой способ — не просто визуализировать его, а создать непрерывную панель инструментов. И с этой целью начал изучать Power BI, о чем этот пост.
Представления Управления диагностикой
Первый шаг — понять взгляды руководства и то, как они могут помочь нам. Сообщение в блоге, о котором я упоминал ранее, относится к двум отдельным представлениям руководства: «классическому» представлению sys.resource_stats, которое отображает данные за 14 дней с 15-минутными средними значениями, и новому sys.dm_db_resource_stats с данными за 1 час с 15-секундными средними.
Для «классического» представления есть две схемы: веб-версия / версия для бизнеса и новая схема. Новая схема очень похожа на новую схему sys.dm_db_resource_stats , на которой я остановлюсь в наших примерах в этом посте. Основное отличие состоит в том, что resources_stats находится в «основной» базе данных SQL DB SQL, а dm_db_resource_stats можно найти в отдельных базах данных.
Нам доступны четыре значения: процессор, данные, запись в журнал и память. Каждый выражается в процентах от того, что доступно с учетом текущего уровня базы данных. Это позволяет нам запрашивать данные напрямую, чтобы получить подробную информацию:
SELECT * FROM dm_db_resource_statsИли, если мы хотим сделать немного более сложным, мы можем объединять значения в минуту и составлять график микса, максимума и среднего значения в минуту:
SELECT
distinct convert(datetime,convert(char,end_time,100)) as Clock,
max(avg_cpu_percent) as MaxCPU,
min(avg_cpu_percent) as MinCPU,
avg(avg_cpu_percent) as AvgCPU,
max(avg_log_write_percent) as MaxLogWrite,
min(avg_log_write_percent) as MinLogWrite,
avg(avg_log_write_percent) as AvgLogWrite,
max(avg_data_io_percent) as MaxIOPercent,
min(avg_data_io_percent) as MinIOPercent,
avg(avg_data_io_percent) as AvgIOPercent
FROM sys.dm_db_resource_stats
GROUP BY convert(datetime,convert(char,end_time,100))Используя новое представление dm_db_resource_stats, мои эксперименты последовательно возвращали 256 строк (64 минуты), что является хорошим небольшим набором результатов. Это дает вам хороший показатель времени использования ресурсов базы данных. Если вы используете классическое представление resource_stats (которое вы запрашиваете на уровне master db), вы можете получить еще несколько строк и, вероятно, захотите отфильтровать результирующий набор обратно по соответствующему database_name .
Поскольку значения представляют собой процент от доступных ресурсов, это позволяет нам определить, насколько близко к пределу уровня базы данных работает наша база данных, что позволяет нам определить, когда мы можем захотеть внести коррективы.
Визуализация Power BI
После определения набора результатов мы готовы приступить к подключению визуализаций PowerBI. Для простоты я собираюсь использовать онлайн-версию Power BI . Это онлайн-база данных, так почему бы не онлайн-инструмент отчетности. Power BI онлайн доступен бесплатно, так что просто зайдите и зарегистрируйтесь. И поскольку это своего рода статья «Начало работы с Power BI», я не буду вдаваться в подробности портала. Так что, если вы новичок в этом, вам, возможно, придется немного покопаться или посмотреть пару уроков, чтобы начать.
После входа в Power BI начните с подключения к базе данных.

Примечание. Необходимо убедиться, что брандмауэр вашей базы данных SQL разрешает подключения из служб Azure.
На следующей странице выберите База данных SQL Azure и нажмите «Подключиться». Затем введите имя сервера (вместе с частью database.windows.net ) и имя базы данных. Но прежде чем нажать «Далее», выберите «Включить дополнительные параметры».

Это важно, потому что Power BI онлайн не видит системные / диагностические представления. Итак, мы собираемся использовать запросы, с которыми мы работали выше, чтобы получить наши данные. Просто вставьте запрос в поле «Пользовательские фильтры».
Еще один важный момент, на который следует обратить внимание, прежде чем мы продолжим, заключается в том, что, поскольку мы используем базу данных SQL Azure, интервал обновления не может быть менее 15 минут. Если вам нужны более частые обновления, вам может потребоваться использовать Power BI Desktop .
With this form completed, click on “Next” and provide the username and password for your database and click on “Sign in”. Since our query is fairly small, the import of the dataset should only take a few seconds and then we’ll arrive at a dashboard with our SQL database pinned to it. Click on the database tile, and we get a new, blank report that we can start to populate.
Along the right side of our report, select the “Line Chart” visualization and then check AvgCPU, MaxCPU, and MinCPU in the field list. Then drag the Clock field to the Axis field. This setup should look something like this:

If done properly, we should have a visualization that looks something like…
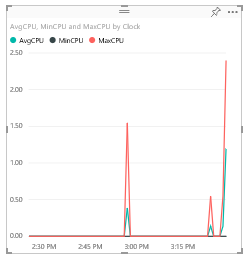
From there you can change/resize the visualization, change various properties of it (colors, labels, title, background, etc.) by clicking on the paint brush icon below visualizations. You can even add other visualizations to this same report by clicking away in the whitespace and adding them like so…
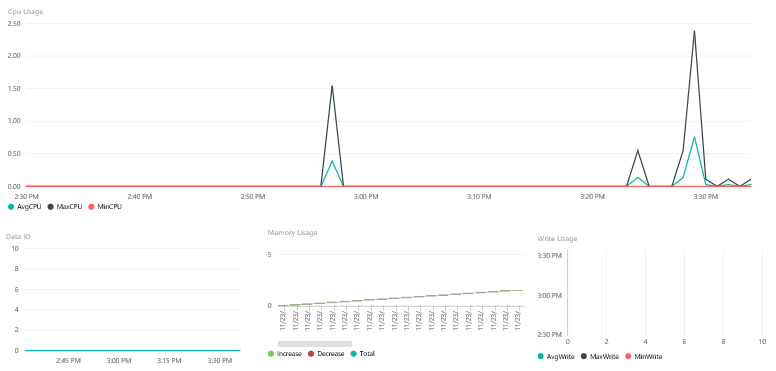
It’s entirely up to you what values you want to display and how.
So there you have it
There’s not really much to it. The hardest part was figuring out how to connect Power BI online to the management view. I like that the Power BI desktop tool calls it a “query” and not a “filter». Less confusion there.
If I had more time, it would be neat to look at creating a content sample pack (creation of content packs is not self-service for the moment) for Azure SQL DB. But, I have a couple other irons in the fire, so perhaps I can circle back to that topic on another day. So in the interim, perhaps have a look at the SQL Sentry content pack (Note: This requires SQL Sentry’s Performance Advisor product which has a free trial).
Until next time!