блоге Аврелия .
Сложные архитектуры хранения данных обычно не основаны на одной базе данных. В этих средах данные сильно различаются, что означает, что они существуют во многих формах, агрегируются и дублируются на разных уровнях, а в худшем случае смысл данных не совсем понятен. Среды с разрозненными данными могут создавать проблемы для тех, кто стремится интегрировать их в целях аналитики, ETL (Extract-Transform-Load) и других бизнес-сервисов. Наличие простых способов работы с данными в этих типах сред позволяет быстро создавать решения для данных.
Некоторые причины несоответствия данных возникают из-за необходимости хранить данные в разных типах баз данных, чтобы использовать преимущества, предоставляемые каждым типом. Вот некоторые примеры различных типов баз данных (см. Получение и размещение данных из базы данных ):
- Реляционная база данных : реляционная база данных, такая как MySQL , Oracle или Microsoft SQL Server , организует данные в таблицы со строками и столбцами, используя схему, которая помогает управлять целостностью данных.
- Хранилище документов : База данных, ориентированная на документы, такая как MongoDB , CouchDB или RavenDB , организует данные в концепцию документа, которая обычно полуструктурирована как вложенные карты и кодируется в некоторый формат, такой как JSON .
- График базы данных : а график представляет собой структуру данных , которая организует данные в понятия вершин и ребер. Вершины могут рассматриваться как «точки», а ребра могут рассматриваться как «линии», где линии соединяют эти точки посредством некоторого отношения. Графики представляют собой очень естественный способ моделирования реальных отношений между различными объектами. Примерами графовых баз данных являются Titan , Neo4j , OrientDB , Dex и InfiniteGraph .
Gremlin — это предметно-ориентированный язык (DSL) для обхода графов. Он построен с использованием средств метапрограммирования Groovy , языка динамического программирования для виртуальной машины Java (JVM). Точно так же, как Gremlin добавляет к Groovy, Groovy добавляет к Java, предоставляя расширенный API и программные ярлыки, которые могут сократить многословность самой Java.
 Gremlin оснащен терминалом, также известным как REPL или CLI , который предоставляет интерфейс, через который программист может интерактивно проходить по графику. Учитывая роль Гремлин как DSL для графов, выполнение взаимодействий с графом представляет типичное использование терминала. Однако, учитывая, что терминал Gremlin на самом деле является терминалом Groovy, доступна также полная мощность Groovy:
Gremlin оснащен терминалом, также известным как REPL или CLI , который предоставляет интерфейс, через который программист может интерактивно проходить по графику. Учитывая роль Гремлин как DSL для графов, выполнение взаимодействий с графом представляет типичное использование терминала. Однако, учитывая, что терминал Gremlin на самом деле является терминалом Groovy, доступна также полная мощность Groovy:
- Доступ к полным API для Java и Groovy
- Доступ к внешним JAR-файлам (т.е. сторонним библиотекам)
- Гремлин и шпунтовый синтаксический сахар
- Расширяемая среда программирования с помощью метапрограммирования
Имея эти возможности в руках, Gremlin предлагает способ взаимодействия со средой с несколькими базами данных с высокой эффективностью. В следующих разделах подробно описаны два различных варианта использования, где Gremlin выступает в качестве специализированного средства обработки данных для быстрой разработки интегрированных решений для баз данных, основанных на графике.
Постоянство Полиглота
Загрузка данных в график из другого источника данных может потребовать тщательного планирования. Формирование стратегии загрузки сильно зависит от размера данных, их исходного формата, сложности схемы графа и других факторов окружающей среды. В случаях, когда сложность загрузки низкая, например, в случаях, когда набор данных невелик и схема графа упрощена, стратегия загрузки может заключаться в использовании терминала Gremlin для загрузки данных.
MongoDB как источник данных
Рассмотрим сценарий, в котором исходные данные находятся в MongoDB . Сами исходные данные содержат информацию, которая указывает на отношение «следует» между двумя пользователями, аналогично концепции пользователя, следующего за другим пользователем в Twitter. В отличие от графиков, хранилища документов, такие как MongoDB, не поддерживают понятие связанных объектов и поэтому затрудняют представление сети пользователей в аналитических целях.
Модель
данных MongoDB состоит из баз данных и коллекций, где база данных представляет собой набор коллекций, а коллекция содержит набор документов. Данные для этих «следующих» связей находятся в базе данных, называемой «сетью», и находятся в коллекции, которая называется «следует». Отдельные документы в этой коллекции выглядят так:
{ "_id" : ObjectId("4ff74c4ae4b01be7d54cb2d3"), "followed" : "1", "followedBy" : "3", "createdAt" : ISODate("2013-01-01T20:36:26.804Z") }
{ "_id" : ObjectId("4ff74c58e4b01be7d54cb2d4"), "followed" : "2", "followedBy" : "3", "createdAt" : ISODate("2013-01-15T20:36:40.211Z") }
{ "_id" : ObjectId("4ff74d13e4b01be7d54cb2dd"), "followed" : "1", "followedBy" : "2", "createdAt" : ISODate("2013-01-07T20:39:47.283Z") }
Этот тип набора данных легко переводится в графическую структуру. На следующей диаграмме показано, как данные документа в MongoDB будут представлены в виде графика. 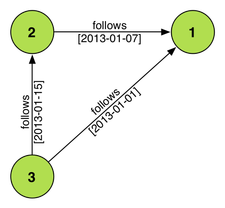 Чтобы начать процесс загрузки графа, терминал Gremlin должен иметь доступ к клиентской библиотеке для MongoDB. GMongo как раз такая библиотека и предоставляет выразительный синтаксис для работы с MongoDB в Groovy. Баночка GMongo файл и его зависимость, то драйвер баночка Монго Java , должны быть помещены в
Чтобы начать процесс загрузки графа, терминал Gremlin должен иметь доступ к клиентской библиотеке для MongoDB. GMongo как раз такая библиотека и предоставляет выразительный синтаксис для работы с MongoDB в Groovy. Баночка GMongo файл и его зависимость, то драйвер баночка Монго Java , должны быть помещены в GREMLIN_HOME/libкаталог. С этими файлами запустите Gremlin с:
GREMLIN_HOME/bin/gremlin.sh
Gremlin automatically imports a number of classes during its initialization process. The GMongo classes will not be part of those default imports. Classes from external libraries must be explicitly imported before they can be utilized. The following code demonstrates the import of GMongo into the terminal session and then the initialization of connectivity to the running MongoDB “network” database.
gremlin> import com.gmongo.GMongo
==>import com.tinkerpop.gremlin.*
...
==>import com.gmongo.GMongo
gremlin> mongo = new GMongo()
==>com.gmongo.GMongo@6d1e7cc6
gremlin> db = mongo.getDB("network")
==>network
На этом этапе можно выполнить любое количество команд MongoDB для переноса этих данных в терминал.
gremlin> db.follows.findOne().followed
==>followed=1
gremlin> db.follows.find().limit(1)
==>{ "_id" : { "$oid" : "4ff74c4ae4b01be7d54cb2d3"} , "followed" : "1" , "followedBy" : "3" , "createdAt" : { "$date" : "2013-01-01T20:36:26.804Z"}}
Шаги для загрузки данных в граф с поддержкой Blueprints (в данном случае, локальный экземпляр Titan ) следующие.
gremlin> g = TitanFactory.open('/tmp/titan')
==>titangraph[local:/tmp/titan]
gremlin> // first grab the unique list of user identifiers
gremlin> x=[] as Set; db.follows.find().each{x.add(it.followed); x.add(it.followedBy)}
gremlin> x
==>1
==>3
==>2
gremlin> // create a vertex for the unique list of users
gremlin> x.each{g.addVertex(it)}
==>1
==>3
==>2
gremlin> // load the edges
gremlin> db.follows.find().each{g.addEdge(g.v(it.followedBy),g.v(it.followed),'follows',[followsTime:it.createdAt.getTime()])}
gremlin> g.V
==>v[1]
==>v[3]
==>v[2]
gremlin> g.E
==>e[2][2-follows->1]
==>e[1][3-follows>2]
==>e[0][3-follows->1]
gremlin> g.e(2).map
==>{followsTime=1341607187283}
Этот метод для ETL, связанных с графиком, является легким и не требующим больших усилий, что делает его пригодным для множества вариантов использования, которые вытекают из необходимости быстрого ввода данных в график для специального анализа.
MySQL как источник данных

Процесс извлечения данных из MySQL не так сильно отличается от MongoDB. Предположим, что те же данные «следует» находятся в MySQL в таблице из четырех столбцов, которая называется «следует».
| мне бы | с последующим | с последующим | создан в |
|---|---|---|---|
| 10001 | 1 | 3 | 2013-01-01T20: 36: 26.804Z |
| 10002 | 2 | 3 | 2013-01-15T20: 36: 40.211Z |
| 10003 | 1 | 2 | 2013-01-07T20: 39: 47.283Z |
Помимо некоторых изменений форматирования имени поля и того, что столбец «id» является длинным значением, в отличие от идентификатора MongoDB, данные такие же, как в предыдущем примере, и имеют те же проблемы для сетевой аналитики, что и MongoDB.
Groovy SQL прост в своем подходе к доступу к данным через
JDBC . Чтобы использовать его внутри терминала Gremlin,
файл jar драйвера MySQL JDBC должен быть помещен в
GREMLIN_HOME/libкаталог. Как только этот файл будет на месте, запустите терминал Gremlin и выполните следующие команды:
gremlin> import groovy.sql.Sql
...
gremlin> sql = Sql.newInstance("jdbc:mysql://localhost/network", "username","password", "com.mysql.jdbc.Driver")
...
gremlin> g = TitanFactory.open('/tmp/titan')
==>titangraph[local:/tmp/titan]
gremlin> // first grab the unique list of user identifiers
gremlin> x=[] as Set; sql.eachRow("select * from follows"){x.add(it.followed); x.add(it.followed_by)}
gremlin> x
==>1
==>3
==>2
gremlin> // create a vertex for the unique list of users
gremlin> x.each{g.addVertex(it)}
==>1
==>3
==>2
gremlin> // load the edges
gremlin> sql.eachRow("select * from follows"){g.addEdge(g.v(it.followed_by),g.v(it.followed),'follows',[followsTime:it.created_at.getTime()])}
gremlin> g.V
==>v[1]
==>v[3]
==>v[2]
gremlin> g.E
==>e[2][2-follows->1]
==>e[1][3-follows>2]
==>e[0][3-follows->1]
gremlin> g.e(2).map
==>{followsTime=1341607187283}
Помимо некоторых различий в API доступа к данным, сценарий для загрузки данных из MongoDB отличается от сценария для загрузки данных из MySQL. Оба примера демонстрируют варианты интеграции данных, которые требуют небольших затрат и усилий.
Запросы Полиглота
Графическая база данных, вероятно, сопровождается другими источниками данных, которые вместе представляют общую стратегию данных для организации. С графиком, созданным и заполненным данными, инженеры и ученые могут использовать терминал Gremlin для запроса графика и разработки алгоритмов, которые станут основой для будущих сервисов приложений. Проблема возникает, когда график не содержит всех данных, необходимых пользователю Gremlin для выполнения его работы.
В этих случаях можно использовать терминал Gremlin, чтобы выполнить то, что можно рассматривать как
запрос полиглота . В запросе полиглота данные объединяются из различных источников данных и типов хранилищ данных для получения единого набора результатов. Концепцию запроса полиглота можно продемонстрировать, расширив последний сценарий, в котором «последующие» данные были перенесены в граф из MongoDB. Предположим, что в MongoDB существует еще одна коллекция, называемая «анкеты», которая содержит демографические данные пользователя, такие как имя, возраст и т. Д. Используя терминал Gremlin, эти «отсутствующие данные» можно сделать частью анализа.
gremlin> // a simple query within the graph
gremlin> g.v(1).in
==>v[3]
==>v[2]
gremlin> // a polyglot query that incorporates data from the graph and MongoDB
gremlin> g.v(1).in.transform{[userId:it.id,userName:db.profiles.findOne(uid:it.id).name]}
==>{userId=3, userName=willis}
==>{userId=2, userName=arnold}
Первое приведенное выше выражение Gremlin представляет собой одностадийный обход, который просто просит увидеть пользователей, которые следуют за вершиной «1». Хотя теперь ясно, сколько пользователей следуют этой вершине, результаты не очень значимы. Это всего лишь список идентификаторов вершин, и, учитывая приведенный пример, пока нет возможности расширить эти результаты, поскольку эти данные представляют общие данные в графе. Чтобы действительно понять эти результаты, было бы хорошо взять имя пользователя из коллекции «profile» в MongoDB и смешать этот атрибут с выходными данными. Вторая строка Gremlin, запрос полиглота, выглядит именно так. Он расширяет это ограниченное представление данных, выполняя тот же обход, а затем обращаясь к MongoDB, чтобы найти имя пользователя в коллекции «profile».
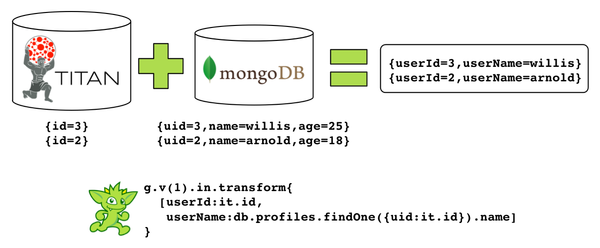
Анатомия запроса полиглота такова:
g.v(1).in— получить входящие вершины в вершину 1transform{...}— для каждой входящей вершины обработайте ее замыканием, которое создает карту (т. Е. Набор пар ключ / значение) для каждой вершины[userId:it.id,— используйте «id» вершины в качестве значения ключа «userId» на картеuserName:db.profiles.findOne(uId:it.id).name]— смешайте имя пользователя, запросив MongoDBfindOne()для поиска «профиля» документа в MongoDB, извлекая значение ключа «name» из этого документа и устанавливая это значение поля «userName» в выходных данных
С учетом имен пользователей, включенных в результаты, конечный результат становится более удобным для пользователя, возможно, позволяя лучше понять его.
Вывод
Загрузка данных в график и сбор данных, недоступных в самом графике, являются двумя примерами гибкости терминала Gremlin, но существуют и другие варианты использования.
- Записать выходные данные алгоритма в файл или базу данных для специального анализа в других инструментах, таких как инструменты отчетности Microsoft Excel , R или Business Intelligence .
- Чтение текстовых файлов данных из файловой системы (например, файлов CSV) для создания графических данных.
- Обходы, которые создают карты в памяти значительного размера, могут выиграть от использования MapDB , в котором реализации Map поддерживаются диском или памятью вне кучи.
- Проверяйте обходы и алгоритмы, прежде чем переходить к конкретному проекту, путем построения небольшого одноразового графика из подмножества внешних данных, которые имеют отношение к тому, что будет проверяться. Этот подход также имеет отношение к базовому специальному анализу данных, которые еще могут отсутствовать в графике, но выиграют от структуры данных графика и доступных доступных наборов инструментов.
- Не все графические данные требуют графической базы данных. Gremlin поддерживает GraphML , GraphSON и GML как графические форматы на основе файлов. Они могут быть легко вставлены в TinkerGraph в памяти . Используйте Gremlin для анализа этих графов с использованием выражений путей способами, невозможными с помощью типичных инструментов анализа графиков , таких как iGraph , NetworkX , JUNG и т. Д.
- «Отладка данных» возможна с учетом быстрого перехода Gremlin между запросом и результатом. Обход графика, чтобы удостовериться, что данные были загружены правильно из терминала Gremlin, важен для обеспечения правильной настройки данных.
- Доступ к данным не должен ограничиваться локально доступными файлами и базами данных. Те же методы записи и чтения данных в эти ресурсы и из них могут быть применены к сторонним веб-службам и другим API-интерфейсам с использованием Groovy HTTPBuilder .
- Извлеките данные в график для вывода в виде GraphML или другого формата, который можно визуализировать в Cytoscape , Gephi или других инструментах визуализации графиков.
 Мощь и гибкость Gremlin и Groovy позволяют беспрепятственно взаимодействовать с разнородными данными. Эта возможность позволяет аналитикам, инженерам и ученым использовать терминал Gremlin в качестве легкого рабочего места в лаборатории данных, что позволяет проводить быстрый специальный анализ, основанный на структурах графовых данных. Более того, по мере обнаружения, разработки и тестирования алгоритмов эти обходы Гремлин могут быть в конечном итоге развернуты в производственной системе.
Мощь и гибкость Gremlin и Groovy позволяют беспрепятственно взаимодействовать с разнородными данными. Эта возможность позволяет аналитикам, инженерам и ученым использовать терминал Gremlin в качестве легкого рабочего места в лаборатории данных, что позволяет проводить быстрый специальный анализ, основанный на структурах графовых данных. Более того, по мере обнаружения, разработки и тестирования алгоритмов эти обходы Гремлин могут быть в конечном итоге развернуты в производственной системе.