алгоритм алгоритма map / Reduce заключается в том, как правильно выбрать ключ для записи на разных этапах обработки.
Однако «измерение времени» имеет совершенно иную характеристику по сравнению с другими атрибутами данных, особенно когда речь идет об обработке данных в реальном времени. Он представляет другой набор проблем для пакетно-ориентированной модели Map / Reduce.
- Обработка в реальном времени требует очень низкой задержки отклика, что означает, что для обработки не требуется слишком много данных, собранных в измерении «время».
- Данные, собранные из нескольких источников, возможно, не все поступили в точку агрегирования.
- В стандартной модели Map / Reduce, фаза сокращения не может начаться, пока не завершится фаза карты. И все промежуточные данные сохраняются на диске перед загрузкой в редуктор. Все это добавляет значительную задержку обработки.
Вот более подробное описание
этой характеристики высокой задержки для Hadoop .
Хотя Hadoop Map / Reduce предназначен для пакетной рабочей нагрузки, некоторые приложения, такие как обнаружение мошенничества, показ рекламы, мониторинг сети, требуют отклика в реальном времени для обработки большого объема данных, начали искать различные способы настройки Hadoop для вписаться в среду обработки более реального времени. Здесь я попытаюсь взглянуть на методику выполнения параллельной обработки с малой задержкой на основе модели Map / Reduce.
Общая модель обработки потока
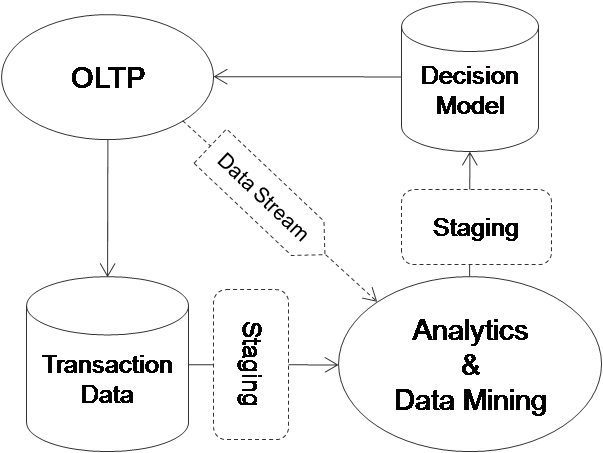 В этой модели данные создаются в различных системах OLTP, которые обновляют хранилище данных транзакций, а также асинхронно отправляют дополнительные данные для аналитической обработки. Аналитическая обработка запишет выходные данные в модель принятия решения, которая будет передавать информацию в систему OLTP для принятия решений в режиме реального времени.
В этой модели данные создаются в различных системах OLTP, которые обновляют хранилище данных транзакций, а также асинхронно отправляют дополнительные данные для аналитической обработки. Аналитическая обработка запишет выходные данные в модель принятия решения, которая будет передавать информацию в систему OLTP для принятия решений в режиме реального времени.
Обратите внимание на «асинхронную природу» аналитической обработки, которая отделена от системы OLTP, таким образом, система OLTP не будет замедляться в ожидании завершения аналитической обработки. Тем не менее, нам все еще нужно выполнять аналитическую обработку как можно скорее, иначе модель принятия решения не будет очень полезной, если она не отражает текущую картину мира. То, что задержка допустима, зависит от конкретного приложения.
Микропакет в Map / Reduce
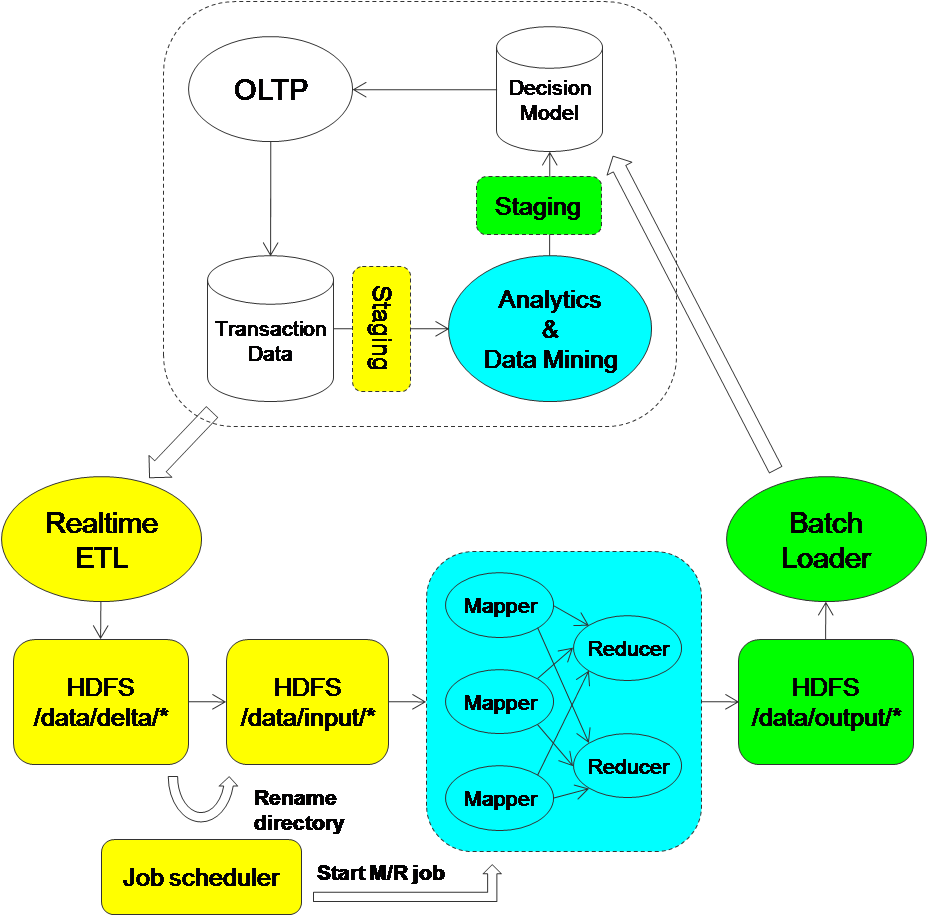
Один из подходов состоит в том, чтобы разрезать данные на небольшие партии на основе временного окна (например, каждый час) и отправить данные, собранные в каждой партии, в задание Map Reduce. Необходим поэтапный механизм, позволяющий приложению OLTP продолжать работу независимо от аналитической обработки. Планировщик заданий используется для регулирования производителя и потребителя, поэтому каждый из них может действовать независимо.
Непрерывная карта / уменьшить
Здесь давайте представим некоторую возможную модификацию модели выполнения Map / Reduce для обслуживания потоковой обработки в реальном времени. Я не пытаюсь беспокоиться об обратной совместимости Hadoop, которая является подходом, который использует
онлайн-прототип Hadoop (HOP) .
Долго работает
Первая модификация — сделать маппер и редуктор долговременными. Следовательно, мы не можем дождаться окончания фазы карты, прежде чем начинать фазу сокращения, поскольку фаза карты никогда не заканчивается. Это подразумевает, что преобразователь передает данные в редуктор после завершения обработки и позволяет редуктору сортировать данные. Недостатком этого подхода является то, что он не дает возможности запускать функцию comb () на стороне карты, чтобы уменьшить использование полосы пропускания. Это также переносит большую нагрузку на редуктор, который теперь должен выполнять сортировку.
Обратите внимание, что существует компромисс между задержкой и оптимизацией. Оптимизация требует накопления большего количества данных в источнике (например, в Mapper), чтобы можно было выполнить локальную консолидацию (т.е. объединить). К сожалению, низкая задержка требует отправки данных как можно скорее, поэтому накопление может быть незначительным.
HOP предлагает механизм адаптивного управления потоком, чтобы данные передавались в редуктор ASAP до тех пор, пока редуктор не будет перегружен и отодвинут (используя некоторый протокол управления потоком). Затем маппер буферизует обработанное сообщение и выполняет функцию comb () перед отправкой в редуктор. Этот подход автоматически перемещает вперед и назад агрегационную рабочую нагрузку между редуктором и картографическим устройством.
Временное окно: срез и диапазон
Это концепция «временного среза» и концепция «временного диапазона». «Срез» определяет временное окно, в котором результат накапливается до выполнения обработки сокращения. Это также минимальный объем данных, который картограф должен накапливать перед отправкой в редуктор.
«Диапазон» определяет временное окно, в котором результаты агрегируются. Это может быть окно ориентира, в котором он имеет четко определенную начальную точку, или окно прыжков (рассмотрим сценарий движущегося ориентира). Это также может быть скользящее окно, в котором агрегировано окно фиксированного размера из текущего времени.
После получения определенного отрезка времени от каждого преобразователя редуктор может начать обработку агрегирования и объединить результат с предыдущим результатом агрегирования. Срез может быть динамически скорректирован в зависимости от объема данных, отправленных из картографа.
Инкрементная обработка

Обратите внимание, что редуктор должен вычислить агрегированное значение среза после получения всех записей одного и того же среза от всех преобразователей. После этого он вызывает пользовательскую функцию merge (), чтобы объединить значение среза со значением диапазона. В случае, если необходимо обновить диапазон (например, достигнуть границы окна перехода), функция init () будет вызвана для получения обновленного значения диапазона. Если значение диапазона необходимо обновить (когда определенное значение среза выходит за пределы скользящего диапазона), будет вызвана функция unmerge ().
Вот пример того, как мы отслеживаем среднюю частоту обращений (то есть: общее количество обращений в час) в течение 24-часового скользящего окна с обновлением в час (то есть: одночасовой срез).
# Call at each hit record
map(k1, hitRecord) {
site = hitRecord.site
# lookup the slice of the particular key
slice = lookupSlice(site)
if (slice.time - now > 60.minutes) {
# Notify reducer whole slice of site is sent
advance(site, slice)
slice = lookupSlice(site)
}
emitIntermediate(site, slice, 1)
}
combine(site, slice, countList) {
hitCount = 0
for count in countList {
hitCount += count
}
# Send the message to the downstream node
emitIntermediate(site, slice, hitCount)
}
# Called when reducer receive full slice from all mappers
reduce(site, slice, countList) {
hitCount = 0
for count in countList {
hitCount += count
}
sv = SliceValue.new
sv.hitCount = hitCount
return sv
}
# Called at each jumping window boundary
init(slice) {
rangeValue = RangeValue.new
rangeValue.hitCount = 0
return rangeValue
}
# Called after each reduce()
merge(rangeValue, slice, sliceValue) {
rangeValue.hitCount += sliceValue.hitCount
}
# Called when a slice fall out the sliding window
unmerge(rangeValue, slice, sliceValue) {
rangeValue.hitCount -= sliceValue.hitCount
}