Недавно MongoDB представил свою новую структуру агрегации . Эта структура предоставляет более простое решение для расчета агрегированных значений, вместо того чтобы полагаться на мощные конструкции с уменьшением карты. Имея всего несколько простых примитивов, он позволяет вам вычислять, группировать, изменять форму и проектировать документы, которые содержатся в определенной коллекции MongoDB. В оставшейся части этой статьи описывается рефакторинг алгоритма уменьшения карты для оптимального использования новой платформы агрегации MongoDB. Полный исходный код можно найти в общедоступном GitHub-хранилище Datablend .
1. Структура агрегирования MongoDB
Платформа агрегации MongoDB опирается на хорошо известную концепцию конвейера Linux , где вывод одной команды передается по конвейеру или перенаправляется для использования в качестве ввода следующей команды. В случае MongoDB несколько операторов объединяются в один конвейер, который отвечает за обработку потока документов. Некоторые операторы, такие как $ match , $ limit и $ skip, принимают документ в качестве входных данных и выводят один и тот же документ в случае соблюдения определенного набора критериев. Другие операторы, такие как $ project и $ unwind, принимают в качестве входных данных один документ и изменяют его формат или формируют несколько документов на основе определенной проекции. Оператор $ group, наконец, принимает в качестве входных данных несколько документов и группирует их в один документ путем объединения соответствующих значений. Выражения могут использоваться в некоторых из этих операторов для вычисления новых значений или выполнения строковых операций.
Несколько операторов объединяются в один конвейер, который применяется к списку документов. Сам конвейер выполняется как Команда MongoDB , в результате получается единый документ MongoDB, который содержит массив всех документов, которые вышли в конце конвейера. Следующий абзац подробно описывает рефакторинг алгоритма молекулярного сходства как конвейер операторов. Обязательно (пере) прочитайте предыдущие две статьи, чтобы полностью понять логику реализации.
2. Трубопровод молекулярного сходства
При применении конвейера к определенной коллекции все документы, содержащиеся в этой коллекции, передаются в качестве ввода первому оператору. Рекомендуется фильтровать этот список как можно быстрее, чтобы ограничить количество документов, которые передаются по конвейеру. В нашем случае это означает фильтрацию всего документа, который никогда не сможет удовлетворить целевой коэффициент Танимото . Следовательно, в качестве первого шага мы сопоставляем все документы, для которых количество отпечатков пальцев находится в пределах определенного порога. Если мы нацелены на коэффициент Танимото 0,8 с целевым соединением, содержащим 40 уникальных отпечатков пальцев, оператор $ match будет выглядеть следующим образом:
{ "$match" :
{ "fingerprint_count" : { "$gte" : 32 , "$lte" : 50}}
}
Только соединения с количеством отпечатков пальцев от 32 до 50 будут переданы следующему оператору трубопровода. Чтобы выполнить эту фильтрацию, оператор $ match может использовать индекс, который мы определили для свойства fingerprint_count . Для вычисления коэффициента Танимото нам нужно рассчитать количество общих отпечатков пальцев между определенным входным соединением и целевым соединением, на которое мы нацелены. Чтобы работать на уровне отпечатков пальцев, мы используем оператор $ unwind . $ unwind снимает элементы массива один за другим, возвращая поток документов, в котором указанный массив заменен одним из его элементов. В нашем случае мы применяем $ unwind к отпечаткам пальцев.имущество. Следовательно, каждый составной документ приведет к n составным документам, где n — количество уникальных отпечатков пальцев, содержащихся в составном документе.
{ "$unwind" : "$fingerprints"}
Чтобы рассчитать количество общих отпечатков, мы начнем с фильтрации всех документов, у которых нет отпечатков пальцев, которые есть в списке отпечатков пальцев целевого соединения. Для этого мы снова применяем оператор $ match , на этот раз фильтруя свойство отпечатков пальцев , где поддерживаются только те документы, которые содержат отпечаток, который находится в списке целевых отпечатков.
{ "$match" :
{ "fingerprints" :
{ "$in" : [ 1960 , 15111 , 5186 , 5371 , 756 , 1015 , 1018 , 338 , 325 , 776 , 3900 , ..., 2473] }
}
}
Поскольку мы сопоставляем только отпечатки пальцев, которые есть в списке целевых отпечатков, выходные данные можно использовать для подсчета общего количества общих отпечатков пальцев . Для этого мы применяем оператор $ group к составному соединению , хотя мы создаем новый тип документа, содержащий количество совпадающих отпечатков пальцев (путем суммирования количества вхождений), общее количество отпечатков входного соединения и смайлов. представительство .
{ "$group" :
{ "_id" : "$compound_cid" ,
"fingerprintmatches" : { "$sum" : 1} ,
"totalcount" : { "$first" : "$fingerprint_count"} ,
"smiles" : { "$first" : "$smiles"}
}
}
Теперь у нас есть все параметры для расчета коэффициента Танимото. Для этого мы будем использовать оператор $ project, который, помимо копирования составного свойства id и smiles, также добавляет новое вычисляемое свойство с именем tanimoto .
{
"$project"
:
{
"_id"
:
1
,
"tanimoto"
:
{
"$divide"
:
[
"$fingerprintmatches"
,
{
"$subtract"
:
[
{
"$add"
:
[
40
,
"$totalcount"
]
}
,
"$fingerprintmatches"
]
}
]
}
,
"smiles"
:
1
}
}
Поскольку нас интересуют только соединения, у которых целевой коэффициент Танимото равен 0,8, мы применяем дополнительный оператор $ match, чтобы отфильтровать все те, которые не достигают этого коэффициента.
{ "$match" :
{ "tanimoto" : { "$gte" : 0.8}
}
Команду полного трубопровода можно найти ниже.
{ "aggregate" : "compounds" ,
"pipeline" : [
{ "$match" :
{ "fingerprint_count" : { "$gte" : 32 , "$lte" : 50} }
},
{ "$unwind" : "$fingerprints"},
{ "$match" :
{ "fingerprints" :
{ "$in" : [ 1960 , 15111 , 5186 , 5371 , 756 , 1015 , 1018 , 338 , 325 , 776 , 3900, ... , 2473] }
}
},
{ "$group" :
{ "_id" : "$compound_cid" ,
"fingerprintmatches" : { "$sum" : 1} ,
"totalcount" : { "$first" : "$fingerprint_count"} ,
"smiles" : { "$first" : "$smiles"}
}
},
{ "$project" :
{ "_id" : 1 ,
"tanimoto" : { "$divide" : [ "$fingerprintmatches" , { "$subtract" : [ { "$add" : [ 89 , "$totalcount"]} , "$fingerprintmatches"] } ] } ,
"smiles" : 1
}
},
{ "$match" :
{ "tanimoto" : { "$gte" : 0.05} }
} ]
}
Выход этого трубопровода содержит список соединений , которые имеют Танимото 0,8 или выше по отношению к конкретному целевого соединения. Визуальное представление этого конвейера можно найти ниже:
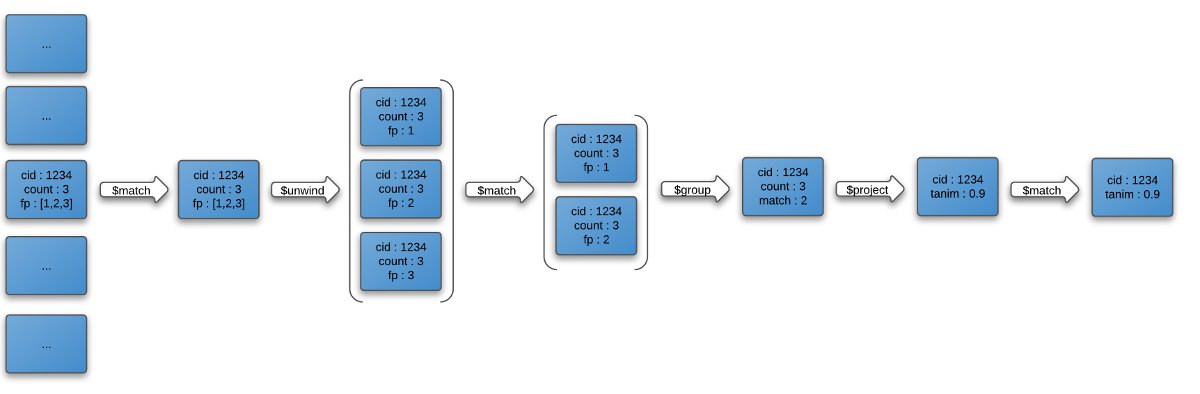
3. Вывод
Новая структура агрегации MongoDB предоставляет набор простых в использовании операторов, которые позволяют пользователям более кратко выражать алгоритмы типа сокращения карт . Понятие конвейера под ним предлагает интуитивно понятный способ обработки данных. Это не удивительно , что эта парадигма трубопровода принимается различными NoSQL подходов, в том числе Gremlin Framework Tinkerpop в и Cypher Neo4j в реализации.
С точки зрения производительности , конвейерное решение является существенным улучшением в реализации сокращения карт. Работающие операторы изначально поддерживаются платформой MongoDB , что приводит к значительному повышению производительности по отношению к интерпретируемому Javascript. Поскольку Aggregation Framework также может работать в изолированной среде , он легко превосходит производительность моей первоначальной реализации, особенно когда количество входных соединений велико, а целевой коэффициент Танимото низок. Отличная работа от команды MongoDB!