Некоторое время я работал над cycliинтерфейсом командной строки (CLI) для языка запросов Neo4j Cypher.
Как показано ниже, он автоматически заполняет метки вашего узла, типы отношений, ключи свойств и ключевые слова Cypher. Автозаполнение последнего в этом списке — ключевые слова Cypher — в центре внимания этого поста.

Цикли после обновления цепи Маркова.
Эта проблема
Первоначально ключевые слова Cypher предлагались просто в алфавитном порядке.
Тем не менее, это было слишком наивным: Если вы набрали W, например, меню автозавершения будет отображать предложения WHEN, WHEREи WITH в таком порядке, независимо от того , являются ли эти ключевые слова были признаны действительными или соответствующие учитывая контекст запроса.
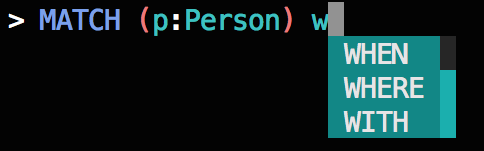
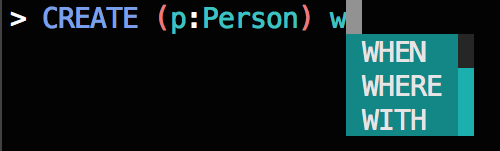
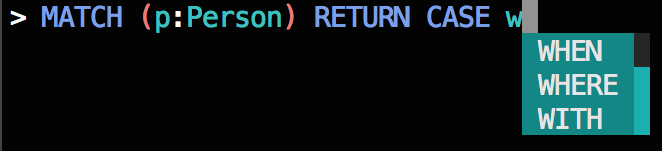
Это не хорошо:
- Приложение A —
WHENнедопустимое предложение послеMATCHключевого слова. - Приложение Б —
WHENи то, и другоеWHERE— недопустимые предложения послеCREATEключевого слова. - Приложение C — это единственный пример, в котором подходит первое предложенное ключевое слово, но это просто удача.
Для приведенных выше примеров, люди , которые знакомы с Cypher могут вам сказать , что из Cypher ключевых слов , которые начинаются с W, что WHEREи WITH ключевыми слова, скорее всего , следовать MATCH ключевому слову, то WITH ключевое слово, скорее всего , следовать CREATE ключевому слову и WHEN ключевым словом является наиболее вероятно, последует за CASE ключевым словом.
Для лучшего ввода текста W следует переключать меню автозаполнения, где порядок предлагаемых ключевых слов является функцией самого предыдущего ключевого слова в запросе.
Так как мне это реализовать?
Я, конечно, не собираюсь жестко кодировать любое из этих правил cycli вручную; скорее, я позволю данным говорить за себя.
Решение
Я удалил все запросы Cypher из всех GraphGists, перечисленных в вики GraphGist .
GraphGists — это то, что я люблю называть блокнотом Cypher для IPython: они позволяют вам создавать своего рода блокнот со встроенными запросами Cypher, где результаты отображаются в браузере. Это обеспечило хороший набор данных запросов Cypher для построения цепочки Маркова .
Как вы, возможно, читали в моем предыдущем сообщении в блоге :
Марковский процесс состоит из состояний и вероятностей, где вероятность перехода из одного состояния в другое зависит только от текущего состояния, а не от прошлого; это без памяти. Марковский процесс часто изображается в виде матрицы вероятности перехода, где запись (i, j)
этой матрицы представляет собой вероятность того, что марковский процесс переходит в состояние j,
учитывая, что процесс в настоящее время находится в состоянии i.
Мы можем легко применить эту идею к запросам Cypher, рассматривая каждое ключевое слово Cypher как состояние в марковском процессе.
Другими словами, если последнее введенное вами ключевое слово является MATCHтекущим, то вы находитесь в MATCH состоянии процесса Маркова и существует набор вероятностей, указывающих, какие состояния или ключевые слова Cypher вы, скорее всего, будете вводить / использовать следующим.
Решение тогда состоит в том, чтобы построить матрицу вероятности перехода с нашим образцом набора запросов Cypher.
методология
Для демонстрации давайте представим, что следующие запросы Cypher составляют наш примерный набор данных. Давайте также представим, что ключевые слова Cypher состоят только из ключевых слов в этих запросах.
keywords = ["CREATE", "RETURN", "MATCH", "WHERE", "WITH"]
queries = [
"MATCH n WHERE n.name = 'Nicole' WITH n RETURN n;",
"MATCH n WHERE n.age > 50 RETURN n;",
"MATCH n WITH n RETURN n.age;",
"CREATE n RETURN n;",
]Сначала я решил сохранить марковский процесс в словаре словарей, чтобы к ним можно было получить доступ markov["i"]["j"]к вероятностям, то есть вероятности того, что следующим ключевым словом будет j , если текущим ключевым словом является i .
Я включил дополнительное состояние — пустое состояние (представленное пустой строкой), чтобы также охватить случай, когда нет предыдущих ключевых слов, поскольку мы все еще хотим рекомендовать ключевые слова, упорядоченные по наиболее вероятному даже для первого ключевого слова в запрос.
Сначала я строю исходную структуру данных.
states = [""] + keywords
markov = {i: {j:0.0 for j in states} for i in states}
print(markov){
"": {
"": 0.0,
"CREATE": 0.0,
"MATCH": 0.0,
"RETURN": 0.0,
"WHERE": 0.0,
"WITH": 0.0
},
"CREATE": {
"": 0.0,
"CREATE": 0.0,
"MATCH": 0.0,
"RETURN": 0.0,
"WHERE": 0.0,
"WITH": 0.0
},
"MATCH": {
"": 0.0,
"CREATE": 0.0,
"MATCH": 0.0,
"RETURN": 0.0,
"WHERE": 0.0,
"WITH": 0.0
},
"RETURN": {
"": 0.0,
"CREATE": 0.0,
"MATCH": 0.0,
"RETURN": 0.0,
"WHERE": 0.0,
"WITH": 0.0
},
"WHERE": {
"": 0.0,
"CREATE": 0.0,
"MATCH": 0.0,
"RETURN": 0.0,
"WHERE": 0.0,
"WITH": 0.0
},
"WITH": {
"": 0.0,
"CREATE": 0.0,
"MATCH": 0.0,
"RETURN": 0.0,
"WHERE": 0.0,
"WITH": 0.0
}
}Далее, для каждого запроса я нахожу позиции каждого ключевого слова и упорядочиваю ключевые слова по этим позициям по возрастанию.
Затем я перебираю этот список ключевых слов и увеличиваю markov["i"]["j"] значение на 1 каждый раз, когда вижу ключевое слово j, следующее за ключевым словом i .
Обратите внимание, что фактическая реализация немного сложнее, поскольку она старается не включать слова, которые являются метками узлов, типами отношений, строками и т. Д.
import re
for query in queries:
# Find the positions of Cypher keywords.
positions = []
for word in keywords:
idx = [m.start() for m in re.finditer(word, query)]
for i in idx:
positions.append((word, i))
# Sort the words by the order of their positions in the query.
positions.sort(key=lambda x: x[1])
# Drop the indexes.
positions = [x[0] for x in positions]
# Prepend the empty state to the list of keywords.
positions = [""] + positions
# Build the Markov model.
for i in range(len(positions) - 1):
current_keyword = positions[i]
next_keyword = positions[i + 1]
markov[current_keyword][next_keyword] += 1
print(markov){
"": {
"": 0.0,
"CREATE": 1.0,
"MATCH": 3.0,
"RETURN": 0.0,
"WHERE": 0.0,
"WITH": 0.0
},
"CREATE": {
"": 0.0,
"CREATE": 0.0,
"MATCH": 0.0,
"RETURN": 1.0,
"WHERE": 0.0,
"WITH": 0.0
},
"MATCH": {
"": 0.0,
"CREATE": 0.0,
"MATCH": 0.0,
"RETURN": 0.0,
"WHERE": 2.0,
"WITH": 1.0
},
"RETURN": {
"": 0.0,
"CREATE": 0.0,
"MATCH": 0.0,
"RETURN": 0.0,
"WHERE": 0.0,
"WITH": 0.0
},
"WHERE": {
"": 0.0,
"CREATE": 0.0,
"MATCH": 0.0,
"RETURN": 1.0,
"WHERE": 0.0,
"WITH": 1.0
},
"WITH": {
"": 0.0,
"CREATE": 0.0,
"MATCH": 0.0,
"RETURN": 2.0,
"WHERE": 0.0,
"WITH": 0.0
}
}Затем я делю каждое значение в каждой строке на сумму строки, чтобы у меня были вероятности.
for word, states in markov.items():
denominator = sum(states.values())
if denominator == 0:
# Absorbing state.
markov[word] = {i: 1.0 if i == word else 0.0 for i in states.keys()}
elif denominator > 0:
markov[word] = {i:j / denominator for i, j in states.items()}
print(markov){
"": {
"": 0.0,
"CREATE": 0.25,
"MATCH": 0.75,
"RETURN": 0.0,
"WHERE": 0.0,
"WITH": 0.0
},
"CREATE": {
"": 0.0,
"CREATE": 0.0,
"MATCH": 0.0,
"RETURN": 1.0,
"WHERE": 0.0,
"WITH": 0.0
},
"MATCH": {
"": 0.0,
"CREATE": 0.0,
"MATCH": 0.0,
"RETURN": 0.0,
"WHERE": 0.6666666666666666,
"WITH": 0.3333333333333333
},
"RETURN": {
"": 0.0,
"CREATE": 0.0,
"MATCH": 0.0,
"RETURN": 1.0,
"WHERE": 0.0,
"WITH": 0.0
},
"WHERE": {
"": 0.0,
"CREATE": 0.0,
"MATCH": 0.0,
"RETURN": 0.5,
"WHERE": 0.0,
"WITH": 0.5
},
"WITH": {
"": 0.0,
"CREATE": 0.0,
"MATCH": 0.0,
"RETURN": 1.0,
"WHERE": 0.0,
"WITH": 0.0
}
}The probabilities in each row now sum to 1.
Finally, I convert the dictionaries to a list of tuples so that they can be maintained in order of probability descending (dictionaries have no sense of order).
for word in markov.keys():
ordered = sorted(markov[word].items(), key=lambda x:x[1], reverse=True)
markov[word] = orderedNow, I have a data structure that can tell me which keywords are most likely to be used next given the current keyword.
For example, with this pretend dataset, if the current keyword is MATCH, then the probability of the next keyword being WHERE is 67% and the probability of the next keyword being WITH is 33%:
for state in markov["MATCH"]:
print(state)('WHERE', 0.6666666666666666)
('WITH', 0.3333333333333333)
('', 0.0)
('RETURN', 0.0)
('CREATE', 0.0)
('MATCH', 0.0)Ship It!
This workflow was applied to the full sample of Cypher queries scraped from the GraphGists wiki and the resulting data structure – the dictionary of tuples – is now included in cycli to make smarter autocomplete suggestions for Cypher keywords.
Let’s look at the real data for a few keywords.
from cycli.markov import markovMATCH
If your most recent keyword is MATCH:
for state in markov["MATCH"][:5]:
print(state)('CREATE', 0.7143900657414171)
('MATCH', 0.10689067445824203)
('WHERE', 0.0723155588020453)
('RETURN', 0.0577063550036523)
('WITH', 0.01996591185780375)CREATE
If your most recent keyword is CREATE:
for state in markov["CREATE"][:5]:
print(state)('CREATE', 0.7466683589287981)
('UNIQUE', 0.24152811270465796)
('RETURN', 0.002792232516816855)
('DELETE', 0.002284553877395609)
('INDEX', 0.0020307145576849853)COUNT
If your most recent keyword is COUNT:
for state in markov["COUNT"][:5]:
print(state)('AS', 0.875)
('COLLECT', 0.07142857142857142)
('DESC', 0.017857142857142856)
('ORDER', 0.017857142857142856)
('ASC', 0.017857142857142856)The Results
Revisiting the examples from earlier, where typing a W in previous versions of cycli yielded an alphabetical list of Cypher keywords with no regard to whether or not they were valid or appropriate, we now get a list of autocompletions where the order of the keyword suggestions is tailored to the context of the query.
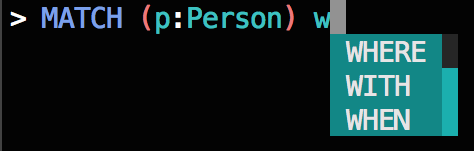
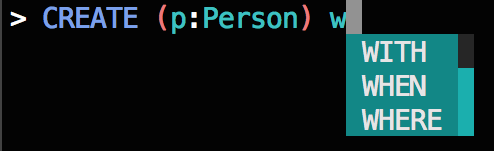
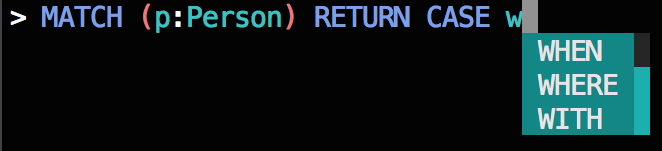
Much better:
- Exhibit A –
WHEREandWITHare appropriate suggestions to follow aMATCHkeyword and are ordered correctly, asWHEREis more likely to follow thanWITH. - Exhibit B – In the case of the
CREATEkeyword,WITHis the best suggestion as bothWHENandWHEREare invalid. - Exhibit C –
WHENis the only valid suggestion for a keyword following theCASEkeyword.
This is easily accomplished behind the scenes with the markov chain data structure now included in cycli.
Exhibit A
for word, probability in markov["MATCH"]:
if word.startswith("W"):
print(word, probability)WHERE 0.0723155588020453
WITH 0.01996591185780375
WHEN 0.0Exhibit B
for word, probability in markov["CREATE"]:
if word.startswith("W"):
print(word, probability)WITH 0.0013961162584084274
WHEN 0.0
WHERE 0.0Exhibit C
for word, probability in markov["CASE"]:
if word.startswith("W"):
print(word, probability)WHEN 0.9666666666666667
WITH 0.0
WHERE 0.0Next Steps
While cycli is only utilizing the one-step probabilities in this Markov process, I wanted to build this data structure to open the door for some fun, offline analysis of the Cypher query language.
With a Markov chain, I can answer questions like:
- What is the steady state distribution of a Cypher query?
- What is the expected number of steps until a user reaches the
COLLECTstate? - Given that a user is currently in the
MATCHstate, what is the expected number of steps until the user returns to theMATCHstate?
I plan to answer these types of questions in a future post.
This article was written by Nicole White.
[This post was originally published on Nicole White’s blog and was used with permission.]