На прошлой неделе с @ 3wen мы работали над пересмотренной версией нашей работы по сглаживанию плотностей пространственных процессов (с коррекцией краев). Обычно, после того как вы исправили статью, некоторые ссылки были добавлены, другие были отброшены. Но вам нужно потратить некоторое время, чтобы убедиться, что все ссылки действительно упоминаются в документе. Например, рассмотрим следующий скомпилированный текстовый файл:

На самом деле в документе упоминаются только три ссылки, поэтому нам нужно обновить список ссылок (удалив первые три). Если вы используете нагрудный файл, это очень просто, и в списке появятся только цитируемые ссылки. Проблема здесь в том, что мы использовали bibitems,
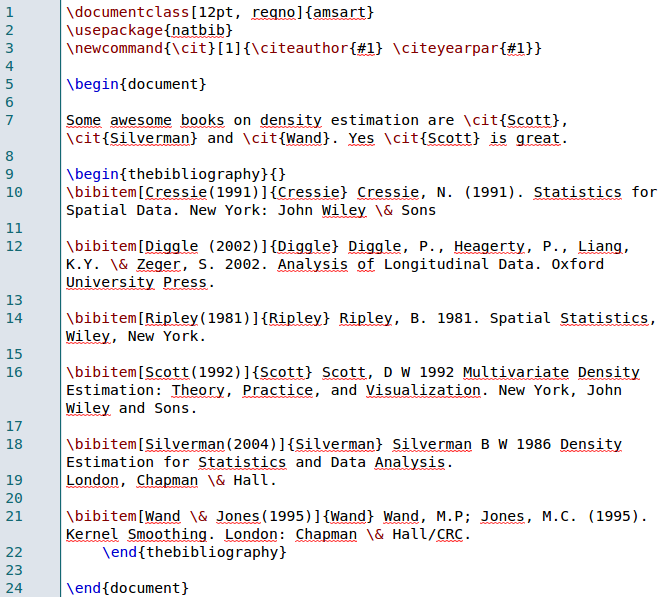
Я хотел поработать над этим вручную в этот уик-энд, но @ 3wen предложил написать простую R-функцию для сканирования файла tex f (а также файла aux на самом деле), чтобы удалить ссылки без цитирования. Идея заключается в следующем. Во-первых, давайте отсканируем два файла
> library(stringr) > setwd("/home/tex/") > file_tex <- scan("file_test.tex", what = "character", sep = "\n") Read 15 items > file_aux <- scan("file_test.aux", what = "character", sep = "\n") Read 21 items
Затем мы извлекаем только части, связанные с библиографией,
> beg_file <- which(str_detect(string = file_tex, pattern = "\\\\begin\\{thebibliography\\}")) > end_file <- which(str_detect(string = file_tex, pattern = "\\\\end\\{thebibliography\\}"))
Ссылки здесь следующие строки
> biblio <- file_tex[seq(beg_file+1, end_file-1)] > biblio [1] "\\bibitem[Cressie(1991)]{Cressie} Cressie, N. (1991). Statistics for Spatial Data. New York: John Wiley \\& Sons" [2] "\\bibitem[Diggle (2002)]{Diggle} Diggle, P., Heagerty, P., Liang, K.Y. \\& Zeger, S. 2002. Analysis of Longitudinal Data. Oxford University Press." [3] "\\bibitem[Ripley(1981)]{Ripley} Ripley, B. 1981. Spatial Statistics, Wiley, New York." [4] "\\bibitem[Scott(1992)]{Scott} Scott, D W 1992 Multivariate Density Estimation: Theory, Practice, and Visualization. New York, John Wiley and Sons." [5] "\\bibitem[Silverman(2004)]{Silverman} Silverman B W 1986 Density Estimation for Statistics and Data Analysis." [6] "London, Chapman \\& Hall." [7] "\\bibitem[Wand \\& Jones(1995)]{Wand} Wand, M.P; Jones, M.C. (1995). Kernel Smoothing. London: Chapman \\& Hall/CRC. "
Если вы внимательно посмотрите на вывод, вы можете заметить, что пятая ссылка находится на двух строках. Что может случиться часто. Поэтому нам нужно точно проверить, когда начинается ссылка и когда она заканчивается.
> beg_bibitem <- which(str_detect(string = biblio, pattern = "\\\\bibitem")) > go_through <- cbind(beg_bibitem, c(beg_bibitem[-1]-1,length(biblio))) > go_through beg_bibitem [1,] 1 1 [2,] 2 2 [3,] 3 3 [4,] 4 4 [5,] 5 6 [6,] 7 7
На самом деле, мы также должны проверить, если ссылка цитируется. Иногда есть ссылки со знаком комментария.
> go_through <- data.frame(beg = beg_bibitem, end = rep(NA, length(beg_bibitem))) > for(i in seq_len(length(beg_bibitem))-1){ + go_through[i,2] <- beg_bibitem[i+1]-1 + } > go_through[nrow(go_through), 2] <- length(biblio) > go_through$comment <- str_detect(biblio[beg_bibitem], "^%") > go_through beg end comment 1 1 1 FALSE 2 2 2 FALSE 3 3 3 FALSE 4 4 4 FALSE 5 5 6 FALSE 6 7 7 FALSE
Давайте теперь извлечем метки всех ссылок (%).
> extract_ref_cite <- function(bibitem, file){ + entree <- file[bibitem] + if(str_detect(entree, "bibitem\\[.*\\]\\{")){ + nom_citation <- str_extract(entree, "]\\{(.*?)\\}") + }else{ + nom_citation <- str_extract(entree, "\\{(.*?)\\}") + } + str_replace_all(string = nom_citation, pattern = "\\{|\\}|]", replacement = "") + } > bibitems_ref <- unlist(lapply(beg_bibitem, extract_ref_cite, biblio)) > bibitems_ref [1] "Cressie" "Diggle" "Ripley" "Scott" "Silverman" "Wand"
У нас есть шесть ссылок с этими ярлыками (как и ожидалось).
Теперь, если мы посмотрим на файл aux , чтобы увидеть, какие ссылки цитируются в тексте,
> ind_cite <- which(str_detect(string = file_aux, pattern = "\\\\citation")) > bibitems_cite_names <- unlist(lapply(ind_cite, extract_ref_cite, file_aux)) > bibitems_cite_names [1] "Scott" "Scott" "Silverman" "Silverman" "Wand" "Wand" [7] "Scott" "Scott"
Обратите внимание, что ссылки упоминаются дважды (как минимум): один раз для имени автора, один раз для года публикации. Так как нам просто нужно увидеть, какой из них действительно появляется в aux- файле, мы можем использовать
> bibitems_cite_names <- unique(bibitems_cite_names) > bibitems_cite_names [1] "Scott" "Silverman" "Wand"
Теперь мы можем видеть, какие ссылки цитируются,
> go_through$keep <- bibitems_ref %in% bibitems_cite_names > go_through beg end comment keep 1 1 1 FALSE FALSE 2 2 2 FALSE FALSE 3 3 3 FALSE FALSE 4 4 4 FALSE TRUE 5 5 6 FALSE TRUE 6 7 7 FALSE TRUE
Основываясь на этой таблице, мы можем использовать простой код: ссылки, которые нам не нужны, будут рассматриваться как комментарии, а цитируемые ссылки будут отображаться в списке ссылок.
> return_cite <- function(one_ligne){ + citation <- str_c(biblio[one_ligne[1,"beg"]:one_ligne[1,"end"]], collapse = "\n") + if(!one_ligne[1,"keep"] & !str_detect(citation, "^%")){ + citation <- str_replace_all(citation, pattern = "\n", replacement = "\n%") + } + citation + }
Например,
> return_cite(go_through[1,])
[1] "%\\bibitem[Cressie(1991)]{Cressie} Cressie, N. (1991). Statistics for Spatial Data. New York: John Wiley \\& Sons"
поскольку первая ссылка не появляется в тексте, а
> return_cite(go_through[4,])
[1] "\\bibitem[Scott(1992)]{Scott} Scott, D W 1992 Multivariate Density Estimation: Theory, Practice, and Visualization. New York, John Wiley and Sons."
Теперь мы можем легко создать нашу библиографию в LaTeX
> cat(unlist(lapply(1:nrow(go_through), function(x) return_cite(go_through[x,]))), sep = "\n\n") %\bibitem[Cressie(1991)]{Cressie} Cressie, N. (1991). Statistics for Spatial Data. New York: John Wiley \& Sons %\bibitem[Diggle (2002)]{Diggle} Diggle, P., Heagerty, P., Liang, K.Y. \& Zeger, S. 2002. Analysis of Longitudinal Data. Oxford University Press. %\bibitem[Ripley(1981)]{Ripley} Ripley, B. 1981. Spatial Statistics, Wiley, New York. \bibitem[Scott(1992)]{Scott} Scott, D W 1992 Multivariate Density Estimation: Theory, Practice, and Visualization. New York, John Wiley and Sons. \bibitem[Silverman(2004)]{Silverman} Silverman B W 1986 Density Estimation for Statistics and Data Analysis. London, Chapman \& Hall. \bibitem[Wand \& Jones(1995)]{Wand} Wand, M.P; Jones, M.C. (1995). Kernel Smoothing. London: Chapman \& Hall/CRC.
Нам просто нужно скопировать этот список и вставить его в наш файл LaTeX . Хорошо, не правда ли?