
Titan — это лицензированная распределенная графовая база данных Apache 2 , способная поддерживать десятки тысяч одновременно работающих пользователей, читающих и пишущих в одном крупномасштабном графе . Чтобы обосновать вышеупомянутое утверждение, в этом посте представлены эмпирические результаты Titan, поддерживающего симулированный сайт социальной сети, подвергающийся транзакционным нагрузкам, оцениваемым в 50 000–100 000 одновременных пользователей. Эти пользователи взаимодействуют с 40 m1.small серверами Amazon EC2, которые работают с 6-ти машинным кластером Amazon EC2 cc1.4xl Titan / Cassandra .
В следующей презентации обсуждается структура социального графа моделирования, типы процессов, выполняемых в этой структуре, а также различные анализы времени выполнения этих процессов при нормальной и пиковой нагрузке. Презентация заканчивается обсуждением используемой кластерной архитектуры Amazon EC2 и связанных с этим затрат на ее эксплуатацию в производственной среде. Вкратце, Titan хорошо работает при существенной нагрузке с относительно недорогим кластером и, таким образом, способен поддерживать онлайн-сервисы, требующие больших графических данных в реальном времени.
Структура и процессы социального графа
Онлайн-сервис социальной сети, такой как Twitter, обычно поддерживает 5 операций, перечисленных ниже.
- создать учетную запись : создать нового пользователя с указанным дескриптором.
- опубликовать твит : распространить сообщение <140 символов.
- читать поток : получить упорядоченный по времени список из 10 твитов от подписчиков.
- подписаться на пользователя : подписаться на твиты другого пользователя.
- получить рекомендацию : получить приглашение от потенциально интересных пользователей.
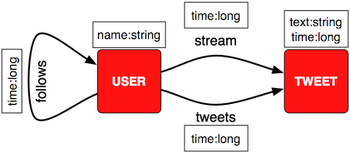 Эти операции приводят к появлению структуры графа свойств, эпиморфной схеме, изображенной справа. В этой схеме есть пользовательские вершины и твиты. Когда пользователь пишет в Твиттере, край твита соединяет пользователя с его твитом. Более того, все последователи этого пользователя (то есть подписчики) имеют временную метку края исходящего потока, присоединяющую свою вершину к твиту. Для каждой пользовательской вершины края потока отсортированы по времени, поскольку в этой системе время является объявленным первичным ключом. Titan поддерживает вершинно-ориентированные индексыкоторые обеспечивают O (log (n)) поиск соседних вершин на основе меток и свойств падающих ребер, где n — количество ребер, исходящих из вершины. Для симуляции искусственно сгенерированные твиты представляют собой случайно выбранные фрагменты из «Одиссеи» Гомера (согласно проекту Гутенберга ), где длина выбирается из гауссовского распределения со средним числом 70 символов.
Эти операции приводят к появлению структуры графа свойств, эпиморфной схеме, изображенной справа. В этой схеме есть пользовательские вершины и твиты. Когда пользователь пишет в Твиттере, край твита соединяет пользователя с его твитом. Более того, все последователи этого пользователя (то есть подписчики) имеют временную метку края исходящего потока, присоединяющую свою вершину к твиту. Для каждой пользовательской вершины края потока отсортированы по времени, поскольку в этой системе время является объявленным первичным ключом. Titan поддерживает вершинно-ориентированные индексыкоторые обеспечивают O (log (n)) поиск соседних вершин на основе меток и свойств падающих ребер, где n — количество ребер, исходящих из вершины. Для симуляции искусственно сгенерированные твиты представляют собой случайно выбранные фрагменты из «Одиссеи» Гомера (согласно проекту Гутенберга ), где длина выбирается из гауссовского распределения со средним числом 70 символов.
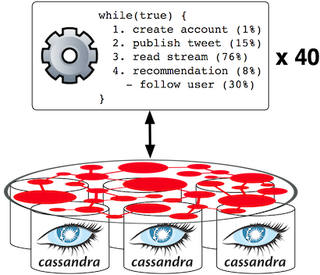 Чтобы обеспечить базовый уровень данных, график Twitter с 2009 года был сначала загружен в кластер Titan. Эти данные включают в себя 41,7 миллиона пользовательских вершин и 1,47 миллиарда следующих ребер. После загрузки 40 m1.small машин помещаются в «цикл while (true)» (на самом деле на каждом работнике 10 одновременных потоков, выполняющих 125 000 итераций). Во время каждой итерации цикла работник выбирает операцию, которую необходимо выполнить, используя пристрастное подбрасывание монеты (см. Схему слева). Распределение сильно благоприятствует потоковому чтению, поскольку это обычно самая распространенная операция в таких онлайн-социальных системах. Далее, если будет предоставлена рекомендация , существует 30% вероятность того, что пользователь последует за одним из рекомендованных пользователей. Вот как следующие ребра добавляются к графику.
Чтобы обеспечить базовый уровень данных, график Twitter с 2009 года был сначала загружен в кластер Titan. Эти данные включают в себя 41,7 миллиона пользовательских вершин и 1,47 миллиарда следующих ребер. После загрузки 40 m1.small машин помещаются в «цикл while (true)» (на самом деле на каждом работнике 10 одновременных потоков, выполняющих 125 000 итераций). Во время каждой итерации цикла работник выбирает операцию, которую необходимо выполнить, используя пристрастное подбрасывание монеты (см. Схему слева). Распределение сильно благоприятствует потоковому чтению, поскольку это обычно самая распространенная операция в таких онлайн-социальных системах. Далее, если будет предоставлена рекомендация , существует 30% вероятность того, что пользователь последует за одним из рекомендованных пользователей. Вот как следующие ребра добавляются к графику.
 Придерживающаяся рекомендация (например, « кому следовать ») использует существующие нижние границы, чтобы определить для конкретного пользователя других пользователей, которых они могут найти интересными. Как правило, в таких ситуациях вычисляется некоторый вариант замыкания треугольника . Говоря простым языком, если пользователи, за которыми следует пользователь A, стремятся следовать за пользователем B, то наиболее вероятно, что пользователь B является хорошим пользователем для пользователя A, которому нужно следовать. Чтобы охватить это понятие как алгоритм графа в реальном времени, используется язык обхода графа Гремлин .
Придерживающаяся рекомендация (например, « кому следовать ») использует существующие нижние границы, чтобы определить для конкретного пользователя других пользователей, которых они могут найти интересными. Как правило, в таких ситуациях вычисляется некоторый вариант замыкания треугольника . Говоря простым языком, если пользователи, за которыми следует пользователь A, стремятся следовать за пользователем B, то наиболее вероятно, что пользователь B является хорошим пользователем для пользователя A, которому нужно следовать. Чтобы охватить это понятие как алгоритм графа в реальном времени, используется язык обхода графа Гремлин .
follows = g.V('name',name).out('follows').toList()
follows20 = follows[(0..19).collect{random.nextInt(follows.size)}]
m = [:]
follows20.each { it.outE('follows')[0..29].inV.except(follows).groupCount(m).iterate() }
m.sort{a,b -> b.value <=> a.value}[0..4]
- Извлеките всех пользователей, за которыми следует пользователь, где name — уникальный дескриптор пользователя Twitter.
- Произвольно выберите 20 из тех пользователей, за которыми следуют (обеспечивает вариации для каждого вызова — недетерминированные ).
- Создайте пустой ассоциативный массив / карту, которая будет заполнена рейтингом рекомендаций.
- Для каждого из 20 случайно выбранных пользователей найдите 30 последних подписавшихся пользователей, которые еще не подписались, и запишите их на карту.
- Переверните карту и верните 5 лучших пользователей в качестве рекомендаций.
Обратите внимание, что вершинно-ориентированные индексы снова вступают в игру в строке 4, где следующие ребра (например, ребра потока ) имеют первичный ключ времени и, таким образом, расположены в хронологическом порядке. 30 самых недавних пользователей — это один поиск O (log (n)), где, опять же, n — это число ребер, исходящих из вершины.
Titan, обслуживающий 50 000–100 000 одновременно работающих пользователей
Titan — это графическая база данных OLTP . Он предназначен для обработки множества коротких параллельных транзакций, подобных тем, которые обсуждались ранее. В этом разделе представлена производительность Titan при нормальной (5900 транзакций в секунду) и пиковой (10 200 транзакций в секунду) нагрузке. Мы считаем, что последующее является разумным эталоном: никакого специализированного оборудования не требуется (стандартные машины EC2), никаких сложных конфигураций / настроек Cassandra или Titan, а весь рабочий код выполняется через стандартный API Blueprints .
Нормальная нагрузка
 Моделирование нормальной нагрузки длилось 2,3 часа, и за это время было выполнено 49 миллионов транзакций . Это примерно 5900 транзакций в секунду . Предполагая, что пользователь совершает транзакцию каждые 5-10 секунд (например, читает свой поток, а затем публикует твит и т. Д.), Этот кластер Titan поддерживает около 50 000 одновременно работающих пользователей . В приведенной ниже таблице указано количество транзакций на операцию, среднее время транзакций, стандартное отклонение этих времен и сигма 3времена представлены. 3 сигма на 3 стандартных отклонения больше среднего и представляют ожидаемое время наихудшего случая, с которым столкнется 0,1% пользователей. Наконец, обратите внимание, что создание учетной записи является более медленной транзакцией, поскольку это операция блокировки, которая гарантирует, что никакие два пользователя не будут иметь одинаковые имена пользователей (т. Е. Дескриптор Twitter).
Моделирование нормальной нагрузки длилось 2,3 часа, и за это время было выполнено 49 миллионов транзакций . Это примерно 5900 транзакций в секунду . Предполагая, что пользователь совершает транзакцию каждые 5-10 секунд (например, читает свой поток, а затем публикует твит и т. Д.), Этот кластер Titan поддерживает около 50 000 одновременно работающих пользователей . В приведенной ниже таблице указано количество транзакций на операцию, среднее время транзакций, стандартное отклонение этих времен и сигма 3времена представлены. 3 сигма на 3 стандартных отклонения больше среднего и представляют ожидаемое время наихудшего случая, с которым столкнется 0,1% пользователей. Наконец, обратите внимание, что создание учетной записи является более медленной транзакцией, поскольку это операция блокировки, которая гарантирует, что никакие два пользователя не будут иметь одинаковые имена пользователей (т. Е. Дескриптор Twitter).
| действие | количество тх | среднее время передачи | стандартное время | Время 3 сигма |
|---|---|---|---|---|
| завести аккаунт | 379019 | 115,15 мс | 5,88 мс | 132,79 мс |
| опубликовать твит | 7580995 | 18,45 мс | 6,34 мс | 37,48 мс |
| читать поток | 37936184 | 6,29 мс | 1,62 мс | 11,15 мс |
| получить рекомендацию | 3793863 | 67,65 мс | 13,89 мс | 109,33 мс |
| общее | 49690061 |
После 2,3 часов вышеупомянутых транзакций в существующий график Twitter за 2009 год были добавлены следующие типы вершин и ребер. Справа приведена статистика с учетом этого поведения за день.
| 2,3 часа | 1 день |
|---|---|
|
|
Пиковая нагрузка
 Чтобы определить, как Titan будет работать в среде пиковой нагрузки, 40 рабочих машин вместе выполняли 10 200 транзакций в секунду за 1,3 часа (всего 49 миллионов транзакций ). Это моделирует примерно 100 000 одновременных пользователей . Номера транзакций и статистика по времени представлены в таблице ниже. Обратите внимание, что более высокие задержки ожидаются при более высокой нагрузке и что, хотя время транзакций больше, чем при нормальной нагрузке, время все еще приемлемо для онлайн-службы в реальном времени.
Чтобы определить, как Titan будет работать в среде пиковой нагрузки, 40 рабочих машин вместе выполняли 10 200 транзакций в секунду за 1,3 часа (всего 49 миллионов транзакций ). Это моделирует примерно 100 000 одновременных пользователей . Номера транзакций и статистика по времени представлены в таблице ниже. Обратите внимание, что более высокие задержки ожидаются при более высокой нагрузке и что, хотя время транзакций больше, чем при нормальной нагрузке, время все еще приемлемо для онлайн-службы в реальном времени.
| действие | количество тх | среднее время передачи | стандартное время | Время 3 сигма |
|---|---|---|---|---|
| завести аккаунт | 374860 | 172,74 мс | 10,52 мс | 204,29 мс |
| опубликовать твит | 7517667 | 70,07 мс | 19,43 мс | 128,35 мс |
| читать поток | 37618648 | 24,40 мс | 3,18 мс | 33,93 мс |
| получить рекомендацию | 3758266 | 229,83 мс | 29,08 мс | 317,06 мс |
| общее | 49269441 |
Amazon EC2 Machinery и расходы
 Представленная симуляция была выполнена на Amazon EC2 . Программная инфраструктура для запуска этого моделирования использовала CloudFormation . Что касается аппаратной инфраструктуры, в этом разделе обсуждаются типы экземпляров , их физическая статистика в ходе эксперимента и стоимость запуска этой архитектуры в производственной среде.
Представленная симуляция была выполнена на Amazon EC2 . Программная инфраструктура для запуска этого моделирования использовала CloudFormation . Что касается аппаратной инфраструктуры, в этом разделе обсуждаются типы экземпляров , их физическая статистика в ходе эксперимента и стоимость запуска этой архитектуры в производственной среде.
40 рабочих были m1.small экземпляров Amazon EC2 (1,7 ГБ памяти с 1 виртуальным ядром). Кластер Titan / Cassandra состоял из 6 машин, каждая из которых имела следующую спецификацию.
- 23 ГБ памяти
- 33,5 вычислительных блока EC2 (2 x Intel Xeon X5570, четырехъядерная архитектура Nehalem )
- 1 690 ГБ памяти
- 64-битная платформа
- 10 гигабитный Ethernet
- Имя API EC2: cc1.4xlarge
При моделировании нормальной нагрузки кластер Titan с 6 компьютерами испытывал следующее использование ЦП, чтение с диска (в байтах) и запись на диск (в байтах) — каждая цветная линия представляет 1 из 6 машин cc1.4xlarge. Обратите внимание, что диаграмма чтения с диска — это снимок за 1 час в середине эксперимента, поэтому кеши теплые. Таким образом, Titan способен последовательно и без усилий поддерживать нормальную транзакционную нагрузку.



Стоимость запуска всех этих машин указана в таблице ниже. Обратите внимание, что в производственной среде (без моделирования) 40 рабочих могут интерпретироваться как веб-серверы, принимающие пользовательские запросы и обрабатывающие результаты, возвращаемые из кластера Titan.
| пример | стоимость за час | стоимость за день | стоимость в год |
|---|---|---|---|
| 6 куб. См | $ 7,80 | $ 187,20 | $ 68328 |
| 40 м.лм | $ 3,20 | $ 76,80 | $ 28032 |
| общее | $ 11,00 | $ 264,00 | $ 96360 |
Для обслуживания 50 000–100 000 одновременно работающих пользователей 96 360 долл. США в год недороги, учитывая поступление доходов, получаемых от базы пользователей такого размера (предположим, что 5% базы пользователей одновременно: ~ 2 миллиона зарегистрированных пользователей). Кроме того, Titan можно развернуть на произвольном количестве машин и динамически масштабировать для удовлетворения требований к нагрузке (см . Преимущества Titan ). Следовательно, эта архитектура 6 cc1.4xl является не необходимостью, а конкретной конфигурацией, которая была исследована для целей представленной социальной симуляции. Для сред с меньшей нагрузкой можно и нужно использовать меньший кластер.
Вывод
Титан занимается исследованиями и разработками в течение последних 4 лет. Весной 2012 года Aurelius предоставил бесплатный доступ к Titan под свободной лицензией Apache 2 . В настоящее время он распространяется в виде альфа-версии 0.1, выпуск которого запланирован на конец лета 2012 года.
 Обратите внимание, что Титан — это всего лишь одна часть большой головоломки. Titan обслуживает OLTP- аспект обработки графиков. К середине осени 2012 года Aurelius выпустит коллекцию графических технологий OLAP для поддержки глобальной обработки и аналитики графов. Все технологии Aurelius будут интегрироваться друг с другом, а также с набором графических технологий BSD с открытым исходным кодом, предоставляемых TinkerPop . Стоя на плечах гигантов (например, Cassandra, TinkerPop, Amazon EC2), возможны большие скачки в прикладной теории графов и сетевых науках .
Обратите внимание, что Титан — это всего лишь одна часть большой головоломки. Titan обслуживает OLTP- аспект обработки графиков. К середине осени 2012 года Aurelius выпустит коллекцию графических технологий OLAP для поддержки глобальной обработки и аналитики графов. Все технологии Aurelius будут интегрироваться друг с другом, а также с набором графических технологий BSD с открытым исходным кодом, предоставляемых TinkerPop . Стоя на плечах гигантов (например, Cassandra, TinkerPop, Amazon EC2), возможны большие скачки в прикладной теории графов и сетевых науках .
Рекомендации
Квак, Х., Ли, С., Парк, Х., Мун, С. « Что такое Твиттер, социальная сеть или средства массовой информации? «World Wide Web Conference, 2010.
Родригес, М.А., Бройчелер, М., « Титан: рост больших графовых данных », публичная лекция в Jive Software, Пало-Альто, 2012.
Broecheler, M., LaRocque, D., Rodriguez, MA, « Титан: масштабируемая база данных распределенных графов », GraphLab Workshop 2012, Сан-Франциско, 2012.