Идея этой статьи состоит в том, чтобы перечислить как можно больше примеров вложенных элементов JSON, включение примеров данных, преобразование реляционных данных в данные JSON, JSON в реляционные данные, преобразование элементов JSON в отдельные столбцы и представление тех же данных в отдельные строки.
JSON означает JavaScript Object Notation. JSON является основным представлением данных для всех баз данных NoSQL . Это естественно подходит для разработчиков, которые используют JSON в качестве формата обмена данными в своих приложениях. Относительная способность JSON (записи JSON хорошо структурированы, но легко расширяются) в отношении его масштабируемости привлекла разработчиков, ищущих миграции БД в гибких средах. Объем данных и схемы могут быть трудно изменить. Перезапись большого набора данных, хранящегося на диске, при одновременном сохранении связанных приложений в сети может занять много времени. Для обновления данных могут потребоваться дни фоновой обработки (в умеренных и больших примерах).
Фон
Большинство традиционных механизмов реляционных баз данных теперь поддерживают JSON. С SQL Server 2016 легко обмениваться данными JSON между приложениями и ядром базы данных. Microsoft предоставила различные функции и возможности для анализа данных JSON. Они пытались перенести данные JSON в реляционное хранилище. Он также обеспечивает возможность преобразования реляционных данных в данные JSON и JSON в денормализованные данные.
Наличие этих дополнительных функций JSON, встроенных в SQL Server, должно упростить для приложений обмен данными JSON с SQL Server. Эта функциональность обеспечивает гибкость интеграции данных JSON в ядро реляционной базы данных. Разработчики могут писать и изобретать сложные запросы на своих периодических этапах процесса разработки.
Реляционные базы данных относятся к традиционному хранилищу данных, конструктивному и интуитивно понятному языку SQL, разработке сложных запросов и соответствию ACID. NoSQL предлагает разные концепции — сложные структуры помещаются вместе в коллекции сущностей, где вы можете взять все, что вам нужно, с помощью одной операции чтения, или где вы можете вставить сложные структуры с одной записью, следуя теореме CAP.
Реляционные базы данных в некоторой степени нормализуют данные; то есть вместо того, чтобы повторять фрагмент данных в нескольких строках, в таблице, которая нуждается в этой информации, будет храниться внешний ключ, который указывает на другую таблицу, в которой хранятся данные. С другой стороны, этот процесс означает, что данные обычно удаляются из своей первоначальной формы для размещения в таблицах, а затем повторно собираются во время выполнения, объединяя таблицы в ответ на запрос. Это становится особенно дорогим по мере роста набора данных, и данные должны быть распределены между несколькими серверами баз данных.
Синтаксис JSON получен из синтаксиса нотации объектов JavaScript.
- Данные находятся в парах имя / значение. {«Ключ» «значение»} — наиболее распространенный формат для объектов.
- Данные разделяются запятыми. { «Клавиша»»значение»}, { „клавиша“»значение»}.
- Фигурные скобки удерживают объекты. { «Ключ» { «ключ»»значение»}}.
- Квадратные скобки содержат массивы. {«Ключ» [{«ключ» «значение»}, {«ключ» «значение»}]}.
Ценности JSON
В JSON значения должны быть одним из типов данных, указанных ниже.
- Строка
- Число
- Объект (объект JSON)
- Массив
- Логическое значение
- Значение NULL
Если у вас есть отношения родитель / потомок (Fact / Dimension), где связанная дочерняя информация не часто меняется, и вам нужно читать дочерние записи вместе с родителем без дополнительных JOINS, вы можете сохранить дочерние записи в родительской таблице как JSON массив. В традиционных базах данных процесс нормализации обеспечивает дублирование минимизированного объема информации, тогда как в NoSQL он намеренно дублирует ее, чтобы упростить ее использование. Допустим, мы хотим представить количество студентов, посещающих занятия. Нормализованный способ представления данных приведен ниже. Использование массива обозначает данные измерений реляционной таблицы:
{
course "Basic programming",
room "1A",
students[{
id 1,
name "Prashanth"
}, {
id 2,
name "Jayaram"
}]
}Вот денормализованные данные.
[{
course "Basic programming",
room "1A",
studentId 1,
studentName "Prashanth"
}, {
course "Basic programming",
room "1A",
studentId 2,
studentName "Jayaram"
}]
Когда вы анализируете контейнер JSON, вы в конечном итоге получите денормализованные данные в одной таблице.
Давайте обсудим различные измерения приведенных ниже примеров данных и представим данные в виде таблиц и файлов JSON. Кроме того, вы узнаете, как запрашивать файл JSON с различными доступными конструкциями JSON в SQL Server 2016,
Встроенная поддержка JSON в SQL Server 2016 предоставляет вам несколько функций для чтения и анализа строки JSON в реляционном формате.
- OPENJSON (): табличная функция анализирует текст JSON и возвращает представление набора строк JSON.
- JSON_Value (): Скалярная функция возвращает значение из JSON по указанному пути.
Пример выходных данных, приведенный ниже, является примером того, как продемонстрировать различные измерения представления данных в JSON и реляционных данных. В этом примере перечислены родительские и дочерние отношения, и они представлены в виде массива JSON (тесто и топпинг), а также во вложенных объектах.
Представление реляционных данных с использованием FOR JSON
Предложение FOR JSON AUTO аналогично предложению FOR XML AUTO. Он автоматически форматирует вывод JSON на основе иерархии столбцов / таблиц, определенной в запросе SQL . Предложение FOR JSON PATH аналогично предложению FOR XML PATH. Это дает больше возможностей для определения структуры, используя псевдоним столбца с разделителями точек.
Например, давайте создадим пример таблицы «EMP» и «DEPT» и вставим в нее несколько строк:
CREATE TABLE EMP
(EMPNO NUMERIC(4) NOT NULL,
ENAME VARCHAR(10),
JOB VARCHAR(9),
MGR NUMERIC(4),
HIREDATE DATETIME,
SAL NUMERIC(7, 2),
COMM NUMERIC(7, 2),
DEPTNO NUMERIC(2))
INSERT INTO EMP VALUES
(7782, 'CLARK', 'MANAGER', 7839, '9-JUN-1981', 2450, NULL, 10)
INSERT INTO EMP VALUES
(7788, 'SCOTT', 'ANALYST', 7566, '09-DEC-1982', 3000, NULL, 20)
INSERT INTO EMP VALUES
(7839, 'KING', 'PRESIDENT', NULL, '17-NOV-1981', 5000, NULL, 10)
INSERT INTO EMP VALUES
(7844, 'TURNER', 'SALESMAN', 7698, '8-SEP-1981', 1500, 0, 30)
INSERT INTO EMP VALUES
(7934, 'MILLER', 'CLERK', 7782, '23-JAN-1982', 1300, NULL, 10)
(DEPTNO NUMERIC(2),
DNAME VARCHAR(14),
LOC VARCHAR(13) )
INSERT INTO DEPT VALUES (10, 'ACCOUNTING', 'NEW YORK')
INSERT INTO DEPT VALUES (20, 'RESEARCH', 'DALLAS')
INSERT INTO DEPT VALUES (30, 'SALES', 'CHICAGO')
INSERT INTO DEPT VALUES (40, 'OPERATIONS', 'BOSTON')Вывод опции «FOR JSON AUTO» приведен ниже:
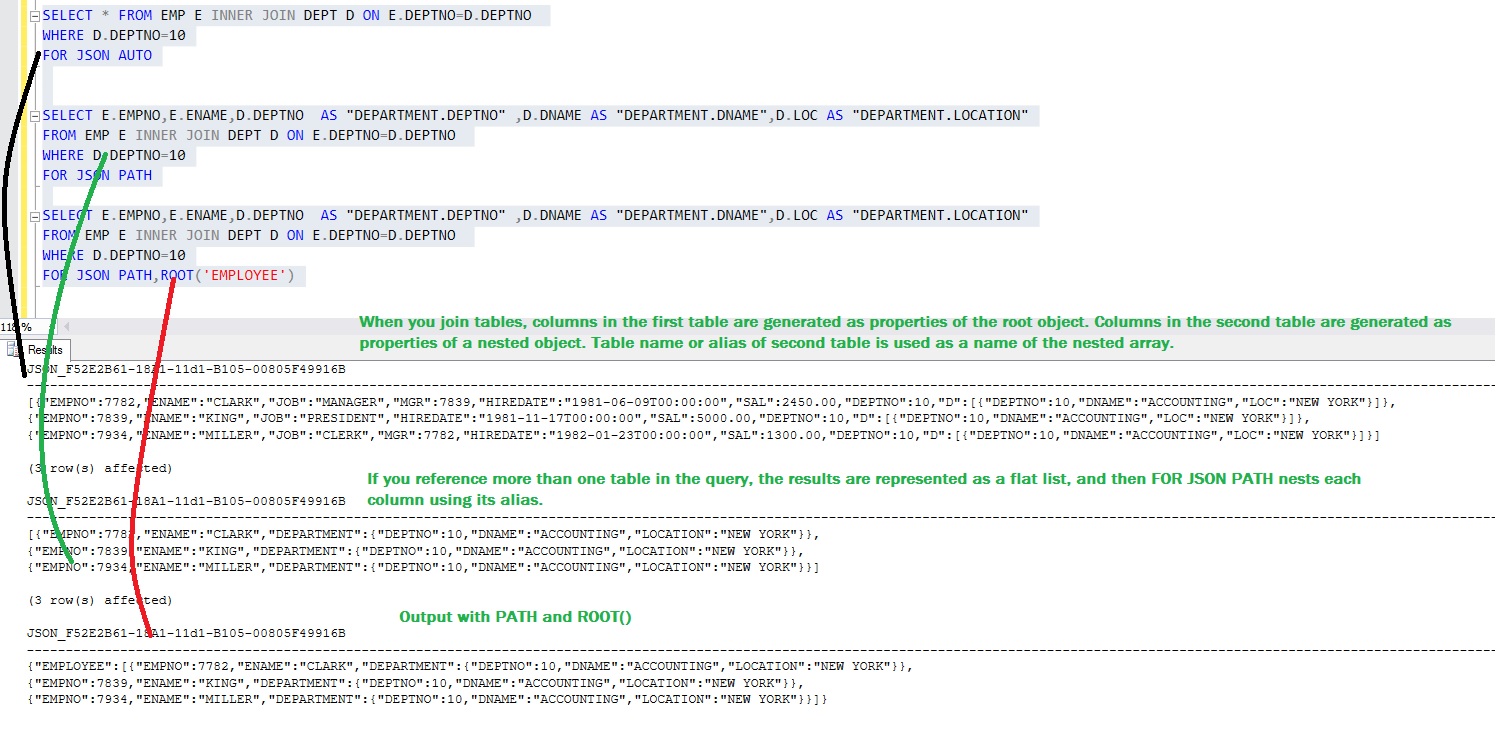
SELECT * FROM EMP E INNER JOIN DEPT D ON E.DEPTNO=D.DEPTNO
WHERE D.DEPTNO=10
FOR JSON AUTOЭта опция автоматически форматирует документ JSON на основе столбцов, указанных в запросе. С опцией FOR JSON PATH синтаксис точки используется для вложенного вывода.
SELECT E.EMPNO,E.ENAME,D.DEPTNO AS "DEPARTMENT.DEPTNO" ,D.DNAME AS "DEPARTMENT.DNAME",D.LOC AS "DEPARTMENT.LOCATION"
FROM EMP E INNER JOIN DEPT D ON E.DEPTNO=D.DEPTNO
WHERE D.DEPTNO=10
FOR JSON PATH
SELECT E.EMPNO,E.ENAME,D.DEPTNO AS "DEPARTMENT.DEPTNO" ,D.DNAME AS "DEPARTMENT.DNAME",D.LOC AS "DEPARTMENT.LOCATION"
FROM EMP E INNER JOIN DEPT D ON E.DEPTNO=D.DEPTNO
WHERE D.DEPTNO=10
FOR JSON PATH,ROOT('EMPLOYEE')Как мы видим, опция PATH создает класс-оболочку ‘Department’ и вкладывает свойства deptno, dname и location.
Давайте преобразуем приведенные ниже примеры данных в JSON:
| 1 | пончик | Кекс | регулярное | Никто |
| 1 | пончик | Кекс | регулярное | глазированный |
| 1 | пончик | Кекс | регулярное | сахар |
| 1 | пончик | Кекс | регулярное | Сахарная пудра |
| 1 | пончик | Кекс | регулярное | Шоколад с окропляет |
| 1 | пончик | Кекс | регулярное | Шоколад |
| 1 | пончик | Кекс | регулярное | кленовый |
| 1 | пончик | Кекс | Шоколад | Никто |
| 1 | пончик | Кекс | Шоколад | глазированный |
| 1 | пончик | Кекс | Шоколад | сахар |
| 1 | пончик | Кекс | Шоколад | Сахарная пудра |
| 1 | пончик | Кекс | Шоколад | Шоколад с окропляет |
| 1 | пончик | Кекс | Шоколад | Шоколад |
| 1 | пончик | Кекс | Шоколад | кленовый |
| 1 | пончик | Кекс | черника | Никто |
| 1 | пончик | Кекс | черника | глазированный |
| 1 | пончик | Кекс | черника | сахар |
| 1 | пончик | Кекс | черника | Сахарная пудра |
| 1 | пончик | Кекс | черника | Шоколад с окропляет |
| 1 | пончик | Кекс | черника | Шоколад |
| 1 | пончик | Кекс | черника | кленовый |
| 1 | пончик | Кекс | Еда дьяволов | Никто |
| 1 | пончик | Кекс | Еда дьяволов | глазированный |
| 1 | пончик | Кекс | Еда дьяволов | сахар |
| 1 | пончик | Кекс | Еда дьяволов | Сахарная пудра |
| 1 | пончик | Кекс | Еда дьяволов | Шоколад с окропляет |
| 1 | пончик | Кекс | Еда дьяволов | Шоколад |
| 1 | пончик | Кекс | Еда дьяволов | кленовый |
Приведенное ниже преобразование содержит вложенные объекты. Как мы видим, добавлено еще несколько записей для идентификатора 0002. В приведенных выше примерах данных мы видим четыре типа теста и семь начинок для приготовления 28 (1 * 4 * 7 = 28) тортов разных типов. Аналогичным образом, для идентификатора 0002 используются четыре типа теста и начинки для приготовления 12 (1 * 4 * 3) видов пирога.
[{
"id": "0001",
"type": "donut",
"name": "Cake",
"ppu": 0.55,
"batters": {
"batter": [{
"id1": "1001",
"type1": "Regular"
}, {
"id1": "1002",
"type1": "Chocolate"
}, {
"id1": "1003",
"type1": "Blueberry"
}, {
"id1": "1004",
"type1": "Devils Food"
}]
},
"topping": [{
"id2": "5001",
"type2": "None"
}, {
"id2": "5002",
"type2": "Glazed"
}, {
"id2": "5005",
"type2": "Sugar"
}, {
"id2": "5007",
"type2": "Powdered Sugar"
}, {
"id2": "5006",
"type2": "Chocolate with Sprinkles"
}, {
"id2": "5003",
"type2": "Chocolate"
}, {
"id2": "5004",
"type2": "Maple"
}]
}, {
"id": "0002",
"type": "donut",
"name": "cup Cake",
"ppu": 0.5,
"batters": {
"batter": [{
"id1": "1001",
"type1": "Regular"
}, {
"id1": "1002",
"type1": "Chocolate"
}, {
"id1": "1003",
"type1": "Blueberry"
}, {
"id1": "1004",
"type1": "Devil's Food"
}]
},
"topping": [{
"id2": "5001",
"type2": "None"
}, {
"id2": "5002",
"type2": "Glazed"
}, {
"id2": "5005",
"type2": "Sugar"
}]
}]
Преобразовать JSON в реляционные данные
OPENJSON is a table-value function (TVF) that looks into JSON text, locates an array of JSON objects, iterates through the elements of the array and, for each element, returns one row in the output result. To read JSON from the file, load the file using the OPENROWSET construct into a variable. Sstocks.json is an example for demonstration. You can derive the path as per your requirements and the environment. In the following example, there’s some SQL code that reads the content of the JSON file, using the OPENROWSET BULK function, and passes the content of JSON file (BulkColumn) to the OPENJSON function
A JSON file can be stored in local file system or globally (cloud storage).
SELECT ID, type, name, ppu, type1 batter, type2 topping FROM
OPENROWSET(BULK N '\\hq6021\c$\stocks.json', SINGLE_CLOB) AS json
CROSS APPLY OPENJSON(BulkColumn)
WITH(id nvarchar(40), type nvarchar(40), name NVARCHAR(MAX), ppu NVARCHAR(MAX), batters NVARCHAR(MAX) AS JSON, topping NVARCHAR(MAX) AS JSON) AS t
CROSS APPLY
OPENJSON(batters, '$.batter')
WITH(id1 nvarchar(100), type1 nvarchar(20))
CROSS APPLY
OPENJSON(topping)
WITH(id2 nvarchar(100), type2 nvarchar(20))
SQL Server 2016 provides the functions for parsing and processing JSON text. The built-in JSON available in SQL Server 2016 are given below.
- ISJSON( jsonText ) checks if the NVARCHAR text is properly formatted according to the JSON specification. You can use this function to create check constraints on NVARCHAR columns, which contains\ JSON text.
- JSON_VALUE( jsonText, path ) parses jsonText and extracts the scalar values on the specified JavaScript-like path (see below for some JSON path examples).
- JSON_QUERY( jsonText, path ) parses jsonText and extracts objects or arrays on the specified JavaScript-like path (see below for some JSON path examples).
These functions use JSON paths for referencing the values or objects in JSON text. JSON paths use JavaScript-like syntax for referencing the properties in JSON text. Some examples are given below.
- ‘$’ – references entire JSON objects in the input text.
- ‘$.property1’ – references property1 in JSON objects.
- ‘$[4]’ – references the fifth element in JSON array (indexes are counted from 0 like in JavaScript).
- ‘$.property1.property2.array1[5].property3.array2[15].property4’ – references a complex nested property in the JSON object.
- ‘$.info. “first name”‘ – references “first name” property in info object. If the key contains some special characters such as space, dollar, etc., it should be surrounded by double quotes.
The dollar sign ($) represents the input JSON object (similar to root “/” in XPath language). You can add any JavaScript-like property or an array after “$” to reference properties in JSON objects. One simple example of a query, where these built-in functions are used is given below.
DECLARE @MyJSON NVARCHAR(4000) = N '{
"info" {
"type"
1, "address" {
"town"
"Louisville", "county"
"Boulder", "country"
"USA"
}, "tags" ["Snow", "Breweries"]
}, "LocationType"
"East", "WeatherType"
"Cold"
}
'
Select * from OPENJSON(@MyJSON)
WITH(type int '$.info.type', LocationType varchar(20)
'$.LocationType', WeatherType varchar(20)
'$.WeatherType', town varchar(200)
'$.info.address.town', county varchar(200)
'$.info.address.county', country varchar(200)
'$.info.address.country') AS t
CROSS APPLY
OPENJSON(@MyJSON, '$.info.tags')
How to Define Nested Objects in JSON
The examples given above also contain sample data that represents nested objects.
DECLARE @json NVARCHAR(1000)
SELECT @json = N '{
"Employee" [{
"Element"
1
}, {
"Element"
2
}, {
"Element"
"n"
}]
}
'In the employee example given below, the employeeDepartment is the root of the JSON. The array element DEPT has dimension data, which represents the department details of each employee. The employee JSON structure has three objects.
DECLARE @MyJSON NVARCHAR(4000) = N '{
"EmployeeDepartment": [{
"EmployeeID": "E0001",
"FirstName": "Prashanth",
"LastName": "Jayaram",
"DOB": "1983-02-03",
"DEPT": [{
"EmployeeDepartment": "Ducks"
}, {
"EmployeeDepartment": "Blues"
}]
}, {
"EmployeeID": "E0002",
"FirstName": "Prarthana",
"LastName": "Prashanth",
"DOB": "2015-07-06",
"DEPT": [{
"EmployeeDepartment": "Red Wings"
}]
}, {
"EmployeeID": "E0003",
"FirstName": "Pravitha",
"LastName": "Prashanth",
"DOB": "2015-07-06",
"DEPT": [{
"EmployeeDepartment": "Red Wings"
}, {
"EmployeeDepartment": "Green Bird"
}]
}]
}
'
--SELECT * FROM OPENJSON(@MyJSON)
SELECT
EmployeeID,
FirstName,
LastName,
DOB,
DEPT,
EmployeeDepartment
FROM OPENJSON(@MyJSON, '$.EmployeeDepartment')
WITH(EmployeeID varchar(10), FirstName varchar(25), LastName varchar(25), DOB varchar(25), DEPT NVARCHAR(MAX) AS JSON) AS E
CROSS APPLY
OPENJSON(DEPT)
WITH(EmployeeDepartment nvarchar(100))
Reading JSON Into Separate Rows
How about pulling them into separate rows using JSON_Value() with the OPENJSON() function. The query given below gives an overview of applying the JSON constructs on the nested elements.
DECLARE @MyJSON NVARCHAR(4000) = N '{
"EmployeeDepartment": [{
"EmployeeID": "E0001",
"FirstName": "Prashanth",
"LastName": "Jayaram",
"DOB": "1983-02-03",
"DEPT": [{
"DeptID": "D1",
"DName": "Ducks"
}, {
"DeptID": "D2",
"DName": "Blues"
}]
}, {
"EmployeeID": "E0002",
"FirstName": "Prarthana",
"LastName": "Prashanth",
"DOB": "2015-07-06",
"DEPT": [{
"DeptID": "D3",
"DName": "Red Wings"
}]
}, {
"EmployeeID": "E0003",
"FirstName": "Pravitha",
"LastName": "Prashanth",
"DOB": "2015-07-06",
"DEPT": [{
"DeptID": "D3",
"DName": "Red Wings"
}, {
"DeptID": "D4",
"DName": "Green Bird"
}]
}]
}
'
SELECT
JSON_Value(c.value, '$.EmployeeID') as EmployeeID,
JSON_Value(c.value, '$.FirstName') as FirstName,
JSON_Value(C.value, '$.DOB') as DOB,
JSON_Value(p.value, '$.DeptID') as DEPTID,
JSON_Value(p.value, '$.DName') as DName
FROM OPENJSON(@MyJSON, '$.EmployeeDepartment') as c
CROSS APPLY OPENJSON(c.value, '$.DEPT') as p
You can specify the child elements with the full path by using the dollar sign “$” inside the WITH() clause to segregate the data into the separate columns.
DECLARE @MyJSON NVARCHAR(4000) = N '{
"EmployeeDepartment": [{
"EmployeeID": "E0001",
"FirstName": "Prashanth",
"LastName": "Jayaram",
"DOB": "1983-02-03",
"DEPT": [{
"DeptID": "D1",
"DName": "Ducks"
}, {
"DeptID": "D2",
"DName": "Blues"
}]
}, {
"EmployeeID": "E0002",
"FirstName": "Prarthana",
"LastName": "Prashanth",
"DOB": "2015-07-06",
"DEPT": [{
"DeptID": "D3",
"DName": "Red Wings"
}]
}, {
"EmployeeID": "E0003",
"FirstName": "Pravitha",
"LastName": "Prashanth",
"DOB": "2015-07-06",
"DEPT": [{
"DeptID": "D3",
"DName": "Red Wings"
}, {
"DeptID": "D4",
"DName": "Green Bird"
}]
}]
}
'
SELECT
EmployeeID,
FirstName,
DOB,
Dept1, DName1,
Dept2, DName2
FROM OPENJSON(@MyJSON, '$.EmployeeDepartment')
WITH(EmployeeID varchar(20)
'$.EmployeeID', FirstName varchar(20)
'$.FirstName', DOB varchar(20)
'$.DOB', Dept1 varchar(20)
'$.DEPT[0].DeptID', Dname1 varchar(20)
'$.DEPT[0].DName', Dept2 varchar(20)
'$.DEPT[1].DeptID', Dname2 varchar(20)
'$.DEPT[1].DName') AS EMP
Conclusion
SQL 2016 contains some very powerful JSON constructs. Mixing the power of relational databases with the flexibility of JSON offers many benefits for migration, integration, and deployment. It is flexible because of the simple syntax and the relatively little overhead needed to maintain and manage the JSON data. The powerful JSON SQL constructs enable us to query and analyze JSON data as well as transform JSON to relational data and relational data to JSON.
There are plenty of examples and resources available under various links. This is an effort to combine real-world scenarios and details the various ways of JSON data manipulation, using SQL 2016 JSON constructs. NoSQL offers different concepts — complex structures are placed together into the collections of the entities, where you can take everything you need with one read operation or where you can insert complex structures with a single write. The bad side is that sometimes you want to organize your information in different collections, and then you will find that it is very hard to JOIN entities from the two collections.
With newest version of SQL Server, you have options to choose between these two concepts and use the best of both worlds. In your data models, you can choose when to use traditional relational structures and when to introduce NoSQL concepts.