Вступление
Splunk представляет собой платформу для обработки машинных данных из различных источников, таких как веб-журналы, системные журналы, журналы log4j, а также может работать с форматами файлов JSON и CSV, поэтому любое приложение, которое создает выходные данные JSON или CSV, можно рассматривать как источник для Splunk. По мере увеличения объема и разнообразия машинных данных Splunk становится все более и более интересным игроком в мире больших данных. Splunk можно рассматривать как
поисковик для данных ИТ . Splunk собирает данные из нескольких источников, индексирует их, и пользователи могут искать их, используя собственный язык Splunk, называемый SPL (язык обработки поиска). Результаты поиска могут затем использоваться для создания отчетов и информационных панелей для визуализации данных.
Splunk Architecture
В архитектуре Splunk есть следующие ключевые компоненты: —
серверы пересылки используются для пересылки данных в экземпляры приемника Splunk. Экземпляры получателя обычно являются индексаторами. —
индексаторы, которые являются дополнительными экземплярами для индексации данных. Индексы хранятся в файлах. Есть два типа файлов; необработанные файлы данных, которые хранят данные в сжатом формате, и индексные файлы, содержащие метаданные для поисковых запросов. Во время индексирования Splunk извлекает поля по умолчанию и идентифицирует события на основе меток времени или создает их, если метка времени не найдена. —
поиск головы и поиск сверстников . В распределенной среде поисковый руководитель управляет поисковыми запросами, направляет их поисковым партнерам и затем объединяет результаты с пользователями. —
Splunk Web графический интерфейс пользователя на основе сервера приложений Python

Splunk Storm
Splunk Storm — это версия Splunk для облачного сервиса. Splunk Storm работает в облаке Amazon и использует как Elastic Block Storage (EBS), так и Simple Storage Service (S3). Ценовой план основан на ежемесячной плате, он зависит от объема данных, которые вы хотите хранить. На момент написания этой статьи существует бесплатный уровень с хранилищем 1 ГБ, например, объем хранилища 100 ГБ стоит 400 долларов США, а максимальный объем хранилища 1 ТБ — 3000 долларов США в месяц. Для начала нам нужно зарегистрироваться и создать проект.
 Затем мы можем определить входные данные. Существует четыре варианта: загрузить файл, использовать серверы пересылки, использовать API (он пока находится в бета-версии) или использовать данные сети, отправленные непосредственно с серверов. В качестве первого теста мы будем использовать файлы данных, загруженные из локального каталога. Мы использовали пример apache web access.log и системный журнал, доступный по адресу
Затем мы можем определить входные данные. Существует четыре варианта: загрузить файл, использовать серверы пересылки, использовать API (он пока находится в бета-версии) или использовать данные сети, отправленные непосредственно с серверов. В качестве первого теста мы будем использовать файлы данных, загруженные из локального каталога. Мы использовали пример apache web access.log и системный журнал, доступный по адресу
http://www.monitorware.com/en/logsamples/ Индексация файлов занимает некоторое время, а затем они становятся доступными для поисковых запросов.
 Мы можем запустить поисковый запрос, чтобы определить все коды ошибок на стороне клиента HTTP:
Мы можем запустить поисковый запрос, чтобы определить все коды ошибок на стороне клиента HTTP:
"source="access_log.txt" status>="400" AND status <="500"
 Если мы хотим идентифицировать все записи в журнале доступа методом HTTP POST, мы можем запустить следующий поисковый запрос:
Если мы хотим идентифицировать все записи в журнале доступа методом HTTP POST, мы можем запустить следующий поисковый запрос:
source="access_log.txt" method="POST"
Аналогичным образом, если мы хотим найти все сообщения из загруженного файла системного журнала, сгенерированные процессом ядра, мы можем выполнить следующий запрос:
source="syslog-messages.txt" process="kernel"

Splunk forwarder и Twitter API
В качестве следующего примера мы хотим протестировать вывод, сгенерированный нашей программой с использованием Twitter API. Программа сгенерирует формат JSON в файле, используя API-интерфейс Twitter на основе Python. За каталогом следит сервер пересылки Splunk, и как только файл создается в предопределенном каталоге, сервер пересылки отправляет его в Splunk Storm. Сначала нам нужно создать приложение в Twitter через
портал https: //dev/twitter.com . Приложение будет иметь свои customer_key, customer_secret, access_token_key и access_token_secret, которые потребуются API Twitter.
 API Twitter, который мы собираемся использовать для приложения Python, можно загрузить с Github,
API Twitter, который мы собираемся использовать для приложения Python, можно загрузить с Github,
https://github.com/bear/python-twitter.git., Этот API зависит от oauth2, simplejson и httplib2, поэтому нам нужно сначала установить их. Затем мы можем получить код от Github и собрать и установить пакет.
$ git clone https://github.com/bear/python-twitter.git # Build and Install: $ python setup.py build $ python setup.py install
Код приложения Twitter — twtr.py — выглядит следующим образом:
# twtr.py import sys import twitter if len(sys.argv) < 3: print "Usage: " + sys.argv[0] + " keyword count" sys.exit(1) keyword = sys.argv[1] count = sys.argv[2] # Twitter API 1.1. Count - up to a maximum of 100 # https://dev.twitter.com/docs/api/1.1/get/search/tweets if int(count) > 100: count = 100 api = twitter.Api(consumer_key="CONSUMER_KEY", consumer_secret="CONSUMER_SECRET", access_token_key="ACCESS_TOKEN_KEY", access_token_secret="4PXvz7QIiwtwhFrFXFEkc9wY7iBOdgusD8ZQLvUhabM" ) search_result = api.GetSearch(term=keyword, count=count) for s in search_result: print s.AsJsonString()
Программу Python можно запустить следующим образом:
$ python twtr.py "big data" 100
Установка Splunk форвардер
Затем нам нужно установить сервер пересылки Splunk, см.
Http://www.splunk.com/download/universalforwarder . Нам также необходимо загрузить учетные данные Splunk, которые позволят серверу пересылки отправлять данные в наш проект. После того как сервер пересылки и учетные данные установлены, мы можем войти в систему и добавить каталог (twitter_status) для отслеживания нашего сервера пересылки. Мы определили тип источника как json_notimestamp.
# Download splunk forwarder $ wget -O splunkforwarder-5.0.3-163460-Linux-x86_64.tgz 'http://www.splunk.com/page/download_track?file=5.0.3/universalforwarder/linux/splunkforwarder-5.0.3-163460-Linux-x86_64.tgz&ac=&wget=true&name=wget&typed=releases&elq=8ccba442-db76-4fc8-b36b-36252bb61257' # Install and start splunk forwarder $ tar xvzf splunkforwarder-5.0.3-163460-Linux-x86_64.tgz $ export SPLUNK_HOME=/home/ec2-user/splunkforwarder $ $SPLUNK_HOME/bin/splunk start # Install project credentials $ $SPLUNK_HOME/bin/splunk install app ./stormforwarder_2628fbc8d76811e2b09622000a1cdcf0.spl -auth admin:changeme App '/home/ec2-user/stormforwarder_2628fbc8d76811e2b09622000a1cdcf0.spl' installed # Login $SPLUNK_HOME/bin/splunk login -auth admin:changeme #' Add monitor (directory or file) $SPLUNK_HOME/bin/splunk add monitor /home/ec2-user/splunk_blog/twitter_status -sourcetype json_no_timestamp Added monitor of '/home/ec2-user/splunk_blog/twitter_status'.
Теперь мы готовы запустить код Python с помощью Twitter API:
$ python twtr.py "big data" 100 | tee twitter_status/twitter_status.txt
Программа создает файл twitter_status.txt в каталоге twitter_status, который отслеживается средством пересылки Splunk. Экспедитор отправляет выходной файл в Splunk Storm. Через некоторое время он будет отображаться под разделами ввода как аутентифицированный экспедитор. Файл будет показан как источник вместе с ранее загруженным журналом доступа Apache и системным журналом.
Если мы хотим искать пользователей с местоположением Лондон, поисковый запрос выглядит следующим образом:


source="/home/ec2-user/splunk_blog/twitter_status/twitter_status.txt" user.location="London, UK"
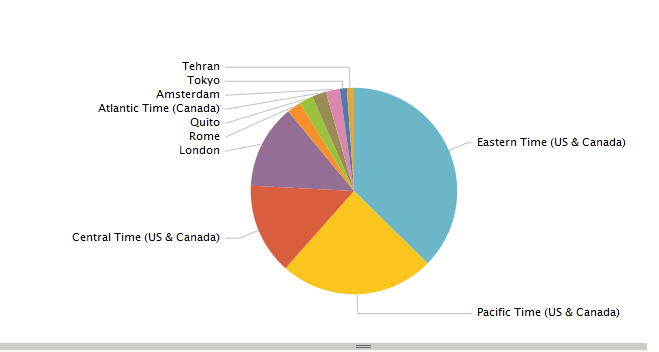
Мы также можем определить поисковый запрос, чтобы отобразить 10 лучших часовых поясов из результатов Twitter, а из результатов поиска легко создать отчет с помощью нескольких щелчков мыши в веб-интерфейсе пользователя. Отчет позволяет выбрать несколько вариантов визуализации, таких как столбцы, области или типы круговых диаграмм и т. Д.
source="/home/ec2-user/splunk_blog/twitter_status/twitter_status.txt" | top limit=10 user.time_zone

Вывод
Как упоминалось в начале этой статьи, разнообразие и объем, генерируемый машинами, резко увеличиваются; данные датчиков, журналы приложений, журналы веб-доступа, системные журналы, журналы аудита базы данных и файловой системы — это лишь несколько примеров потенциальных источников данных, которые требуют внимания, но могут создавать трудности для их своевременной обработки и анализа. Splunk — отличный инструмент для работы с постоянно растущим объемом данных, и пользователи Splunk Storm могут без проблем начать анализировать свои данные в облаке.