В своем последнем посте я писал о сортировке файлов в Linux. При таком подходе можно довольно быстро отсортировать большие файлы (в десятках ГБ). Но что, если ваши файлы уже находятся в HDFS или имеют размер в сотни ГБ или больше? В этом случае имеет смысл использовать MapReduce и использовать ресурсы кластера для параллельной сортировки данных.
MapReduce следует рассматривать как вездесущий инструмент сортировки, так как при проектировании он сортирует все выходные записи карты (используя ключи вывода карты), так что все записи, которые достигают одного редуктора, сортируются. На приведенной ниже схеме показано, как работает фаза тасования в MapReduce.
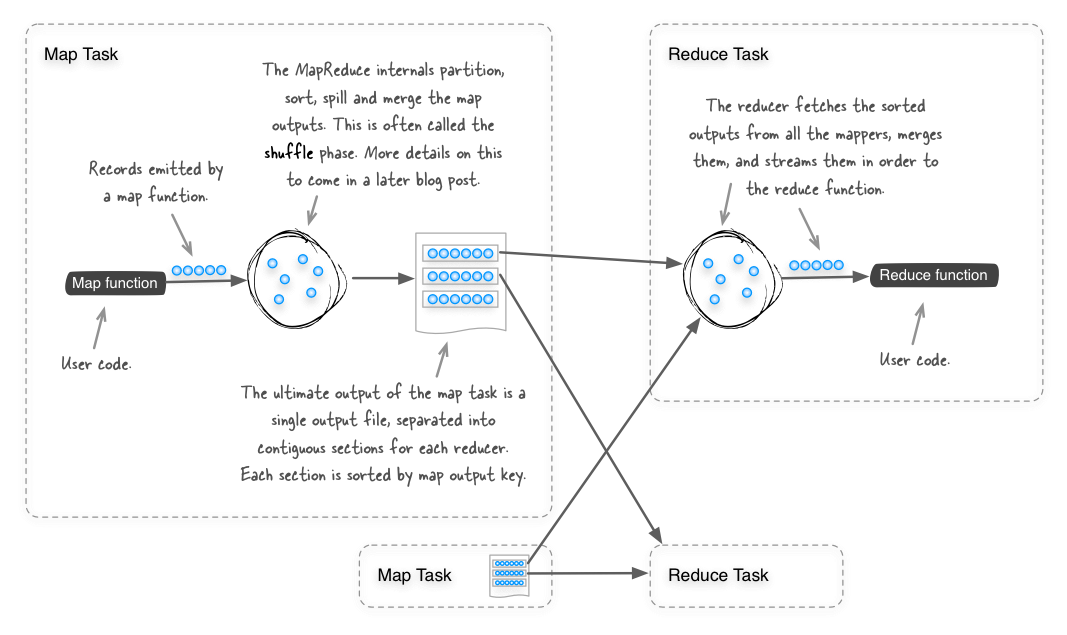
Учитывая, что MapReduce уже выполняет сортировку между картой и фазами сокращения, тогда сортировка файлов может быть выполнена с помощью функции идентификации (той, где входные данные для карты и фазы сокращения генерируются напрямую). Это фактически то, что делает пример сортировки , связанный с Hadoop. Вы можете посмотреть, как работает пример кода, изучив класс org.apache.hadoop.examples.Sort . Чтобы использовать этот пример кода для сортировки текстовых файлов в Hadoop, вы должны использовать его следующим образом:
shell$ export HADOOP_HOME=/usr/lib/hadoop
shell$ $HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-examples.jar sort \
-inFormat org.apache.hadoop.mapred.KeyValueTextInputFormat \
-outFormat org.apache.hadoop.mapred.TextOutputFormat \
-outKey org.apache.hadoop.io.Text \
-outValue org.apache.hadoop.io.Text \
/hdfs/path/to/input \
/hdfs/path/to/outputЭто хорошо работает, но не предлагает некоторые функции, на которые я обычно полагаюсь при сортировке Linux, такие как сортировка по определенному столбцу и сортировка без учета регистра.
Linux-esque сортировка в MapReduce
Я запустил новый репозиторий GitHub под названием hadoop-utils , где я планирую создавать полезные вспомогательные классы и утилиты. Первый — это гибкая сортировка Hadoop. Та же самая примерная сортировка Hadoop может быть выполнена с помощью сортировки hadoop-utils следующим образом:
shell$ $HADOOP_HOME/bin/hadoop jar hadoop-utils-<version>-jar-with-dependencies.jar \
com.alexholmes.hadooputils.sort.Sort \
/hdfs/path/to/input \
/hdfs/path/to/outputДовести сортировка в MapReduce ближе к Linux рода, то --key и --field-separator параметры могут быть использованы , чтобы указать один или несколько столбцов , которые должны быть использованы для сортировки, а также пользовательский разделитель (пробел по умолчанию). Например, представьте, что у вас есть файл в HDFS с именем /input/300names.txt и фамилией:
shell$ hadoop fs -cat 300names.txt | head -n 5
Roy Franklin
Mario Gardner
Willis Romero
Max Wilkerson
Latoya LarsonЧтобы отсортировать по фамилии, которую вы запустите:
shell$ $HADOOP_HOME/bin/hadoop jar hadoop-utils-<version>-jar-with-dependencies.jar \
com.alexholmes.hadooputils.sort.Sort \
--key 2 \
/input/300names.txt \
/hdfs/path/to/outputСинтаксис --key : POS1[,POS2]где первая позиция (POS1) требуется, а вторая позиция (POS2) является необязательной — если она опущена, то POS1 для сортировки используется остальная часть строки. Так же, как сортировка Linux, --key основывается на 1, так что --key 2 в приведенном выше примере сортировка будет осуществляться по второму столбцу в файле.
Интеграция LZOP
Еще одна хитрость этой утилиты сортировки — ее тесная интеграция с LZOP, полезным кодеком сжатия, который хорошо работает с большими файлами в MapReduce ( более подробную информацию о LZOP смотрите в главе 5 Hadoop на практике ). Он может работать с входными файлами LZOP, которые охватывают несколько разбиений, а также может сжимать выходные данные LZOP и даже создавать индексные файлы LZOP. Вы бы сделать это с codec и lzop-index вариантами:
shell$ $HADOOP_HOME/bin/hadoop jar hadoop-utils-<version>-jar-with-dependencies.jar \
com.alexholmes.hadooputils.sort.Sort \
--key 2 \
--codec com.hadoop.compression.lzo.LzopCodec \
--map-codec com.hadoop.compression.lzo.LzoCodec \
--lzop-index \
/hdfs/path/to/input \
/hdfs/path/to/outputНесколько редукторов и общий порядок
Если ваше задание сортировки выполняется с несколькими редукторами (либо потому, что mapreduce.job.reduces в параметре in mapred-site.xml было указано число больше 1, либо потому, что вы использовали -r опцию для указания количества редукторов в командной строке), то по умолчанию Hadoop будет использовать HashPartitioner для распределения записей по редукторам. Использование HashPartitioner означает, что вы не можете объединить ваши выходные файлы для создания одного отсортированного выходного файла. Для этого вам понадобится полное упорядочение , которое поддерживается как в примере сортировки Hadoop, так и в сортировке hadoop-utils — сортировка hadoop-utils позволяет сделать это с помощью --total-order опции.
shell$ $HADOOP_HOME/bin/hadoop jar hadoop-utils-<version>-jar-with-dependencies.jar \
com.alexholmes.hadooputils.sort.Sort \
--total-order 0.1 10000 10 \
/hdfs/path/to/input \
/hdfs/path/to/outputСинтаксис этой опции не интуитивен, поэтому давайте посмотрим, что означает каждое поле.
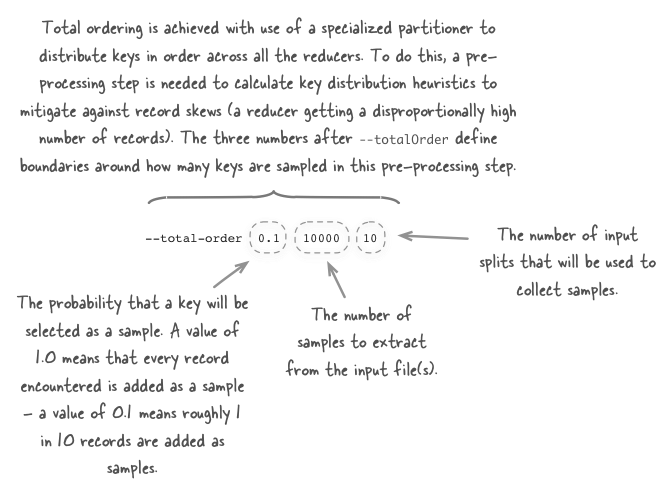
Более подробную информацию о полном порядке можно увидеть в главе 4 Hadoop на практике .
Подробнее
Для получения подробной информации о том, как загрузить и запустить сортировку hadoop-utils, посмотрите руководство по CLI на странице проекта GitHub .