Мы очень рады объявить гостя после серии на блоге jOOQ по Мануэль Бернхард . В этой серии блогов Мануэль расскажет о мотивах так называемых реактивных технологий и после представления концепций фьючерсов и актеров использует их для доступа к реляционной базе данных в сочетании с jOOQ.
 Мануэль Бернхардт (Manuel Bernhardt) — независимый консультант по программному обеспечению со страстью к созданию веб-систем, как внутренних, так и внешних. Он является автором «Реактивных веб-приложений» (Мэннинг) и начал работать со Scala, Akka и Play Framework в 2010 году, проведя много времени с Java. Он живет в Вене, где он является соорганизатором местной группы пользователей Scala . Он с энтузиазмом относится к технологиям, основанным на Scala, и к активному сообществу, и ищет способы распространения их использования в отрасли. С 6 лет он также занимается подводным плаванием и не может привыкнуть к отсутствию моря в Австрии.
Мануэль Бернхардт (Manuel Bernhardt) — независимый консультант по программному обеспечению со страстью к созданию веб-систем, как внутренних, так и внешних. Он является автором «Реактивных веб-приложений» (Мэннинг) и начал работать со Scala, Akka и Play Framework в 2010 году, проведя много времени с Java. Он живет в Вене, где он является соорганизатором местной группы пользователей Scala . Он с энтузиазмом относится к технологиям, основанным на Scala, и к активному сообществу, и ищет способы распространения их использования в отрасли. С 6 лет он также занимается подводным плаванием и не может привыкнуть к отсутствию моря в Австрии.
Эта серия разделена на три части, которые мы опубликуем в следующем месяце:
- Часть 1. Введение в Futures, «Почему асинхронно», настройка пула соединений
- Часть 2: Введение в актеров
- Часть 3: Использование jOOQ со Scala, Futures и Actors
Реактивная?
Концепция реактивных приложений становится все более популярной в наши дни, и есть вероятность, что вы уже слышали об этом где-то в Интернете. Если нет, вы можете прочитать « Реактивный манифест» или, возможно, мы согласимся со следующим простым резюме. Короче говоря, Reactive Applications — это приложения, которые:
- Оптимально использовать вычислительные ресурсы (с точки зрения использования процессора и памяти), используя методы асинхронного программирования
- Знать, как справляться со сбоями, грациозно деградируя, а не просто рушиться и становясь недоступным для своих пользователей
- Может адаптироваться к интенсивным рабочим нагрузкам, масштабируясь на нескольких машинах / узлах при увеличении нагрузки (и уменьшая обратно)
Реактивные Приложения не существуют просто в диком, нетронутом зеленом поле. В какой-то момент им нужно будет хранить данные и получать к ним доступ, чтобы сделать что-то значимое, и есть вероятность, что данные окажутся в реляционной базе данных.
Задержка и доступ к базе данных
Когда приложение обращается к базе данных, чаще всего сервер базы данных не будет работать на том же сервере, что и приложение. Если вам не повезло, возможно, даже сервер (или набор серверов), на котором размещено приложение, находится в другом центре обработки данных, чем сервер базы данных. Вот что это означает с точки зрения задержки :
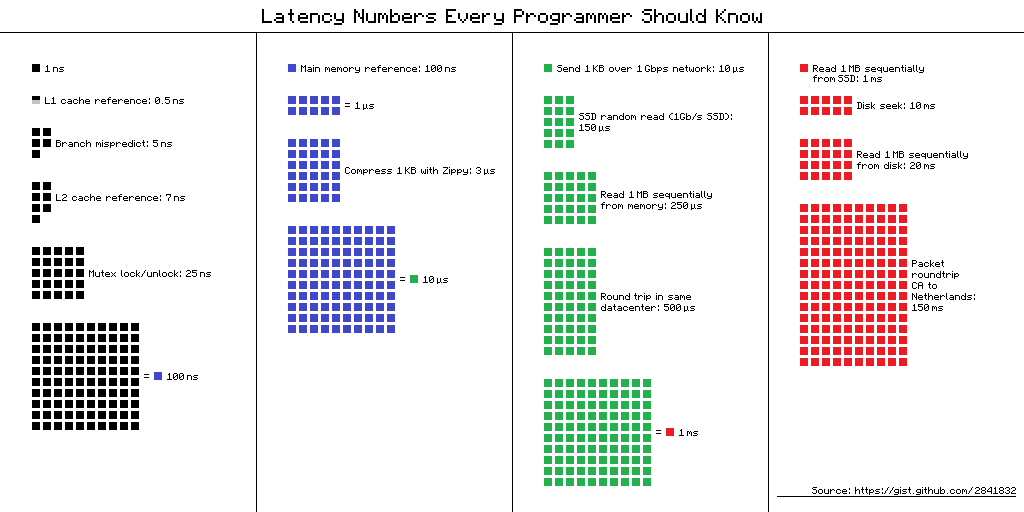
Скажем, у вас есть приложение, которое выполняет простой SELECT запрос на своей главной странице (давайте не будем спорить, является ли это хорошей идеей здесь). Если ваши серверы приложений и баз данных находятся в одном и том же центре обработки данных, вы видите задержку порядка 500 мкс (в зависимости от того, сколько данных возвращается). Теперь сравните это со всем, что ваш процессор мог сделать за это время (все эти зеленые и черные квадраты на рисунке выше), и помните об этом — мы вернемся к этому через минуту.
Стоимость нитей
Предположим, что вы выполняете запрос страницы приветствия синхронно (именно это делает JDBC) и ждете, пока результат вернется из базы данных. В течение всего этого времени вы будете монополизировать поток, который ожидает возвращения результата. Поток Java, который просто существует (вообще ничего не делая), может занять до 1 МБ динамической памяти, поэтому, если вы используете многопоточный сервер, который будет выделять один поток на пользователя (я смотрю на вас, Tomcat), то это в ваших же интересах иметь достаточное количество памяти, доступной для вашего приложения, чтобы оно все еще работало, когда оно включено в Hacker News (1 МБ / параллельный пользователь).
Реактивные приложения, такие как созданные с использованием Play Framework, используют сервер, который следует модели четного сервера : вместо того, чтобы следовать мантре «один пользователь, один поток», он будет обрабатывать запросы как набор событий (доступ к базе данных будет одно из этих событий) и выполните его через цикл событий:
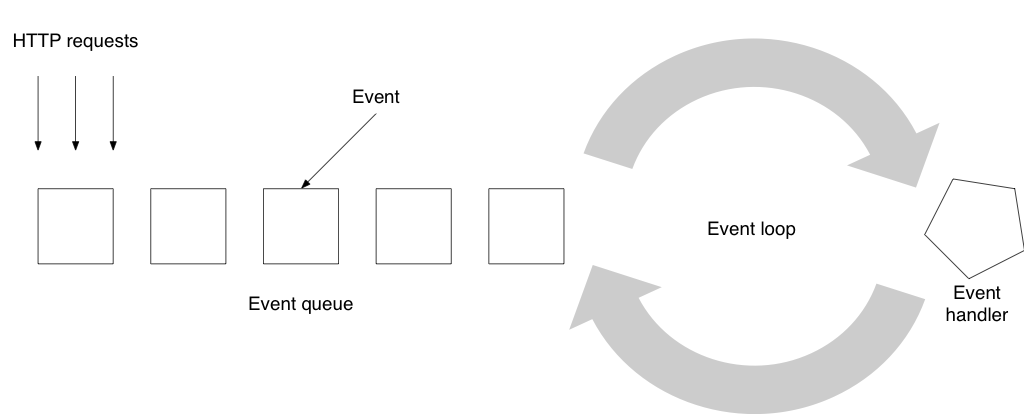
Такой сервер не будет использовать много потоков. Например, конфигурация Play Framework по умолчанию заключается в создании одного потока на ядро ЦП с максимум 24 потоками в пуле. И все же этот тип серверной модели может обрабатывать гораздо больше параллельных запросов, чем многопоточная модель с тем же аппаратным обеспечением. Хитрость, как выясняется, заключается в том, чтобы передать поток другим событиям, когда задача должна сделать некоторое ожидание — или другими словами: программировать в асинхронном режиме.
Болезненное асинхронное программирование
Асинхронное программирование не является чем-то новым, и парадигмы программирования для его решения существуют с 70-х годов и с тех пор постепенно развивались. И все же асинхронное программирование — это не обязательно то, что возвращает счастливые воспоминания большинству разработчиков. Давайте рассмотрим несколько типичных инструментов и их недостатки.
Callbacks
Некоторые языки (я смотрю на вас, Javascript) застряли в 70-х годах с обратными вызовами как их единственным инструментом для асинхронного программирования до недавнего времени (ECMAScript 6 представил Promises). Это также известно как программирование рождественской елки :

Хо Хо Хо .
Потоки
Как разработчик Java, слово асинхронный не обязательно имеет очень позитивный смысл и часто ассоциируется с печально известным synchronized ключевым словом:
95% синхронизированного кода не работает. Остальные 5% написаны Брайаном Гетцем. — Венкат Субраманиам в # s2gx
— Ронни Лёвтанген (@rlovtangen) 26 октября 2011 г.
Работать с потоками в Java сложно, особенно при использовании изменяемого состояния — гораздо удобнее позволить базовому серверу приложений абстрагировать все асинхронные компоненты и не беспокоиться об этом, верно? К сожалению, как мы только что видели, это довольно дорого с точки зрения производительности.
И я имею в виду, просто посмотрите на эту трассировку стека:
In one way, threaded servers are to asynchronous programming what Hibernate is to SQL, a leaky abstraction that will cost you dearly in the long run. And once you realize it, it is often too late and you are trapped in your abstraction, fighting by all means against it in order to increase performance. Whilst for database access, it is relatively easy to let go of the abstraction (just use plain SQL, or even better, jOOQ), for asynchronous programming the better tooling is only starting to gain in popularity.
Let’s turn to a programming model that finds its roots in functional programming: Futures.
Futures: the SQL of Asynchronous Programming
Futures, as they can be found in Scala, leverage functional programming techniques that have been around for decades in order to make asynchronous programming enjoyable again.
Future Fundamentals
A scala.concurrent.Future[T] can be seen as a box that will eventually contain a value of type T if it succeeds. If it fails, theThrowable at the origin of the failure will be kept. A Future is said to have succeeded once the computation it is waiting for has yielded a result, or failed if there was an error during the computation. In either case, once the Future is done computing, it is said to be completed.
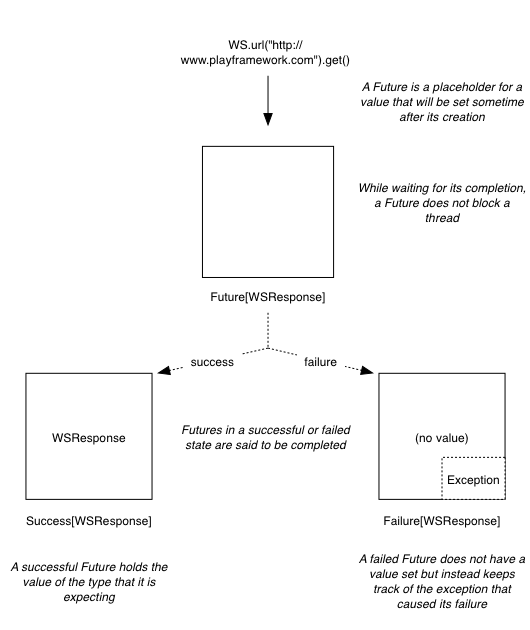
As soon as a Future is declared, it will start running, which means that the computation it tries to achieve will be executed asynchronously. For example, we can use the WS library of the Play Framework in order to execute a GET request against the Play Framework website:
val response: Future[WSResponse] =
WS.url("http://www.playframework.com").get()This call will return immediately and lets us continue to do other things. At some point in the future, the call may have been executed, in which case we could access the result to do something with it. Unlike Java’sjava.util.concurrent.Future<V>which lets one check whether a Future is done or block while retrieving it with the get() method, Scala’s Future makes it possible to specify what to do with the result of an execution.
Transforming Futures
Manipulating what’s inside of the box is easy as well, and we do not need to wait for the result to be available in order to do so:
val response: Future[WSResponse] =
WS.url("http://www.playframework.com").get()
val siteOnline: Future[Boolean] =
response.map { r =>
r.status == 200
}
siteOnline.foreach { isOnline =>
if(isOnline) {
println("The Play site is up")
} else {
println("The Play site is down")
}
}
In this example, we turn our Future[WSResponse] into a Future[Boolean] by checking for the status of the response. It is important to understand that this code will not block at any point: only when the response becomes available will a thread be made available for the processing of the response and execute the code inside of the map function.
Recovering Failed Futures
Failure recovery is quite convenient as well:
val response: Future[WSResponse] =
WS.url("http://www.playframework.com").get()
val siteAvailable: Future[Option[Boolean]] =
response.map { r =>
Some(r.status == 200)
} recover {
case ce: java.net.ConnectException => None
}At the very end of the Future we call the recover method which will deal with a certain type of exception and limit the damage. In this example we are only handling the unfortunate case of a java.net.ConnectException by returning a Nonevalue.
Composing Futures
The killer feature of Futures is their composeability. A very typical use-case when building asynchronous programming workflows is to combine the results of several concurrent operations. Futures (and Scala) make this rather easy:
def siteAvailable(url: String): Future[Boolean] =
WS.url(url).get().map { r =>
r.status == 200
}
val playSiteAvailable =
siteAvailable("http://www.playframework.com")
val playGithubAvailable =
siteAvailable("https://github.com/playframework")
val allSitesAvailable: Future[Boolean] = for {
siteAvailable <- playSiteAvailable
githubAvailable <- playGithubAvailable
} yield (siteAvailable && githubAvailable)The allSitesAvailable Future is built using a for comprehension which will wait until both Futures have completed. The two Futures playSiteAvailable andplayGithubAvailable will start running as soon as they are being declared and the for comprehension will compose them together. And, if one of those Futures were to fail, the resulting Future[Boolean] would fail directly as a result (without waiting for the other Future to complete).
This is it for the first part of this series. In the next post we will look at another tool for reactive programming and then finally at how to use those tools in combination in order to access a relational database in a reactive fashion.
Read On
Stay tuned as we’ll publish Parts 2 and 3 shortly as a part of this series:
- Part 1: Introduction to Futures, “Why async”, connection pool configuration
- Part 2: Introduction to Actors
- Part 3: Using jOOQ with Scala, Futures and Actors
This article was written by Manuel Bernhardt.