В предыдущей статье « Разработка собственного фильтра Solr » мы показали, как реализовать простой фильтр и как использовать его в Apache Solr. Недавно один из наших читателей спросил, можем ли мы расширить тему и показать, как записать более одного токена в поток токенов. Мы решили пойти на это и расширить предыдущую запись в блоге о реализации фильтра.
Предположения
Давайте предположим, что мы хотим не только вернуть перевернутое слово, но и сохранить оригинальное. Так что, если бы мы передать прекрасное слово для анализа мы хотели бы иметь штраф и ените freturned. Для этого мы изменим фильтр, созданный в предыдущей записи.
Мы опускаем все детали конфигурации и установки, поэтому, если вы хотите прочитать о них, пожалуйста, обратитесь к предыдущему посту.
Версия Solr
Мы также хотели бы отметить, что в этом посте мы решили использовать новейшую версию Solr, поэтому мы использовали 4.1 . Чтобы следующий фильтр работал на 3.6, просто использовали фабрику фильтров, показанную в предыдущей записи.
Завод фильтров
Единственная разница, когда дело доходит до фабрики фильтров, это класс, который мы расширяем. Поскольку мы используем Solr 4.1, мы расширяем TokenFilterFactory из пакета org.apache.lucene.analysis.util :
public class ReverseFilterFactory extends TokenFilterFactory {
@Override
public TokenStream create(TokenStream ts) {
return new ReverseFilter(ts);
}
}
Фильтр
Фильтр был немного изменен и выглядит так:
public final class ReverseFilter extends TokenFilter {
private CharTermAttribute charTermAttr;
private PositionIncrementAttribute posIncAttr;
private Queue<char[]> terms;
protected ReverseFilter(TokenStream ts) {
super(ts);
this.charTermAttr = addAttribute(CharTermAttribute.class);
this.posIncAttr = addAttribute(PositionIncrementAttribute.class);
this.terms = new LinkedList<char[]>();
}
@Override
public boolean incrementToken() throws IOException {
if (!terms.isEmpty()) {
char[] buffer = terms.poll();
charTermAttr.setEmpty();
charTermAttr.copyBuffer(buffer, 0, buffer.length);
posIncAttr.setPositionIncrement(1);
return true;
}
if (!input.incrementToken()) {
return false;
} else {
// we reverse the token
int length = charTermAttr.length();
char[] buffer = charTermAttr.buffer();
char[] newBuffer = new char[length];
for (int i = 0; i < length; i++) {
newBuffer[i] = buffer[length - 1 - i];
}
// we place the new buffer in the terms list
terms.add(newBuffer);
// we return true and leave the original token unchanged
return true;
}
}
}
Описание реализации
Давайте поговорим о различиях между вышеупомянутым фильтром и версией, показанной в предыдущем сообщении в блоге:
- Строка 4 — список, который будет использоваться для хранения буфера терминов, который должен быть записан в поток токенов.
- Строка 9 — мы добавляем атрибут, который отвечает за установку положения токена в потоке токенов.
- Строка 10 — инициализация списка, который мы определили в строке 4.
- Строка 15 — 21 — условие, которое проверяет, есть ли у нас токены в списках, которые нам нужно обработать. Если есть такие токены, мы берем первый токен из списка (и удаляем его), мы устанавливаем термин «буфер», мы устанавливаем его позицию в потоке токенов и возвращаем true , чтобы сообщить, что обработка должна быть продолжена. Стоит отметить, что мы не получили новый токен из потока токенов, потому что мы не вызывали метод input.incrementToken () .
- Строки 23 — 25 — мы проверяем, остались ли токены для обработки. Если нет, мы просто возвращаем false и заканчиваем обработку.
- Строки 27 — 36 — мы обращаем токен и добавляем его в список, объявленный в строке 4. Мы не изменили токен, который фактически присутствует в токене, и возвращаем true . Сделав это, мы сообщаем Solr, что хотим продолжить обработку, и Solr должен вызвать метод incrementToken () нашего фильтра. После следующего вызова мы закончим выполнение кода из строк 15 — 21, потому что наш список будет содержать новый токен.
На наш взгляд, стоит отметить еще одну вещь — атрибут приращения позиции. В описанной выше реализации каждый обратный токен будет записан в следующей позиции в потоке токенов по сравнению с исходным токеном. Проще говоря — эти токены будут рассматриваться как отдельные слова. В нескольких из них мы проверим, что произойдет, когда обращенные токены будут размещены в тех же позициях, что и исходные.
Это работает ?
Работу указанного фильтра можно проиллюстрировать с помощью панели администрирования Solr:
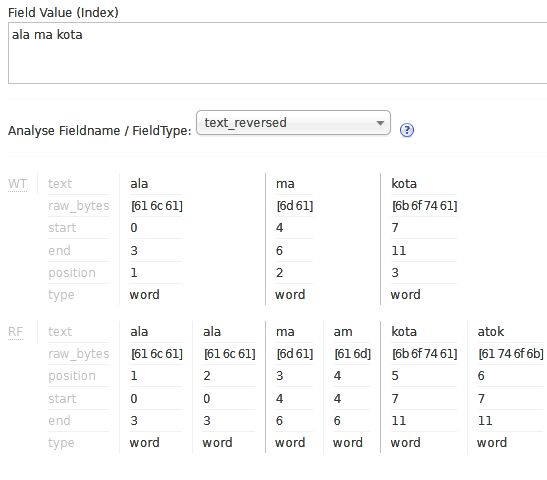
Как вы можете видеть, оба исходных значения: ala , ma и kota и перевернутые значения ala , am и atok были установлены в новых позициях ( атрибут position ). Так что работает как задумано
Давайте изменим приращение позиции
Итак, давайте проверим, что произойдет, когда мы изменим следующую строку:
1 |
posIncAttr.setPositionIncrement(1); |
на следующий:
1 |
posIncAttr.setPositionIncrement(0); |
Как это работает
Опять же, давайте проиллюстрируем, как это работает, посмотрев на панель администрирования Solr:
 Как видите, после изменения как оригинальный токен, так и его обратная версия были поставлены в одну и ту же позицию, чего мы и хотели достичь. Благодаря этому теперь мы можем запускать запросы типа q = ”ala am kota” (посмотрите на слово am ). Что мы получаем, так это возможность использовать оригинальные или обращенные токены в запросах фраз.
Как видите, после изменения как оригинальный токен, так и его обратная версия были поставлены в одну и ту же позицию, чего мы и хотели достичь. Благодаря этому теперь мы можем запускать запросы типа q = ”ala am kota” (посмотрите на слово am ). Что мы получаем, так это возможность использовать оригинальные или обращенные токены в запросах фраз.
Подводить итоги
Как вы можете видеть, создание собственных фильтров — это не ракетостроение, по крайней мере, когда речь идет о Lucene и Solr. То, что мы получаем от Lucene и Solr, — это хороший набор функций, которые мы можем использовать для управления тем, что будет окончательно помещено в поток токенов, например, благодаря атрибутам потока токенов. Конечно, сложность кода будет зависеть от вашей бизнес-логики, но это далеко выходит за рамки этого поста. 